Synthetic Difference in Differences
We present a new perspective on the Synthetic Control (SC) method as a weighted regression estimator with time fixed effects. This perspective suggests a generalization with two way (both unit and time) fixed effects, which can be interpreted as a weighted version of the standard Difference In Differences (DID) estimator. We refer to this new estimator as the Synthetic Difference In Differences (SDID) estimator. We validate our approach formally, in simulations, and in an application, finding that this new SDID estimator has attractive properties compared to the SC and DID estimators. In particular, we find that our approach has doubly robust properties: the SDID estimator is consistent under a wide variety of weighting schemes given a well-specified fixed effects model, and SDID is consistent with appropriately penalized SC weights when the basic fixed effects model is misspecified and instead the true data generating process involves a more general low-rank structure (e.g., a latent factor model). We also present results that justify standard inference based on weighted DID regression.
Iroko: A Framework to Prototype Reinforcement Learning for Data Center Traffic Control
The Voice of Optimization
We introduce the idea that using optimal classification trees (OCTs) and optimal classification trees with-hyperplanes (OCT-Hs), interpretable machine learning algorithms developed in [BD17, BD18], we are able to obtain insight on the strategy behind the optimal solution in any continuous and mixed-integer convex optimization problem as a function of key parameters that affect the problem. In this way, optimization is not a black box anymore. Instead, we redefine optimization as a multiclass classification problem where the predictor gives insights on the logic behind the optimal solution. In other words, OCTs and OCT-Hs give optimization a voice. We show on several realistic examples that the accuracy behind our method is in the 90%-100% range, while even when the predictions are not correct, the degree of suboptimality or infeasibility is very low. We compare optimal strategy predictions of OCTs and OCT-Hs and feed-forward neural networks (NNs) and conclude that the performance of OCT-Hs and NNs is comparable. OCTs are somewhat weaker but often competitive. Therefore, our approach provides a novel, reliable and insightful understanding of optimal strategies to solve a broad class of continuous and mixed-integer optimization problems.
Joint Embedding Learning and Low-Rank Approximation: A Framework for Incomplete Multi-view Learning
In real-world applications, not all instances in multi-view data are fully represented. To deal with incomplete multi-view data, traditional multi-view algorithms usually throw away the incomplete instances, resulting in loss of available information. To overcome this loss, Incomplete Multi-view Learning (IML) has become a hot research topic. In this paper, we propose a general IML framework for unifying existing IML methods and gaining insight into IML. The proposed framework jointly performs embedding learning and low-rank approximation. Concretely, it approximates the incomplete data by a set of low-rank matrices and learns a full and common embedding by linear transformation. Several existing IML methods can be unified as special cases of the framework. More interestingly, some linear transformation based full-view methods can be adapted to IML directly with the guidance of the framework. This bridges the gap between full multi-view learning and IML. Moreover, the framework can provide guidance for developing new algorithms. For illustration, within the framework, we propose a specific method, termed as Incomplete Multi-view Learning with Block Diagonal Representation (IML-BDR). Based on the assumption that the sampled examples have approximate linear subspace structure, IML-BDR uses the block diagonal structure prior to learn the full embedding, which would lead to more correct clustering. A convergent alternating iterative algorithm with the Successive Over-Relaxation (SOR) optimization technique is devised for optimization. Experimental results on various datasets demonstrate the effectiveness of IML-BDR.
Optimal False Discovery Control of Minimax Estimator
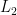
JALAD: Joint Accuracy- and Latency-Aware Deep Structure Decoupling for Edge-Cloud Execution
Recent years have witnessed a rapid growth of deep-network based services and applications. A practical and critical problem thus has emerged: how to effectively deploy the deep neural network models such that they can be executed efficiently. Conventional cloud-based approaches usually run the deep models in data center servers, causing large latency because a significant amount of data has to be transferred from the edge of network to the data center. In this paper, we propose JALAD, a joint accuracy- and latency-aware execution framework, which decouples a deep neural network so that a part of it will run at edge devices and the other part inside the conventional cloud, while only a minimum amount of data has to be transferred between them. Though the idea seems straightforward, we are facing challenges including i) how to find the best partition of a deep structure; ii) how to deploy the component at an edge device that only has limited computation power; and iii) how to minimize the overall execution latency. Our answers to these questions are a set of strategies in JALAD, including 1) A normalization based in-layer data compression strategy by jointly considering compression rate and model accuracy; 2) A latency-aware deep decoupling strategy to minimize the overall execution latency; and 3) An edge-cloud structure adaptation strategy that dynamically changes the decoupling for different network conditions. Experiments demonstrate that our solution can significantly reduce the execution latency: it speeds up the overall inference execution with a guaranteed model accuracy loss.
