Deep Autoencoder for Recommender Systems: Parameter Influence Analysis
Recommender systems have recently attracted many researchers in the deep learning community. The state-of-the-art deep neural network models used in recommender systems are typically multilayer perceptron and deep Autoencoder (DAE), among which DAE usually shows better performance due to its superior capability to reconstruct the inputs. However, we found existing DAE recommendation systems that have similar implementations on similar datasets result in vastly different parameter settings. In this work, we have built a flexible DAE model, named FlexEncoder that uses configurable parameters and unique features to analyse the parameter influences on the prediction accuracy of recommender systems. This will help us identify the best-performance parameters given a dataset. Extensive evaluation on the MovieLens datasets are conducted, which drives our conclusions on the influences of DAE parameters. Specifically, we find that DAE parameters strongly affect the prediction accuracy of the recommender systems, and the effect is transferable to similar datasets in a larger size. We open our code to public which could benefit both new users for DAE — they can quickly understand how DAE works for recommendation systems, and experienced DAE users — it easier for them to tune the parameters on different datasets.
KI, Philosophie, Logik
This is a short (and personal) introduction in German to the connections between artificial intelligence, philosophy, and logic, and to the author’s work. Dies ist eine kurze (und persoenliche) Einfuehrung in die Zusammenhaenge zwischen Kuenstlicher Intelligenz, Philosophie, und Logik, und in die Arbeiten des Autors.
Discrete Neural Processes
Many data generating processes involve latent random variables over discrete combinatorial spaces whose size grows factorially with the dataset. In these settings, existing posterior inference methods can be inaccurate and/or very slow. In this work we develop methods for efficient amortized approximate Bayesian inference over discrete combinatorial spaces, with applications to random permutations, probabilistic clustering (such as Dirichlet process mixture models) and random communities (such as stochastic block models). The approach is based on mapping distributed, symmetry-invariant representations of discrete arrangements into conditional probabilities. The resulting algorithms parallelize easily, yield iid samples from the approximate posteriors, and can easily be applied to both conjugate and non-conjugate models, as training only requires samples from the generative model.
Nash Equilibria on (Un)Stable Networks
While individuals may selfishly choose their optimal behaviors (Nash, 1950), they commit to relationships that result from communication, coordination, and cooperation (Jackson and Wolinsky, 1996). In games of friendship links and behaviors, a Nash equilibrium in k-stable network (NEkSN) emerges when players internalize the consensual nature of human relationships. The joint choice of behaviors and relationships may result in a multitude of equilibria, ranked in probabilistic sense as these equilibria arise in a k-player consensual dynamic (kCD). Application of the proposed framework to adolescents’ tobacco smoking and friendship decisions suggests that: (a.) the response of the friendship network to changes in tobacco price amplifies the intended effect on smoking, (b.) racially desegregating high-schools decreases the overall smoking prevalence, (c.) the response of the social network is quantitatively important in analyzing the aggregate spillovers, (d.) the estimation biases when the network externalities are mis-specified and when peer effects are omitted are of the same sign.
Sentence-Level Sentiment Analysis of Financial News Using Distributed Text Representations and Multi-Instance Learning
Researchers and financial professionals require robust computerized tools that allow users to rapidly operationalize and assess the semantic textual content in financial news. However, existing methods commonly work at the document-level while deeper insights into the actual structure and the sentiment of individual sentences remain blurred. As a result, investors are required to apply the utmost attention and detailed, domain-specific knowledge in order to assess the information on a fine-grained basis. To facilitate this manual process, this paper proposes the use of distributed text representations and multi-instance learning to transfer information from the document-level to the sentence-level. Compared to alternative approaches, this method features superior predictive performance while preserving context and interpretability. Our analysis of a manually-labeled dataset yields a predictive accuracy of up to 69.90%, exceeding the performance of alternative approaches by at least 3.80 percentage points. Accordingly, this study not only benefits investors with regard to their financial decision-making, but also helps companies to communicate their messages as intended.
Private Information Retrieval from Non-Replicated Databases

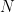

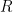
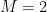


Convex Relaxations of Convolutional Neural Nets
We propose convex relaxations for convolutional neural nets with one hidden layer where the output weights are fixed. For convex activation functions such as rectified linear units, the relaxations are convex second order cone programs which can be solved very efficiently. We prove that the relaxation recovers the global minimum under a planted model assumption, given sufficiently many training samples from a Gaussian distribution. We also identify a phase transition phenomenon in recovering the global minimum for the relaxation.
