Generic adaptation strategies for automated machine learning
Automation of machine learning model development is increasingly becoming an established research area. While automated model selection and automated data pre-processing have been studied in depth, there is, however, a gap concerning automated model adaptation strategies when multiple strategies are available. Manually developing an adaptation strategy, including estimation of relevant parameters can be time consuming and costly. In this paper we address this issue by proposing generic adaptation strategies based on approaches from earlier works. Experimental results after using the proposed strategies with three adaptive algorithms on 36 datasets confirm their viability. These strategies often achieve better or comparable performance with custom adaptation strategies and naive methods such as repeatedly using only one adaptive mechanism.
Inference on average treatment effects in aggregate panel data settings

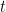
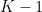
Fair Coresets and Streaming Algorithms for Fair k-Means Clustering
We study fair clustering problems as proposed by Chierichetti et al. Here, points have a sensitive attribute and all clusters in the solution are required to be balanced with respect to it (to counteract any form of data-inherent bias). Previous algorithms for fair clustering do not scale well. We show how to model and compute so-called coresets for fair clustering problems, which can be used to significantly reduce the input data size. We prove that the coresets are composable and show how to compute them in a streaming setting. We also propose a novel combination of the coreset construction with a sketching technique due to Cohen et al. which may be of independent interest. We conclude with an empirical evaluation.
Signal Classification under structure sparsity constraints
Object Classification is a key direction of research in signal and image processing, computer vision and artificial intelligence. The goal is to come up with algorithms that automatically analyze images and put them in predefined categories. This dissertation focuses on the theory and application of sparse signal processing and learning algorithms for image processing and computer vision, especially object classification problems. A key emphasis of this work is to formulate novel optimization problems for learning dictionary and structured sparse representations. Tractable solutions are proposed subsequently for the corresponding optimization problems. An important goal of this dissertation is to demonstrate the wide applications of these algorithmic tools for real-world applications. To that end, we explored important problems in the areas of: 1. Medical imaging: histopathological images acquired from mammalian tissues, human breast tissues, and human brain tissues. 2. Low-frequency (UHF to L-band) ultra-wideband (UWB) synthetic aperture radar: detecting bombs and mines buried under rough surfaces. 3. General object classification: face, flowers, objects, dogs, indoor scenes, etc.
Hypergraph Clustering: A Modularity Maximization Approach
Clustering on hypergraphs has been garnering increased attention with potential applications in network analysis, VLSI design and computer vision, among others. In this work, we generalize the framework of modularity maximization for clustering on hypergraphs. To this end, we introduce a hypergraph null model, analogous to the configuration model on undirected graphs, and a node-degree preserving reduction to work with this model. This is used to define a modularity function that can be maximized using the popular and fast Louvain algorithm. We additionally propose a refinement over this clustering, by reweighting cut hyperedges in an iterative fashion. The efficacy and efficiency of our methods are demonstrated on several real-world datasets.
InstaGAN: Instance-aware Image-to-Image Translation
Unsupervised image-to-image translation has gained considerable attention due to the recent impressive progress based on generative adversarial networks (GANs). However, previous methods often fail in challenging cases, in particular, when an image has multiple target instances and a translation task involves significant changes in shape, e.g., translating pants to skirts in fashion images. To tackle the issues, we propose a novel method, coined instance-aware GAN (InstaGAN), that incorporates the instance information (e.g., object segmentation masks) and improves multi-instance transfiguration. The proposed method translates both an image and the corresponding set of instance attributes while maintaining the permutation invariance property of the instances. To this end, we introduce a context preserving loss that encourages the network to learn the identity function outside of target instances. We also propose a sequential mini-batch inference/training technique that handles multiple instances with a limited GPU memory and enhances the network to generalize better for multiple instances. Our comparative evaluation demonstrates the effectiveness of the proposed method on different image datasets, in particular, in the aforementioned challenging cases.