Building a Neural Semantic Parser from a Domain Ontology
Semantic parsing is the task of converting natural language utterances into machine interpretable meaning representations which can be executed against a real-world environment such as a database. Scaling semantic parsing to arbitrary domains faces two interrelated challenges: obtaining broad coverage training data effectively and cheaply; and developing a model that generalizes to compositional utterances and complex intentions. We address these challenges with a framework which allows to elicit training data from a domain ontology and bootstrap a neural parser which recursively builds derivations of logical forms. In our framework meaning representations are described by sequences of natural language templates, where each template corresponds to a decomposed fragment of the underlying meaning representation. Although artificial, templates can be understood and paraphrased by humans to create natural utterances, resulting in parallel triples of utterances, meaning representations, and their decompositions. These allow us to train a neural semantic parser which learns to compose rules in deriving meaning representations. We crowdsource training data on six domains, covering both single-turn utterances which exhibit rich compositionality, and sequential utterances where a complex task is procedurally performed in steps. We then develop neural semantic parsers which perform such compositional tasks. In general, our approach allows to deploy neural semantic parsers quickly and cheaply from a given domain ontology.
PPD: Permutation Phase Defense Against Adversarial Examples in Deep Learning
Deep neural networks have demonstrated cutting edge performance on various tasks including classification. However, it is well known that adversarially designed imperceptible perturbation of the input can mislead advanced classifiers. In this paper, Permutation Phase Defense (PPD), is proposed as a novel method to resist adversarial attacks. PPD combines random permutation of the image with phase component of its Fourier transform. The basic idea behind this approach is to turn adversarial defense problems analogously into symmetric cryptography, which relies solely on safekeeping of the keys for security. In PPD, safe keeping of the selected permutation ensures effectiveness against adversarial attacks. Testing PPD on MNIST and CIFAR-10 datasets yielded state-of-the-art robustness against the most powerful adversarial attacks currently available.
Coupled Recurrent Network (CRN)
Many semantic video analysis tasks can benefit from multiple, heterogenous signals. For example, in addition to the original RGB input sequences, sequences of optical flow are usually used to boost the performance of human action recognition in videos. To learn from these heterogenous input sources, existing methods reply on two-stream architectural designs that contain independent, parallel streams of Recurrent Neural Networks (RNNs). However, two-stream RNNs do not fully exploit the reciprocal information contained in the multiple signals, let alone exploit it in a recurrent manner. To this end, we propose in this paper a novel recurrent architecture, termed Coupled Recurrent Network (CRN), to deal with multiple input sources. In CRN, the parallel streams of RNNs are coupled together. Key design of CRN is a Recurrent Interpretation Block (RIB) that supports learning of reciprocal feature representations from multiple signals in a recurrent manner. Different from RNNs which stack the training loss at each time step or the last time step, we propose an effective and efficient training strategy for CRN. Experiments show the efficacy of the proposed CRN. In particular, we achieve the new state of the art on the benchmark datasets of human action recognition and multi-person pose estimation.
A backward procedure for change-point detection with applications to copy number variation detection
Change-point detection regains much attention recently for analyzing array or sequencing data for copy number variation (CNV) detection. In such applications, the true signals are typically very short and buried in the long data sequence, which makes it challenging to identify the variations efficiently and accurately. In this article, we propose a new change-point detection method, a backward procedure, that is not only fast and simple enough to exploit high-dimensional data but also performs very well for detecting short signals. Although motivated by CNV detection, the backward procedure is generally applicable to assorted change-point problems that arise in a variety of scientific applications. It is illustrated by both simulated and real CNV data that the backward detection has clear advantages over other competing methods especially when the true signal is short.
