SMART: An Open Source Data Labeling Platform for Supervised Learning
SMART is an open source web application designed to help data scientists and research teams efficiently build labeled training data sets for supervised machine learning tasks. SMART provides users with an intuitive interface for creating labeled data sets, supports active learning to help reduce the required amount of labeled data, and incorporates inter-rater reliability statistics to provide insight into label quality. SMART is designed to be platform agnostic and easily deployable to meet the needs of as many different research teams as possible. The project website contains links to the code repository and extensive user documentation.
Javelin: A Scalable Implementation for Sparse Incomplete LU Factorization
In this work, we present a new scalable incomplete LU factorization framework called Javelin to be used as a preconditioner for solving sparse linear systems with iterative methods. Javelin allows for improved parallel factorization on shared-memory many-core systems, while packaging the coefficient matrix into a format that allows for high performance sparse matrix-vector multiplication and sparse triangular solves with minimal overheads. The framework achieves these goals by using a collection of traditional permutations, point-to-point thread synchronizations, tasking, and segmented prefix scans in a conventional compressed sparse row format. Using these changes, traditional fill-in and drop tolerance methods can be used, while still being able to have observed speedups of up to ~42x on 68 Intel Knights Landing cores and ~12 x on 14 Intel Haswell cores.
TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition
We present Temporal Aggregation Network (TAN) which decomposes 3D convolutions into spatial and temporal aggregation blocks. By stacking spatial and temporal convolutions repeatedly, TAN forms a deep hierarchical representation for capturing spatio-temporal information in videos. Since we do not apply 3D convolutions in each layer but only apply temporal aggregation blocks once after each spatial downsampling layer in the network, we significantly reduce the model complexity. The use of dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatio-temporal information efficiently. Experiments show that our model is well suited for dense multi-label action recognition, which is a challenging sub-topic of action recognition that requires predicting multiple action labels in each frame. We outperform state-of-the-art methods by 5% and 3% on the Charades and Multi-THUMOS dataset respectively.
Causal Identification under Markov Equivalence
Assessing the magnitude of cause-and-effect relations is one of the central challenges found throughout the empirical sciences. The problem of identification of causal effects is concerned with determining whether a causal effect can be computed from a combination of observational data and substantive knowledge about the domain under investigation, which is formally expressed in the form of a causal graph. In many practical settings, however, the knowledge available for the researcher is not strong enough so as to specify a unique causal graph. Another line of investigation attempts to use observational data to learn a qualitative description of the domain called a Markov equivalence class, which is the collection of causal graphs that share the same set of observed features. In this paper, we marry both approaches and study the problem of causal identification from an equivalence class, represented by a partial ancestral graph (PAG). We start by deriving a set of graphical properties of PAGs that are carried over to its induced subgraphs. We then develop an algorithm to compute the effect of an arbitrary set of variables on an arbitrary outcome set. We show that the algorithm is strictly more powerful than the current state of the art found in the literature.
Domain-to-Domain Translation Model for Recommender System
Recently multi-domain recommender systems have received much attention from researchers because they can solve cold-start problem as well as support for cross-selling. However, when applying into multi-domain items, although algorithms specifically addressing a single domain have many difficulties in capturing the specific characteristics of each domain, multi-domain algorithms have less opportunity to obtain similar features among domains. Because both similarities and differences exist among domains, multi-domain models must capture both to achieve good performance. Other studies of multi-domain systems merely transfer knowledge from the source domain to the target domain, so the source domain usually comes from external factors such as the search query or social network, which is sometimes impossible to obtain. To handle the two problems, we propose a model that can extract both homogeneous and divergent features among domains and extract data in a domain can support for other domain equally: a so-called Domain-to-Domain Translation Model (D2D-TM). It is based on generative adversarial networks (GANs), Variational Autoencoders (VAEs), and Cycle-Consistency (CC) for weight-sharing. We use the user interaction history of each domain as input and extract latent features through a VAE-GAN-CC network. Experiments underscore the effectiveness of the proposed system over state-of-the-art methods by a large margin.
Wikipedia2Vec: An Optimized Implementation for Learning Embeddings from Wikipedia
Hinted Networks
We present Hinted Networks: a collection of architectural transformations for improving the accuracies of neural network models for regression tasks, through the injection of a prior for the output prediction (i.e. a hint). We ground our investigations within the camera relocalization domain, and propose two variants, namely the Hinted Embedding and Hinted Residual networks, both applied to the PoseNet base model for regressing camera pose from an image. Our evaluations show practical improvements in localization accuracy for standard outdoor and indoor localization datasets, without using additional information. We further assess the range of accuracy gains within an aerial-view localization setup, simulated across vast areas at different times of the year.