Open-endedness in AI systems, cellular evolution and intellectual discussions
One of the biggest challenges that artificial intelligence (AI) research is facing in recent times is to develop algorithms and systems that are not only good at performing a specific intelligent task but also good at learning a very diverse of skills somewhat like humans do. In other words, the goal is to be able to mimic biological evolution which has produced all the living species on this planet and which seems to have no end to its creativity. The process of intellectual discussions is also somewhat similar to biological evolution in this regard and is responsible for many of the innovative discoveries and inventions that scientists and engineers have made in the past. In this paper, we present an information theoretic analogy between the process of discussions and the molecular dynamics within a cell, showing that there is a common process of information exchange at the heart of these two seemingly different processes, which can perhaps help us in building AI systems capable of open-ended innovation. We also discuss the role of consciousness in this process and present a framework for the development of open-ended AI systems.
Knowledge Representation Learning: A Quantitative Review
Passive-Aggressive Learning and Control
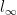
On Computation and Generalization of GANs with Spectrum Control
Generative Adversarial Networks (GANs), though powerful, is hard to train. Several recent works (brock2016neural,miyato2018spectral) suggest that controlling the spectra of weight matrices in the discriminator can significantly improve the training of GANs. Motivated by their discovery, we propose a new framework for training GANs, which allows more flexible spectrum control (e.g., making the weight matrices of the discriminator have slow singular value decays). Specifically, we propose a new reparameterization approach for the weight matrices of the discriminator in GANs, which allows us to directly manipulate the spectra of the weight matrices through various regularizers and constraints, without intensively computing singular value decompositions. Theoretically, we further show that the spectrum control improves the generalization ability of GANs. Our experiments on CIFAR-10, STL-10, and ImageNet datasets confirm that compared to other methods, our proposed method is capable of generating images with competitive quality by utilizing spectral normalization and encouraging the slow singular value decay.
Improving the Interpretability of Deep Neural Networks with Knowledge Distillation
Deep Neural Networks have achieved huge success at a wide spectrum of applications from language modeling, computer vision to speech recognition. However, nowadays, good performance alone is not sufficient to satisfy the needs of practical deployment where interpretability is demanded for cases involving ethics and mission critical applications. The complex models of Deep Neural Networks make it hard to understand and reason the predictions, which hinders its further progress. To tackle this problem, we apply the Knowledge Distillation technique to distill Deep Neural Networks into decision trees in order to attain good performance and interpretability simultaneously. We formulate the problem at hand as a multi-output regression problem and the experiments demonstrate that the student model achieves significantly better accuracy performance (about 1\% to 5\%) than vanilla decision trees at the same level of tree depth. The experiments are implemented on the TensorFlow platform to make it scalable to big datasets. To the best of our knowledge, we are the first to distill Deep Neural Networks into vanilla decision trees on multi-class datasets.
HUOPM: High Utility Occupancy Pattern Mining
Mining useful patterns from varied types of databases is an important research topic, which has many real-life applications. Most studies have considered the frequency as sole interestingness measure for identifying high quality patterns. However, each object is different in nature. The relative importance of objects is not equal, in terms of criteria such as the utility, risk, or interest. Besides, another limitation of frequent patterns is that they generally have a low occupancy, i.e., they often represent small sets of items in transactions containing many items, and thus may not be truly representative of these transactions. To extract high quality patterns in real life applications, this paper extends the occupancy measure to also assess the utility of patterns in transaction databases. We propose an efficient algorithm named High Utility Occupancy Pattern Mining (HUOPM). It considers user preferences in terms of frequency, utility, and occupancy. A novel Frequency-Utility tree (FU-tree) and two compact data structures, called the utility-occupancy list and FU-table, are designed to provide global and partial downward closure properties for pruning the search space. The proposed method can efficiently discover the complete set of high quality patterns without candidate generation. Extensive experiments have been conducted on several datasets to evaluate the effectiveness and efficiency of the proposed algorithm. Results show that the derived patterns are intelligible, reasonable and acceptable, and that HUOPM with its pruning strategies outperforms the state-of-the-art algorithm, in terms of runtime and search space, respectively.