Dynamic Space-Time Scheduling for GPU Inference
Serving deep neural networks in latency critical interactive settings often requires GPU acceleration. However, the small batch sizes typical in online inference results in poor GPU utilization, a potential performance gap which GPU resource sharing can address. In this paper, we explore several techniques to leverage both temporal and spatial multiplexing to improve GPU utilization for deep learning inference workloads. We evaluate the performance trade-offs of each approach with respect to resource-efficiency, latency predictability, and isolation when compared with conventional batched inference. Our experimental analysis suggests up to a 5x potential for improved utilization through the exploration of more advanced spatial and temporal multiplexing strategies. Our preliminary prototype of a dynamic space-time scheduler demonstrates a 3.23x floating-point throughput increase over space-only multiplexing and a 7.73x increase over time-only multiplexing for convolutions, while also providing better isolation and latency predictability.
The Stochastic Complexity of Principal Component Analysis
PCA (principal component analysis) and its variants are ubiquitous techniques for matrix dimension reduction and reduced-dimension latent-factor extraction. For an arbitrary matrix, they cannot, on their own, determine the size of the reduced dimension, but rather must be given this as an input. NML (normalized maximum likelihood) is a universal implementation of the Minimal Description Length principle, which gives an objective compression-based criterion for model selection. This work applies NML to PCA. A direct attempt to do so would involve the distributions of singular values of random matrices, which is difficult. A reduction to linear regression with a noisy unitary covariate matrix, however, allows finding closed-form bounds on the NML of PCA.
Impossibility and Uncertainty Theorems in AI Value Alignment (or why your AGI should not have a utility function)
Utility functions or their equivalents (value functions, objective functions, loss functions, reward functions, preference orderings) are a central tool in most current machine learning systems. These mechanisms for defining goals and guiding optimization run into practical and conceptual difficulty when there are independent, multi-dimensional objectives that need to be pursued simultaneously and cannot be reduced to each other. Ethicists have proved several impossibility theorems that stem from this origin; those results appear to show that there is no way of formally specifying what it means for an outcome to be good for a population without violating strong human ethical intuitions (in such cases, the objective function is a social welfare function). We argue that this is a practical problem for any machine learning system (such as medical decision support systems or autonomous weapons) or rigidly rule-based bureaucracy that will make high stakes decisions about human lives: such systems should not use objective functions in the strict mathematical sense. We explore the alternative of using uncertain objectives, represented for instance as partially ordered preferences, or as probability distributions over total orders. We show that previously known impossibility theorems can be transformed into uncertainty theorems in both of those settings, and prove lower bounds on how much uncertainty is implied by the impossibility results. We close by proposing two conjectures about the relationship between uncertainty in objectives and severe unintended consequences from AI systems.
Improving Tree-LSTM with Tree Attention
In Natural Language Processing (NLP), we often need to extract information from tree topology. Sentence structure can be represented via a dependency tree or a constituency tree structure. For this reason, a variant of LSTMs, named Tree-LSTM, was proposed to work on tree topology. In this paper, we design a generalized attention framework for both dependency and constituency trees by encoding variants of decomposable attention inside a Tree-LSTM cell. We evaluated our models on a semantic relatedness task and achieved notable results compared to Tree-LSTM based methods with no attention as well as other neural and non-neural methods and good results compared to Tree-LSTM based methods with attention.
Recurrent Neural Networks for Time Series Forecasting
Time series forecasting is difficult. It is difficult even for recurrent neural networks with their inherent ability to learn sequentiality. This article presents a recurrent neural network based time series forecasting framework covering feature engineering, feature importances, point and interval predictions, and forecast evaluation. The description of the method is followed by an empirical study using both LSTM and GRU networks.