Residual Policy Learning
We present Residual Policy Learning (RPL): a simple method for improving nondifferentiable policies using model-free deep reinforcement learning. RPL thrives in complex robotic manipulation tasks where good but imperfect controllers are available. In these tasks, reinforcement learning from scratch remains data-inefficient or intractable, but learning a residual on top of the initial controller can yield substantial improvement. We study RPL in five challenging MuJoCo tasks involving partial observability, sensor noise, model misspecification, and controller miscalibration. By combining learning with control algorithms, RPL can perform long-horizon, sparse-reward tasks for which reinforcement learning alone fails. Moreover, we find that RPL consistently and substantially improves on the initial controllers. We argue that RPL is a promising approach for combining the complementary strengths of deep reinforcement learning and robotic control, pushing the boundaries of what either can achieve independently.
Multi-Tasking Evolutionary Algorithm (MTEA) for Single-Objective Continuous Optimization
Multi-task learning uses auxiliary data or knowledge from relevant tasks to facilitate the learning in a new task. Multi-task optimization applies multi-task learning to optimization to study how to effectively and efficiently tackle multiple optimization problems simultaneously. Evolutionary multi-tasking, or multi-factorial optimization, is an emerging subfield of multi-task optimization, which integrates evolutionary computation and multi-task learning. This paper proposes a novel easy-to-implement multi-tasking evolutionary algorithm (MTEA), which copes well with significantly different optimization tasks by estimating and using the bias among them. Comparative studies with eight state-of-the-art single- and multi-task approaches in the literature on nine benchmarks demonstrated that on average the MTEA outperformed all of them, and has lower computational cost than six of them. Particularly, unlike other multi-task algorithms, the performance of the MTEA is consistently good whether the tasks are similar or significantly different, making it ideal for real-world applications.
Data-efficient Auto-tuning with Bayesian Optimization: An Industrial Control Study
Bayesian optimization is proposed for automatic learning of optimal controller parameters from experimental data. A probabilistic description (a Gaussian process) is used to model the unknown function from controller parameters to a user-defined cost. The probabilistic model is updated with data, which is obtained by testing a set of parameters on the physical system and evaluating the cost. In order to learn fast, the Bayesian optimization algorithm selects the next parameters to evaluate in a systematic way, for example, by maximizing information gain about the optimum. The algorithm thus iteratively finds the globally optimal parameters with only few experiments. Taking throttle valve control as a representative industrial control example, the proposed auto-tuning method is shown to outperform manual calibration: it consistently achieves better performance with a low number of experiments. The proposed auto-tuning framework is flexible and can handle different control structures and objectives.
Origraph: Interactive Network Wrangling
Data wrangling is widely acknowledged to be a critical part of the data analysis pipeline. Nevertheless, there are currently no techniques to efficiently wrangle network datasets. Here we introduce a set of interaction techniques that enable analysts to carry out complex network wrangling operations. These operations include deriving attributes across connected classes, converting nodes to edges and vice-versa, and faceting nodes and edges based on attributes. We implement these operations in a web-based, open-source system, Origraph, which provides interfaces to execute the operations and investigate the results. Designed for wrangling, rather than analysis, Origraph can be used to load data in many forms, wrangle and transform the network, and export it in formats compatible with common network visualization tools. We demonstrate Origraph’s usefulness in a series of examples with different datasets from a variety of sources.
NSCaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding
Knowledge Graph (KG) embedding is a fundamental problem in data mining research with many real-world applications. It aims to encode the entities and relations in the graph into low dimensional vector space, which can be used for subsequent algorithms. Negative sampling, which samples negative triplets from non-observed ones in the training data, is an important step in KG embedding. Recently, generative adversarial network (GAN), has been introduced in negative sampling. By sampling negative triplets with large scores, these methods avoid the problem of vanishing gradient and thus obtain better performance. However, using GAN makes the original model more complex and hard to train, where reinforcement learning must be used. In this paper, motivated by the observation that negative triplets with large scores are important but rare, we propose to directly keep track of them with the cache. However, how to sample from and update the cache are two important questions. We carefully design the solutions, which are not only efficient but also achieve a good balance between exploration and exploitation. In this way, our method acts as a ‘distilled’ version of previous GA-based methods, which does not waste training time on additional parameters to fit the full distribution of negative triplets. The extensive experiments show that our method can gain significant improvement in various KG embedding models, and outperform the state-of-the-art negative sampling methods based on GAN.