Wikibook-Bot – Automatic Generation of a Wikipedia Book
A Wikipedia book (known as Wikibook) is a collection of Wikipedia articles on a particular theme that is organized as a book. We propose Wikibook-Bot, a machine-learning based technique for automatically generating high quality Wikibooks based on a concept provided by the user. In order to create the Wikibook we apply machine learning algorithms to the different steps of the proposed technique. Firs, we need to decide whether an article belongs to a specific Wikibook – a classification task. Then, we need to divide the chosen articles into chapters – a clustering task – and finally, we deal with the ordering task which includes two subtasks: order articles within each chapter and order the chapters themselves. We propose a set of structural, text-based and unique Wikipedia features, and we show that by using these features, a machine learning classifier can successfully address the above challenges. The predictive performance of the proposed method is evaluated by comparing the auto-generated books to existing 407 Wikibooks which were manually generated by humans. For all the tasks we were able to obtain high and statistically significant results when comparing the Wikibook-bot books to books that were manually generated by Wikipedia contributors
Answering Range Queries Under Local Differential Privacy
Counting the fraction of a population having an input within a specified interval i.e. a \emph{range query}, is a fundamental data analysis primitive. Range queries can also be used to compute other interesting statistics such as \emph{quantiles}, and to build prediction models. However, frequently the data is subject to privacy concerns when it is drawn from individuals, and relates for example to their financial, health, religious or political status. In this paper, we introduce and analyze methods to support range queries under the local variant of differential privacy, an emerging standard for privacy-preserving data analysis. The local model requires that each user releases a noisy view of her private data under a privacy guarantee. While many works address the problem of range queries in the trusted aggregator setting, this problem has not been addressed specifically under untrusted aggregation (local DP) model even though many primitives have been developed recently for estimating a discrete distribution. We describe and analyze two classes of approaches for range queries, based on hierarchical histograms and the Haar wavelet transform. We show that both have strong theoretical accuracy guarantees on variance. In practice, both methods are fast and require minimal computation and communication resources. Our experiments show that the wavelet approach is most accurate in high privacy settings, while the hierarchical approach dominates for weaker privacy requirements.
Parallel Algorithm for Frequent Itemset Mining on Intel Many-core Systems
Frequent itemset mining leads to the discovery of associations and correlations among items in large transactional databases. Apriori is a classical frequent itemset mining algorithm, which employs iterative passes over database combining with generation of candidate itemsets based on frequent itemsets found at the previous iteration, and pruning of clearly infrequent itemsets. The Dynamic Itemset Counting (DIC) algorithm is a variation of Apriori, which tries to reduce the number of passes made over a transactional database while keeping the number of itemsets counted in a pass relatively low. In this paper, we address the problem of accelerating DIC on the Intel Xeon Phi many-core system for the case when the transactional database fits in main memory. Intel Xeon Phi provides a large number of small compute cores with vector processing units. The paper presents a parallel implementation of DIC based on OpenMP technology and thread-level parallelism. We exploit the bit-based internal layout for transactions and itemsets. This technique reduces the memory space for storing the transactional database, simplifies the support count via logical bitwise operation, and allows for vectorization of such a step. Experimental evaluation on the platforms of the Intel Xeon CPU and the Intel Xeon Phi coprocessor with large synthetic and real databases showed good performance and scalability of the proposed algorithm.
Compact and Efficient Representation of General Graph Databases
In this paper, we propose a compact data structure to store labeled attributed graphs based on the k2-tree, which is a very compact data structure designed to represent a simple directed graph. The idea we propose can be seen as an extension of the k2-tree to support property graphs. In addition to the static approach, we also propose a dynamic version of the storage representation, which allows exible schemas and insertion or deletion of data. We provide an implementation of a basic set of operations, which can be combined to form complex queries over these graphs with attributes. We evaluate the performance of our proposal with existing graph database systems and prove that our compact attributed graph representation obtains also competitive time results.
Vilin: Unconstrained Numerical Optimization Application
We introduce an application for executing and testing different unconstrained optimization algorithms. The application contains a library of various test functions with pre-defined starting points. A several known classes of methods as well as different classes of line search procedures are covered. Each method can be tested on various test function with a chosen number of parameters. Solvers come with optimal pre-defined parameter values which simplifies the usage. Additionally, user friendly interface gives an opportunity for advanced users to use their expertise and also easily fine-tune a large number of hyper parameters for obtaining even more optimal solution. This application can be used as a tool for developing new optimization algorithms (by using simple API), as well as for testing and comparing existing ones, by using given standard library of test functions. Special care has been given in order to achieve good numerical stability of all vital parts of the application. The application is implemented in programming language Matlab with very helpful gui support.