Dense Morphological Network: An Universal Function Approximator
Artificial neural networks are built on the basic operation of linear combination and non-linear activation function. Theoretically this structure can approximate any continuous function with three layer architecture. But in practice learning the parameters of such network can be hard. Also the choice of activation function can greatly impact the performance of the network. In this paper we are proposing to replace the basic linear combination operation with non-linear operations that do away with the need of additional non-linear activation function. To this end we are proposing the use of elementary morphological operations (dilation and erosion) as the basic operation in neurons. We show that these networks (Denoted as DenMo-Net) with morphological operations can approximate any smooth function requiring less number of parameters than what is necessary for normal neural networks. The results show that our network perform favorably when compared with similar structured network.
An Active Learning Framework for Efficient Robust Policy Search
Robust Policy Search is the problem of learning policies that do not degrade in performance when subject to unseen environment model parameters. It is particularly relevant for transferring policies learned in a simulation environment to the real world. Several existing approaches involve sampling large batches of trajectories which reflect the differences in various possible environments, and then selecting some subset of these to learn robust policies, such as the ones that result in the worst performance. We propose an active learning based framework, EffAcTS, to selectively choose model parameters for this purpose so as to collect only as much data as necessary to select such a subset. We apply this framework to an existing method, namely EPOpt, and experimentally validate the gains in sample efficiency and the performance of our approach on standard continuous control tasks. We also present a Multi-Task Learning perspective to the problem of Robust Policy Search, and draw connections from our proposed framework to existing work on Multi-Task Learning.
FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review
Due to recent advances in digital technologies, and availability of credible data, an area of artificial intelligence, deep learning, has emerged, and has demonstrated its ability and effectiveness in solving complex learning problems not possible before. In particular, convolution neural networks (CNNs) have demonstrated their effectiveness in image detection and recognition applications. However, they require intensive CPU operations and memory bandwidth that make general CPUs fail to achieve desired performance levels. Consequently, hardware accelerators that use application specific integrated circuits (ASICs), field programmable gate arrays (FPGAs), and graphic processing units (GPUs) have been employed to improve the throughput of CNNs. More precisely, FPGAs have been recently adopted for accelerating the implementation of deep learning networks due to their ability to maximize parallelism as well as due to their energy efficiency. In this paper, we review recent existing techniques for accelerating deep learning networks on FPGAs. We highlight the key features employed by the various techniques for improving the acceleration performance. In addition, we provide recommendations for enhancing the utilization of FPGAs for CNNs acceleration. The techniques investigated in this paper represent the recent trends in FPGA-based accelerators of deep learning networks. Thus, this review is expected to direct the future advances on efficient hardware accelerators and to be useful for deep learning researchers.
MaD: Mapping and debugging framework for implementing deep neural network onto a neuromorphic chip with crossbar array of synapses
Neuromorphic systems or dedicated hardware for neuromorphic computing is getting popular with the advancement in research on different device materials for synapses, especially in crossbar architecture and also algorithms specific or compatible to neuromorphic hardware. Hence, an automated mapping of any deep neural network onto the neuromorphic chip with crossbar array of synapses and an efficient debugging framework is very essential. Here, mapping is defined as the deployment of a section of deep neural network layer onto a neuromorphic core and the generation of connection lists among population of neurons to specify the connectivity between various neuromorphic cores on the neuromorphic chip. Debugging is the verification of computations performed on the neuromorphic chip during inferencing. Together the framework becomes Mapping and Debugging (MaD) framework. MaD framework is quite general in usage as it is a Python wrapper which can be integrated with almost every simulator tools for neuromorphic chips. This paper illustrates the MaD framework in detail, considering some optimizations while mapping onto a single neuromorphic core. A classification task on MNIST and CIFAR-10 datasets are considered for test case implementation of MaD framework.
Realizing data features by deep nets
This paper considers the power of deep neural networks (deep nets for short) in realizing data features. Based on refined covering number estimates, we find that, to realize some complex data features, deep nets can improve the performances of shallow neural networks (shallow nets for short) without requiring additional capacity costs. This verifies the advantage of deep nets in realizing complex features. On the other hand, to realize some simple data feature like the smoothness, we prove that, up to a logarithmic factor, the approximation rate of deep nets is asymptotically identical to that of shallow nets, provided that the depth is fixed. This exhibits a limitation of deep nets in realizing simple features.