Privacy-Preserving Collaborative Deep Learning with Irregular Participants

Sequence to Sequence Learning for Query Expansion
Using sequence to sequence algorithms for query expansion has not been explored yet in Information Retrieval literature nor in Question-Answering’s. We tried to fill this gap in the literature with a custom Query Expansion engine trained and tested on open datasets. Starting from open datasets, we built a Query Expansion training set using sentence-embeddings-based Keyword Extraction. We therefore assessed the ability of the Sequence to Sequence neural networks to capture expanding relations in the words embeddings’ space.
Can rationality be measured?
This paper studies whether rationality can be computed. Rationality is defined as the use of complete information, which is processed with a perfect biological or physical brain, in an optimized fashion. To compute rationality one needs to quantify how complete is the information, how perfect is the physical or biological brain and how optimized is the entire decision making system. The rationality of a model (i.e. physical or biological brain) is measured by the expected accuracy of the model. The rationality of the optimization procedure is measured as the ratio of the achieved objective (i.e. utility) to the global objective. The overall rationality of a decision is measured as the product of the rationality of the model and the rationality of the optimization procedure. The conclusion reached is that rationality can be computed for convex optimization problems.
Dropout Regularization in Hierarchical Mixture of Experts
Dropout is a very effective method in preventing overfitting and has become the go-to regularizer for multi-layer neural networks in recent years. Hierarchical mixture of experts is a hierarchically gated model that defines a soft decision tree where leaves correspond to experts and decision nodes correspond to gating models that softly choose between its children, and as such, the model defines a soft hierarchical partitioning of the input space. In this work, we propose a variant of dropout for hierarchical mixture of experts that is faithful to the tree hierarchy defined by the model, as opposed to having a flat, unitwise independent application of dropout as one has with multi-layer perceptrons. We show that on a synthetic regression data and on MNIST and CIFAR-10 datasets, our proposed dropout mechanism prevents overfitting on trees with many levels improving generalization and providing smoother fits.
Portfolio Optimization for Cointelated Pairs: SDEs vs. Machine Learning
We investigate the problem of dynamic portfolio optimization in continuous-time, finite-horizon setting for a portfolio of two stocks and one risk-free asset. The stocks follow the Cointelation model. The proposed optimization methods are twofold. In what we call an Stochastic Differential Equation approach, we compute the optimal weights using mean-variance criterion and power utility maximization. We show that dynamically switching between these two optimal strategies by introducing a triggering function can further improve the portfolio returns. We contrast this with the machine learning clustering methodology inspired by the band-wise Gaussian mixture model. The first benefit of the machine learning over the Stochastic Differential Equation approach is that we were able to achieve the same results though a simpler channel. The second advantage is a flexibility to regime change.
rstap: An R Package for Spatial Temporal Aggregated Predictor Models
The rstap package implements Bayesian spatial temporal aggregated predictor models in R using the probabilistic programming language Stan. A variety of distributions and link functions are supported, allowing users to fit this extension to the generalized linear model with both independent and correlated outcomes.
Weighted correlated component analysis for frequency recognition in SSVEP-based BCI
Correlated component analysis (CORRCA) is a novel method for frequency recognition in steady-state visual evoked potential (SSVEP) based brain-computer interface (BCI), which holds the potential to implement high-performance SSVEP-based BCI systems. CORRCA could provide multiple correlation coefficients to measure the correlation between two signals. However, only the largest one is selected as feature while ignoring all others in previous study, which loses the discriminating information. In current study, we proposed a weighting strategy with nonlinear function to combine all the correlation coefficients to enhance the performance of CORRCA method. Extensive experimental results on a benchmark dataset of thirty-five subjects indicate that the proposed method significantly outperforms the original CORRCA method. This study demonstrates that the proposed method could be a good choice for frequency recognition in SSVEP-based BCI systems.
Learning to Refine Source Representations for Neural Machine Translation
Neural machine translation (NMT) models generally adopt an encoder-decoder architecture for modeling the entire translation process. The encoder summarizes the representation of input sentence from scratch, which is potentially a problem if the sentence is ambiguous. When translating a text, humans often create an initial understanding of the source sentence and then incrementally refine it along the translation on the target side. Starting from this intuition, we propose a novel encoder-refiner-decoder framework, which dynamically refines the source representations based on the generated target-side information at each decoding step. Since the refining operations are time-consuming, we propose a strategy, leveraging the power of reinforcement learning models, to decide when to refine at specific decoding steps. Experimental results on both Chinese-English and English-German translation tasks show that the proposed approach significantly and consistently improves translation performance over the standard encoder-decoder framework. Furthermore, when refining strategy is applied, results still show reasonable improvement over the baseline without much decrease in decoding speed.
