Smart Information Spreading for Opinion Maximization in Social Networks
The goal of opinion maximization is to maximize the positive view towards a product, an ideology or any entity among the individuals in social networks. So far, opinion maximization is mainly studied as finding a set of influential nodes for fast content dissemination in a social network. In this paper, we propose a novel approach to solve the problem, where opinion maximization is achieved through efficient information spreading. In our model, multiple sources inject information continuously into the network, while the regular nodes with heterogeneous social learning abilities spread the information to their acquaintances through gossip mechanism. One of the sources employs smart information spreading and the rest spread information randomly. We model the social interactions and evolution of opinions as a dynamic Bayesian network (DBN), using which the opinion maximization is formulated as a sequential decision problem. Since the problem is intractable, we develop multiple variants of centralized and decentralized learning algorithms to obtain approximate solutions. Through simulations in synthetic and real-world networks, we demonstrate two key results: 1) the proposed methods perform better than random spreading by a large margin, and 2) even though the smart source (that spreads the desired content) is unfavorably located in the network, it can outperform the contending random sources located at favorable positions.
Tighter Problem-Dependent Regret Bounds in Reinforcement Learning without Domain Knowledge using Value Function Bounds

A weighted random survival forest
A weighted random survival forest is presented in the paper. It can be regarded as a modification of the random forest improving its performance. The main idea underlying the proposed model is to replace the standard procedure of averaging used for estimation of the random survival forest hazard function by weighted avaraging where the weights are assigned to every tree and can be veiwed as training paremeters which are computed in an optimal way by solving a standard quadratic optimization problem maximizing Harrell’s C-index. Numerical examples with real data illustrate the outperformance of the proposed model in comparison with the original random survival forest.
Clustering with Distributed Data

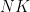
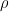
Multitask Learning Deep Neural Network to Combine Revealed and Stated Preference Data
It is an enduring question how to combine revealed preference (RP) and stated preference (SP) data to analyze travel behavior. This study presents a new approach of using multitask learning deep neural network (MTLDNN) to combine RP and SP data and incorporate the traditional nest logit approach as a special case. Based on a combined RP and SP survey in Singapore to examine the demand for autonomous vehicles (AV), we designed, estimated and compared one hundred MTLDNN architectures with three major findings. First, the traditional nested logit approach of combining RP and SP can be regarded as a special case of MTLDNN and is only one of a large number of possible MTLDNN architectures, and the nested logit approach imposes the proportional parameter constraint under the MTLDNN framework. Second, out of the 100 MTLDNN models tested, the best one has one shared layer and five domain-specific layers with weak regularization, but the nested logit approach with proportional parameter constraint rivals the best model. Third, the proportional parameter constraint works well in the nested logit model, but is too restrictive for deeper architectures. Overall, this study introduces the MTLDNN model to combine RP and SP data, relates the nested logit approach to the hyperparameter space of MTLDNN, and explores hyperparameter training and architecture design for the joint demand analysis.
Approximate Computation for Big Data Analytics
Over the past a few years, research and development has made significant progresses on big data analytics. A fundamental issue for big data analytics is the efficiency. If the optimal solution is unable to attain or not required or has a price to high to pay, it is reasonable to sacrifice optimality with a `good’ feasible solution that can be computed efficiently. Existing approximation techniques can be in general classified into approximation algorithms, approximate query processing for aggregate SQL queries and approximation computing for multiple layers of the system stack. In this article, we systematically introduce approximate computation, i.e., query approximation and data approximation, for efficiency and effectiveness big data analytics. We first explain the idea and rationale of query approximation, and show efficiency can be obtained with high effectiveness in practice with three analytic tasks: graph pattern matching, trajectory compression and dense subgraph computation. We then explain the idea and rationale of data approximation, and show efficiency can be obtained even without sacrificing for effectiveness in practice with three analytic tasks: shortest paths/distances, network anomaly detection and link prediction.