A Theoretical Analysis of Deep Q-Learning
Despite the great empirical success of deep reinforcement learning, its theoretical foundation is less well understood. In this work, we make the first attempt to theoretically understand the deep Q-network (DQN) algorithm (Mnih et al., 2015) from both algorithmic and statistical perspectives. In specific, we focus on a slight simplification of DQN that fully captures its key features. Under mild assumptions, we establish the algorithmic and statistical rates of convergence for the action-value functions of the iterative policy sequence obtained by DQN. In particular, the statistical error characterizes the bias and variance that arise from approximating the action-value function using deep neural network, while the algorithmic error converges to zero at a geometric rate. As a byproduct, our analysis provides justifications for the techniques of experience replay and target network, which are crucial to the empirical success of DQN. Furthermore, as a simple extension of DQN, we propose the Minimax-DQN algorithm for zero-sum Markov game with two players. Borrowing the analysis of DQN, we also quantify the difference between the policies obtained by Minimax-DQN and the Nash equilibrium of the Markov game in terms of both the algorithmic and statistical rates of convergence.
Monte Carlo Fusion
This paper proposes a new theory and methodology to tackle the problem of unifying distributed analyses and inferences on shared parameters from multiple sources, into a single coherent inference. This surprisingly challenging problem arises in many settings (for instance, expert elicitation, multi-view learning, distributed ‘big data’ problems etc.), but to-date the framework and methodology proposed in this paper (Monte Carlo Fusion) is the first general approach which avoids any form of approximation error in obtaining the unified inference. In this paper we focus on the key theoretical underpinnings of this new methodology, and simple (direct) Monte Carlo interpretations of the theory. There is considerable scope to tailor the theory introduced in this paper to particular application settings (such as the big data setting), construct efficient parallelised schemes, understand the approximation and computational efficiencies of other such unification paradigms, and explore new theoretical and methodological directions.
Adaptive Quantile Low-Rank Matrix Factorization

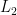
Parallel Algorithm for Time Series Discords Discovery on the Intel Xeon Phi Knights Landing Many-core Processor
Discord is a refinement of the concept of anomalous subsequence of a time series. The task of discords discovery is applied in a wide range of subject domains related to time series: medicine, economics, climate modeling, etc. In this paper, we propose a novel parallel algorithm for discords discovery for the Intel Xeon Phi Knights Landing (KNL) many-core systems for the case when input data fit in main memory. The algorithm exploits the ability to independently calculate Euclidean distances between the subsequences of the time series. Computations are paralleled through OpenMP technology. The algorithm consists of two stages, namely precomputations and discovery. At the precomputations stage, we construct the auxiliary matrix data structures, which ensure efficient vectorization of computations on Intel Xeon Phi KNL. At the discovery stage, the algorithm finds discord based upon the structures above. Experimental evaluation confirms the high scalability of the developed algorithm.
Depth for curve data and applications
John W. Tukey (1975) defined statistical data depth as a function that determines centrality of an arbitrary point with respect to a data cloud or to a probability measure. During the last decades, this seminal idea of data depth evolved into a powerful tool proving to be useful in various fields of science. Recently, extending the notion of data depth to the functional setting attracted a lot of attention among theoretical and applied statisticians. We go further and suggest a notion of data depth suitable for data represented as curves, or trajectories, which is independent of the parametrization. We show that our curve depth satisfies theoretical requirements of general depth functions that are meaningful for trajectories. We apply our methodology to diffusion tensor brain images and also to pattern recognition of hand written digits and letters. Supplementary materials are available online.
Complementary reinforcement learning toward explainable agents
Reinforcement learning (RL) algorithms allow agents to learn skills and strategies to perform complex tasks without detailed instructions or expensive labelled training examples. That is, RL agents can learn, as we learn. Given the importance of learning in our intelligence, RL has been thought to be one of key components to general artificial intelligence, and recent breakthroughs in deep reinforcement learning suggest that neural networks (NN) are natural platforms for RL agents. However, despite the efficiency and versatility of NN-based RL agents, their decision-making remains incomprehensible, reducing their utilities. To deploy RL into a wider range of applications, it is imperative to develop explainable NN-based RL agents. Here, we propose a method to derive a secondary comprehensible agent from a NN-based RL agent, whose decision-makings are based on simple rules. Our empirical evaluation of this secondary agent’s performance supports the possibility of building a comprehensible and transparent agent using a NN-based RL agent.
Like this:
Like Loading…
Related