Hybrid Wasserstein Distance and Fast Distribution Clustering
We define a modified Wasserstein distance for distribution clustering which inherits many of the properties of the Wasserstein distance but which can be estimated easily and computed quickly. The modified distance is the sum of two terms. The first term — which has a closed form — measures the location-scale differences between the distributions. The second term is an approximation that measures the remaining distance after accounting for location-scale differences. We consider several forms of approximation with our main emphasis being a tangent space approximation that can be estimated using nonparametric regression. We evaluate the strengths and weaknesses of this approach on simulated and real examples.
Exploring Weight Symmetry in Deep Neural Network
Predicting with Proxies
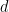
Scalable GAM using sparse variational Gaussian processes
Generalized additive models (GAMs) are a widely used class of models of interest to statisticians as they provide a flexible way to design interpretable models of data beyond linear models. We here propose a scalable and well-calibrated Bayesian treatment of GAMs using Gaussian processes (GPs) and leveraging recent advances in variational inference. We use sparse GPs to represent each component and exploit the additive structure of the model to efficiently represent a Gaussian a posteriori coupling between the components.
Cardiology Admissions from Catheterization Laboratory: Time Series Forecasting
Emergent and unscheduled cardiology admissions from cardiac catheterization laboratory add complexity to the management of Cardiology and in-patient department. In this article, we sought to study the behavior of cardiology admissions from Catheterization laboratory using time series models. Our research involves retrospective cardiology admission data from March 1, 2012, to November 3, 2016, retrieved from a hospital in Iowa. Autoregressive integrated moving average (ARIMA), Holts method, mean method, na\’ive method, seasonal na\’ive, exponential smoothing, and drift method were implemented to forecast weekly cardiology admissions from Catheterization laboratory. ARIMA (2,0,2) (1,1,1) was selected as the best fit model with the minimum sum of error, Akaike information criterion and Schwartz Bayesian criterion. The model failed to reject the null hypothesis of stationarity, it lacked the evidence of independence, and rejected the null hypothesis of normality. The implication of this study will not only improve catheterization laboratory staff schedule, advocate efficient use of imaging equipment and inpatient telemetry beds but also equip management to proactively tackle inpatient overcrowding, plan for physical capacity expansion and so forth.
Differential Temporal Difference Learning
Value functions derived from Markov decision processes arise as a central component of algorithms as well as performance metrics in many statistics and engineering applications of machine learning techniques. Computation of the solution to the associated Bellman equations is challenging in most practical cases of interest. A popular class of approximation techniques, known as Temporal Difference (TD) learning algorithms, are an important sub-class of general reinforcement learning methods. The algorithms introduced in this paper are intended to resolve two well-known difficulties of TD-learning approaches: Their slow convergence due to very high variance, and the fact that, for the problem of computing the relative value function, consistent algorithms exist only in special cases. First we show that the gradients of these value functions admit a representation that lends itself to algorithm design. Based on this result, a new class of differential TD-learning algorithms is introduced. For Markovian models on Euclidean space with smooth dynamics, the algorithms are shown to be consistent under general conditions. Numerical results show dramatic variance reduction when compared to standard methods.
The Diagrammatic AI Language (DIAL): Version 0.1
Currently, there is no consistent model for visually or formally representing the architecture of AI systems. This lack of representation brings interpretability, correctness and completeness challenges in the description of existing models and systems. DIAL (The Diagrammatic AI Language) has been created with the aspiration of being an ‘engineering schematic’ for AI Systems. It is presented here as a starting point for a community dialogue towards a common diagrammatic language for AI Systems.
MEETING BOT: Reinforcement Learning for Dialogue Based Meeting Scheduling
In this paper we present Meeting Bot, a reinforcement learning based conversational system that interacts with multiple users to schedule meetings. The system is able to interpret user utterences and map them to preferred time slots, which are then fed to a reinforcement learning (RL) system with the goal of converging on an agreeable time slot. The RL system is able to adapt to user preferences and environmental changes in meeting arrival rate while still scheduling effectively. Learning is performed via policy gradient with exploration, by utilizing an MLP as an approximator of the policy function. Results demonstrate that the system outperforms standard scheduling algorithms in terms of overall scheduling efficiency. Additionally, the system is able to adapt its strategy to situations when users consistently reject or accept meetings in certain slots (such as Friday afternoon versus Thursday morning), or when the meeting is called by members who are at a more senior designation.
Like this:
Like Loading…
Related