Opportunistic Learning: Budgeted Cost-Sensitive Learning from Data Streams
In many real-world learning scenarios, features are only acquirable at a cost constrained under a budget. In this paper, we propose a novel approach for cost-sensitive feature acquisition at the prediction-time. The suggested method acquires features incrementally based on a context-aware feature-value function. We formulate the problem in the reinforcement learning paradigm, and introduce a reward function based on the utility of each feature. Specifically, MC dropout sampling is used to measure expected variations of the model uncertainty which is used as a feature-value function. Furthermore, we suggest sharing representations between the class predictor and value function estimator networks. The suggested approach is completely online and is readily applicable to stream learning setups. The solution is evaluated on three different datasets including the well-known MNIST dataset as a benchmark as well as two cost-sensitive datasets: Yahoo Learning to Rank and a dataset in the medical domain for diabetes classification. According to the results, the proposed method is able to efficiently acquire features and make accurate predictions.
Natively Interpretable Machine Learning and Artificial Intelligence: Preliminary Results and Future Directions
Machine learning models have become more and more complex in order to better approximate complex functions. Although fruitful in many domains, the added complexity has come at the cost of model interpretability. The once popular k-nearest neighbors (kNN) approach, which finds and uses the most similar data for reasoning, has received much less attention in recent decades due to numerous problems when compared to other techniques. We show that many of these historical problems with kNN can be overcome, and our contribution has applications not only in machine learning but also in online learning, data synthesis, anomaly detection, model compression, and reinforcement learning, without sacrificing interpretability. We introduce a synthesis between kNN and information theory that we hope will provide a clear path towards models that are innately interpretable and auditable. Through this work we hope to gather interest in combining kNN with information theory as a promising path to fully auditable machine learning and artificial intelligence.
A Survey on Multi-output Learning
Multi-output learning aims to simultaneously predict multiple outputs given an input. It is an important learning problem due to the pressing need for sophisticated decision making in real-world applications. Inspired by big data, the 4Vs characteristics of multi-output imposes a set of challenges to multi-output learning, in terms of the volume, velocity, variety and veracity of the outputs. Increasing number of works in the literature have been devoted to the study of multi-output learning and the development of novel approaches for addressing the challenges encountered. However, it lacks a comprehensive overview on different types of challenges of multi-output learning brought by the characteristics of the multiple outputs and the techniques proposed to overcome the challenges. This paper thus attempts to fill in this gap to provide a comprehensive review on this area. We first introduce different stages of the life cycle of the output labels. Then we present the paradigm on multi-output learning, including its myriads of output structures, definitions of its different sub-problems, model evaluation metrics and popular data repositories used in the study. Subsequently, we review a number of state-of-the-art multi-output learning methods, which are categorized based on the challenges.
Elimination of All Bad Local Minima in Deep Learning
In this paper, we theoretically prove that we can eliminate all suboptimal local minima by adding one neuron per output unit to any deep neural network, for multi-class classification, binary classification, and regression with an arbitrary loss function. At every local minimum of any deep neural network with added neurons, the set of parameters of the original neural network (without added neurons) is guaranteed to be a global minimum of the original neural network. The effects of the added neurons are proven to automatically vanish at every local minimum. Unlike many related results in the literature, our theoretical results are directly applicable to common deep learning tasks because the results only rely on the assumptions that automatically hold in the common tasks. Moreover, we discuss several limitations in eliminating the suboptimal local minima in this manner by providing additional theoretical results and several examples.
openCoT: The opensource Cloud of Things platform
In order to address the complexity and extensiveness of technology, Cloud Computing is utilized with four main service models. The most recent service model, function-as-a-service, enables developers to develop their application in a function-based structure and then deploy it to the Cloud. Using an optimum elastic auto-scaling, the performance of executing an application over FaaS Cloud, overcomes the extra overhead and reduces the total cost. However, researchers need a simple and well-documented FaaS Cloud manager in order to implement their proposed Auto-scaling algorithms. In this paper, we represent the openCoT platform and explain its building blocks and details. Experimental results show that executing a function (invoking and passing arguments) and returning the result using openCoT takes 21 ms over a remote connection. The source code of openCoT is available in the GitHub repository of the project (\code{www.github.com/adanayi/opencot}) for public usage.
