Editor’s note: This piece was written in collaboration with SwitchUp, an online platform for researching and reviewing technology learning programs. Erica Freedman is a Content Specialist at SwitchUp.
John Mount speaking on rquery and rqdatatable
rquery and rqdatatable are new R packages for data wrangling; either at scale (in databases, or big data systems such as Apache Spark), or in-memory. The packages speed up both execution (through optimizations) and development (though a good mental model and up-front error checking) for data wrangling tasks.
Do Bayesians Overfit?
TLDR: Yes, and there are precise results, although they are not as well known as they perhaps should be.
BD reviews
I read BD’s (bandes dessinées or, as we say in English, graphic literature or picture storybooks) to keep up with my French. Regular books are too difficult for me. When it comes to BDs, some of the classic kids strips and albums are charming, but the ones for adults, which are more like Hollywood movies, are easier for me to read because I find the stories more compelling: I want to find out what happens next.
Exercise and weight loss: long-term follow-up
This post is by Phil Price, not Andrew.
He wants to model a proportion given some predictors that sum to 1
Joël Gombin writes:
Top-Down vs. Bottom-Up Approaches to Data Science
Data projects are generally organized in one of two ways: top-down (that is, starting with the business question) or bottom-up (starting with the data and working up to insights). But is there a “right way,” and is one approach better or more effective than the other?
Using Siamese Networks and Pre-Trained Convolutional Neural Networks (CNNs) for Fashion Similarity Matching
This post is co-authored by Erika Menezes, Software Engineer at Microsoft, and Chaitanya Kanitkar, Software Engineer at Twitter. This project was completed as part of the coursework for Stanford’s CS231n in Spring 2018.
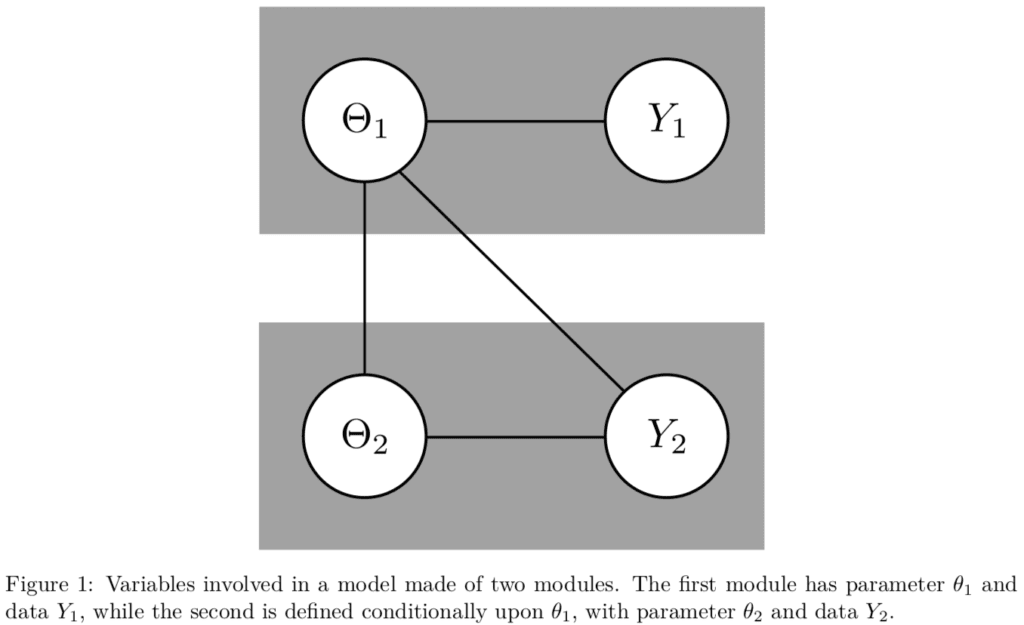
Joint inference or modular inference? Pierre Jacob, Lawrence Murray, Chris Holmes, Christian Robert discuss conditions on the strength and weaknesses of these choices