Meta Learning for Few-shot Keyword Spotting
Keyword spotting with limited training data is a challenging task which can be treated as a few-shot learning problem. In this paper, we present a meta-learning approach which learns a good initialization of the base KWS model from existed labeled dataset. Then it can quickly adapt to new tasks of keyword spotting with only a few labeled data. Furthermore, to strengthen the ability of distinguishing the keywords with the others, we incorporate the negative class as external knowledge to the meta-training process, which proves to be effective. Experiments on the Google Speech Commands dataset show that our proposed approach outperforms the baselines.
A New Concept of Deep Reinforcement Learning based Augmented General Sequence Tagging System
In this paper, a new deep reinforcement learning based augmented general sequence tagging system is proposed. The new system contains two parts: a deep neural network (DNN) based sequence tagging model and a deep reinforcement learning (DRL) based augmented tagger. The augmented tagger helps improve system performance by modeling the data with minority tags. The new system is evaluated on SLU and NLU sequence tagging tasks using ATIS and CoNLL-2003 benchmark datasets, to demonstrate the new system’s outstanding performance on general tagging tasks. Evaluated by F1 scores, it shows that the new system outperforms the current state-of-the-art model on ATIS dataset by 1.9% and that on CoNLL-2003 dataset by 1.4%.
Comparing Spatial Regression to Random Forests for Large Environmental Data Sets
Environmental data may be ‘large’ due to number of records, number of covariates, or both. Random forests has a reputation for good predictive performance when using many covariates with nonlinear relationships, whereas spatial regression, when using reduced rank methods, has a reputation for good predictive performance when using many records that are spatially autocorrelated. In this study, we compare these two techniques using a data set containing the macroinvertebrate multimetric index (MMI) at 1859 stream sites with over 200 landscape covariates. A primary application is mapping MMI predictions and prediction errors at 1.1 million perennial stream reaches across the conterminous United States. For the spatial regression model, we develop a novel transformation procedure that estimates Box-Cox transformations to linearize covariate relationships and handles possibly zero-inflated covariates. We find that the spatial regression model with transformations, and a subsequent selection of significant covariates, has cross-validation performance slightly better than random forests. We also find that prediction interval coverage is close to nominal for each method, but that spatial regression prediction intervals tend to be narrower and have less variability than quantile regression forest prediction intervals. A simulation study is used to generalize results and clarify advantages of each modeling approach.
Towards a Theoretical Understanding of Hashing-Based Neural Nets
Parameter reduction has been an important topic in deep learning due to the ever-increasing size of deep neural network models and the need to train and run them on resource limited machines. Despite many efforts in this area, there were no rigorous theoretical guarantees on why existing neural net compression methods should work. In this paper, we provide provable guarantees on some hashing-based parameter reduction methods in neural nets. First, we introduce a neural net compression scheme based on random linear sketching (which is usually implemented efficiently via hashing), and show that the sketched (smaller) network is able to approximate the original network on all input data coming from any smooth and well-conditioned low-dimensional manifold. The sketched network can also be trained directly via back-propagation. Next, we study the previously proposed HashedNets architecture and show that the optimization landscape of one-hidden-layer HashedNets has a local strong convexity property similar to a normal fully connected neural network. We complement our theoretical results with empirical verifications.
A Survey to Deep Facial Attribute Analysis
Facial attribute analysis has received considerable attention with the development of deep neural networks in the past few years. Facial attribute analysis contains two crucial issues: Facial Attribute Estimation (FAE), which recognizes whether facial attributes are present in given images, and Facial Attribute Manipulation (FAM), which synthesizes or removes desired facial attributes. In this paper, we provide a comprehensive survey on deep facial attribute analysis covering FAE and FAM. First, we present the basic knowledge of the two stages (i.e., data pre-processing and model construction) in the general deep facial attribute analysis pipeline. Second, we summarize the commonly used datasets and performance metrics. Third, we create a taxonomy of the state-of-the-arts and review detailed algorithms in FAE and FAM, respectively. Furthermore, we introduce several additional facial attribute related issues and applications. Finally, the possible challenges and future research directions are discussed.