The TagRec Framework as a Toolkit for the Development of Tag-Based Recommender Systems
Recommender systems have become important tools to support users in identifying relevant content in an overloaded information space. To ease the development of recommender systems, a number of recommender frameworks have been proposed that serve a wide range of application domains. Our TagRec framework is one of the few examples of an open-source framework tailored towards developing and evaluating tag-based recommender systems. In this paper, we present the current, updated state of TagRec, and we summarize and reflect on four use cases that have been implemented with TagRec: (i) tag recommendations, (ii) resource recommendations, (iii) recommendation evaluation, and (iv) hashtag recommendations. To date, TagRec served the development and/or evaluation process of tag-based recommender systems in two large scale European research projects, which have been described in 17 research papers. Thus, we believe that this work is of interest for both researchers and practitioners of tag-based recommender systems.
Plugin Networks for Inference under Partial Evidence
In this paper, we propose a novel method to incorporate partial evidence in the inference of deep convolutional neural networks. Contrary to the existing methods, which either iteratively modify the input of the network or exploit external label taxonomy to take partial evidence into account, we add separate network modules to the intermediate layers of a pre-trained convolutional network. The goal of those modules is to incorporate additional signal – information about known labels – into the inference procedure and adjust the predicted outputs accordingly. Since the attached ‘Plugin Networks’, have a simple structure consisting of only fully connected layers, we drastically reduce the computational cost of training and inference. At the same time, the proposed architecture allows to propagate the information about known labels directly to the intermediate layers that are trained to intrinsically model correlations between the labels. Extensive evaluation of the proposed method confirms that our Plugin Networks outperform the state-of-the-art in a variety of tasks, including scene categorization and multi-label image annotation.
Modelling the clustering of extreme events for short-term risk assessment
Having reliable estimates of the occurrence rates of extreme events is highly important for insurance companies, government agencies and the general public. The rarity of an extreme event is typically expressed through its return period, i.e., the expected waiting time between events of the observed size if the extreme events of the processes are independent and identically distributed. A major limitation with this measure is when an unexpectedly high number of events occur within the next few months immediately after a \textit{T} year event, with \textit{T} large. Such events undermine the trust in the quality of these risk estimates. The clustering of apparently independent extreme events can occur as a result of local non-stationarity of the process, which can be explained by covariates or random effects. We show how accounting for these covariates and random effects provides more accurate estimates of return levels and aids short-term risk assessment through the use of a new risk measure, which provides evidence of risk which is complementary to the return period.
A Full Probabilistic Model for Yes/No Type Crowdsourcing in Multi-Class Classification
Crowdsourcing has become widely used in supervised scenarios where training sets are scarce and hard to obtain. Most crowdsourcing models in literature assume labelers can provide answers for full questions. In classification contexts, full questions mean that a labeler is asked to discern among all the possible classes. Unfortunately, that discernment is not always easy in realistic scenarios. Labelers may not be experts in differentiating all the classes. In this work, we provide a full probabilistic model for a shorter type of queries. Our shorter queries just required a ‘yes’ or ‘no’ response. Our model estimates a joint posterior distribution of matrices related to the labelers confusions and the posterior probability of the class of every object. We develop an approximate inference approach using Monte Carlo Sampling and Black Box Variational Inference, where we provide the derivation of the necessary gradients. We build two realistic crowdsourcing scenarios to test our model. The first scenario queries for irregular astronomical time-series. The second scenario relies on animal’s image classification. Results show that we can achieve comparable results with full query crowdsourcing. Furthermore, we show that modeling the labelers failures plays an important role in estimating the true classes. Finally, we provide the community with two real datasets obtained from our crowdsourcing experiments. All our code is publicly available (Available at: revealed as soon as the paper gets published.)