The Use of MPI and OpenMP Technologies for Subsequence Similarity Search in Very Large Time Series on Computer Cluster System with Nodes Based on the Intel Xeon Phi Knights Landing Many-core Processor
Nowadays, subsequence similarity search is required in a wide range of time series mining applications: climate modeling, financial forecasts, medical research, etc. In most of these applications, the Dynamic TimeWarping (DTW) similarity measure is used since DTW is empirically confirmed as one of the best similarity measure for most subject domains. Since the DTW measure has a quadratic computational complexity w.r.t. the length of query subsequence, a number of parallel algorithms for various many-core architectures have been developed, namely FPGA, GPU, and Intel MIC. In this article, we propose a new parallel algorithm for subsequence similarity search in very large time series on computer cluster systems with nodes based on Intel Xeon Phi Knights Landing (KNL) many-core processors. Computations are parallelized on two levels as follows: through MPI at the level of all cluster nodes, and through OpenMP within one cluster node. The algorithm involves additional data structures and redundant computations, which make it possible to effectively use the capabilities of vector computations on Phi KNL. Experimental evaluation of the algorithm on real-world and synthetic datasets shows that it is highly scalable.
Learning Not to Learn: Training Deep Neural Networks with Biased Data
We propose a novel regularization algorithm to train deep neural networks, in which data at training time is severely biased. Since a neural network efficiently learns data distribution, a network is likely to learn the bias information to categorize input data. It leads to poor performance at test time, if the bias is, in fact, irrelevant to the categorization. In this paper, we formulate a regularization loss based on mutual information between feature embedding and bias. Based on the idea of minimizing this mutual information, we propose an iterative algorithm to unlearn the bias information. We employ an additional network to predict the bias distribution and train the network adversarially against the feature embedding network. At the end of learning, the bias prediction network is not able to predict the bias not because it is poorly trained, but because the feature embedding network successfully unlearns the bias information. We also demonstrate quantitative and qualitative experimental results which show that our algorithm effectively removes the bias information from feature embedding.
Large Multistream Data Analytics for Monitoring and Diagnostics in Manufacturing Systems
The high-dimensionality and volume of large scale multistream data has inhibited significant research progress in developing an integrated monitoring and diagnostics (M&D) approach. This data, also categorized as big data, is becoming common in manufacturing plants. In this paper, we propose an integrated M\&D approach for large scale streaming data. We developed a novel monitoring method named Adaptive Principal Component monitoring (APC) which adaptively chooses PCs that are most likely to vary due to the change for early detection. Importantly, we integrate a novel diagnostic approach, Principal Component Signal Recovery (PCSR), to enable a streamlined SPC. This diagnostics approach draws inspiration from Compressed Sensing and uses Adaptive Lasso for identifying the sparse change in the process. We theoretically motivate our approaches and do a performance evaluation of our integrated M&D method through simulations and case studies.
CodedSketch: A Coding Scheme for Distributed Computation of Approximated Matrix Multiplications
In this paper, we propose CodedSketch, as a distributed straggler-resistant scheme to compute an approximation of the multiplication of two massive matrices. The objective is to reduce recovery threshold, defined as the total number of worker nodes that we need to wait for to be able to recover the final result. To exploit the fact that only an approximated result is required, in reducing the recovery threshold, some sorts of pre-compression is required. However, compression inherently involves some randomness that would lose the structure of the matrices. On the other hand, considering the structure of the matrices is crucial to reduce the recovery threshold. In CodedSketch, we use count–sketch, as a hash-based compression scheme, on the rows of the first and columns of the second matrix, and a structured polynomial code on the columns of the first and rows of the second matrix. This arrangement allows us to exploits the gain of both in reducing the recovery threshold. To increase the accuracy of computation, multiple independent count–sketches are needed. This independency allows us to theoretically characterize the accuracy of the result and establish the recovery threshold achieved by the proposed scheme. To guarantee the independency of resulting count–sketches in the output, while keeping its cost on the recovery threshold minimum, we use another layer of structured codes.
Like this:
Like Loading…
Related