Anomaly Detection in Networks with Application to Financial Transaction Networks
This paper is motivated by the task of detecting anomalies in networks of financial transactions, with accounts as nodes and a directed weighted edge between two nodes denoting a money transfer. The weight of the edge is the transaction amount. Examples of anomalies in networks include long paths of large transaction amounts, rings of large payments, and cliques of accounts. There are many methods available which detect such specific structures in networks. Here we introduce a method which is able to detect previously unspecified anomalies in networks. The method is based on a combination of features from network comparison and spectral analysis as well as local statistics, yielding 140 main features. We then use a simple feature sum method, as well as a random forest method, in order to classify nodes as normal or anomalous. We test the method first on synthetic networks which we generated, and second on a set of synthetic networks which were generated without the methods team having access to the ground truth. The first set of synthetic networks was split in a training set of 70 percent of the networks, and a test set of 30 percent of the networks. The resulting classifier was then applied to the second set of synthetic networks. We compare our method with Oddball, a widely used method for anomaly detection in networks, as well as to random classification. While Oddball outperforms random classification, both our feature sum method and our random forest method outperform Oddball. On the test set, the random forest outperforms feature sum, whereas on the second synthetic data set, initially feature sum tends to pick up more anomalies than random forest, with this behaviour reversing for lower-scoring anomalies. In all cases, the top 2 percent of flagged anomalies contained on average over 90 percent of the planted anomalies.
Auditing Pointwise Reliability Subsequent to Training
To use machine learning in high stakes applications (e.g. medicine), we need tools for building confidence in the system and evaluating whether it is reliable. Methods to improve model reliability are often applied at train time (e.g. using Bayesian inference to obtain uncertainty estimates). An alternative is to audit a fixed model subsequent to training. In this paper, we describe resampling uncertainty estimation (RUE), an algorithm to audit the pointwise reliability of predictions. Intuitively, RUE estimates the amount that a single prediction would change if the model had been fit on different training data drawn from the same distribution by using the gradient and Hessian of the model’s loss on training data. Experimentally, we show that RUE more effectively detects inaccurate predictions than existing tools for auditing reliability subsequent to training. We also show that RUE can create predictive distributions that are competitive with state-of-the-art methods like Monte Carlo dropout, probabilistic backpropagation, and deep ensembles, but does not depend on specific algorithms at train-time like these methods do.
Causal Calculus in the Presence of Cycles, Latent Confounders and Selection Bias
We prove the main rules of causal calculus (also called do-calculus) for interventional structural causal models (iSCMs), a generalization of a recently proposed general class of non-/linear structural causal models that allow for cycles, latent confounders and arbitrary probability distributions. We also generalize adjustment criteria and formulas from the acyclic setting to the general one (i.e. iSCMs). Such criteria then allow to estimate (conditional) causal effects from observational data that was (partially) gathered under selection bias and cycles. This generalizes the backdoor criterion, the selection-backdoor criterion and extensions of these to arbitrary iSCMs. Together, our results thus enable causal reasoning in the presence of cycles, latent confounders and selection bias.
The capacity of feedforward neural networks
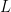
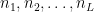

BMF: Block matrix approach to factorization of large scale data
Matrix Factorization (MF) on large scale matrices is computationally as well as memory intensive task. Alternative convergence techniques are needed when the size of the input matrix is higher than the available memory on a Central Processing Unit (CPU) and Graphical Processing Unit (GPU). While alternating least squares (ALS) convergence on CPU could take forever, loading all the required matrices on to GPU memory may not be possible when the dimensions are significantly higher. Hence we introduce a novel technique that is based on considering the entire data into a block matrix and relies on factorization at a block level.
Cost-sensitive Selection of Variables by Ensemble of Model Sequences
Many applications require the collection of data on different variables or measurements over many system performance metrics. We term those broadly as measures or variables. Often data collection along each measure incurs a cost, thus it is desirable to consider the cost of measures in modeling. This is a fairly new class of problems in the area of cost-sensitive learning. A few attempts have been made to incorporate costs in combining and selecting measures. However, existing studies either do not strictly enforce a budget constraint, or are not the most’ cost effective. With a focus on classification problem, we propose a computationally efficient approach that could find a near optimal model under a given budget by exploring the most promising’ part of the solution space. Instead of outputting a single model, we produce a model schedule—a list of models, sorted by model costs and expected predictive accuracy. This could be used to choose the model with the best predictive accuracy under a given budget, or to trade off between the budget and the predictive accuracy. Experiments on some benchmark datasets show that our approach compares favorably to competing methods.
Like this:
Like Loading…
Related