Coded Elastic Computing
Cloud providers have recently introduced low-priority machines to reduce the cost of computations. Exploiting such opportunity for machine learning tasks is challenging inasmuch as low-priority machines can elastically leave (through preemption) and join the computation at any time. In this paper, we design a new technique called coded elastic computing enabling distributed machine learning computations over elastic resources. The proposed technique allows machines to transparently leave the computation without sacrificing the algorithm-level performance, and, at the same time, flexibly reduce the workload at existing machines when new machines join the computation. Thanks to the redundancy provided by encoding, our approach is able to achieve similar computational cost as the original (uncoded) method when all machines are present; the cost gracefully increases when machines are preempted and reduces when machines join. We test the performance of the proposed technique on two mini-benchmark experiments, namely elastic matrix multiplications and linear regression. Our preliminary experimental results show improvements over several existing techniques.
Stochastic Distributed Optimization for Machine Learning from Decentralized Features

Auto-tuning Neural Network Quantization Framework for Collaborative Inference Between the Cloud and Edge
Recently, deep neural networks (DNNs) have been widely applied in mobile intelligent applications. The inference for the DNNs is usually performed in the cloud. However, it leads to a large overhead of transmitting data via wireless network. In this paper, we demonstrate the advantages of the cloud-edge collaborative inference with quantization. By analyzing the characteristics of layers in DNNs, an auto-tuning neural network quantization framework for collaborative inference is proposed. We study the effectiveness of mixed-precision collaborative inference of state-of-the-art DNNs by using ImageNet dataset. The experimental results show that our framework can generate reasonable network partitions and reduce the storage on mobile devices with trivial loss of accuracy.
‘When and Where?’: Behavior Dominant Location Forecasting with Micro-blog Streams
The proliferation of smartphones and wearable devices has increased the availability of large amounts of geospatial streams to provide significant automated discovery of knowledge in pervasive environments, but most prominent information related to altering interests have not yet adequately capitalized. In this paper, we provide a novel algorithm to exploit the dynamic fluctuations in user’s point-of-interest while forecasting the future place of visit with fine granularity. Our proposed algorithm is based on the dynamic formation of collective personality communities using different languages, opinions, geographical and temporal distributions for finding out optimized equivalent content. We performed extensive empirical experiments involving, real-time streams derived from 0.6 million stream tuples of micro-blog comprising 1945 social person fusion with graph algorithm and feed-forward neural network model as a predictive classification model. Lastly, The framework achieves 62.10% mean average precision on 1,20,000 embeddings on unlabeled users and surprisingly 85.92% increment on the state-of-the-art approach.
Embedding Cardinality Constraints in Neural Link Predictors
Neural link predictors learn distributed representations of entities and relations in a knowledge graph. They are remarkably powerful in the link prediction and knowledge base completion tasks, mainly due to the learned representations that capture important statistical dependencies in the data. Recent works in the area have focused on either designing new scoring functions or incorporating extra information into the learning process to improve the representations. Yet the representations are mostly learned from the observed links between entities, ignoring commonsense or schema knowledge associated with the relations in the graph. A fundamental aspect of the topology of relational data is the cardinality information, which bounds the number of predictions given for a relation between a minimum and maximum frequency. In this paper, we propose a new regularisation approach to incorporate relation cardinality constraints to any existing neural link predictor without affecting their efficiency or scalability. Our regularisation term aims to impose boundaries on the number of predictions with high probability, thus, structuring the embeddings space to respect commonsense cardinality assumptions resulting in better representations. Experimental results on Freebase, WordNet and YAGO show that, given suitable prior knowledge, the proposed method positively impacts the predictive accuracy of downstream link prediction tasks.
Ensemble of Learning Project Productivity in Software Effort Based on Use Case Points
It is well recognized that the project productivity is a key driver in estimating software project effort from Use Case Point size metric at early software development stages. Although, there are few proposed models for predicting productivity, there is no consistent conclusion regarding which model is the superior. Therefore, instead of building a new productivity prediction model, this paper presents a new ensemble construction mechanism applied for software project productivity prediction. Ensemble is an effective technique when performance of base models is poor. We proposed a weighted mean method to aggregate predicted productivities based on average of errors produced by training model. The obtained results show that the using ensemble is a good alternative approach when accuracies of base models are not consistently accurate over different datasets, and when models behave diversely.
The limit of artificial intelligence: Can machines be rational?
This paper studies the question on whether machines can be rational. It observes the existing reasons why humans are not rational which is due to imperfect and limited information, limited and inconsistent processing power through the brain and the inability to optimize decisions and achieve maximum utility. It studies whether these limitations of humans are transferred to the limitations of machines. The conclusion reached is that even though machines are not rational advances in technological developments make these machines more rational. It also concludes that machines can be more rational than humans.
Learning Student Networks via Feature Embedding
Deep convolutional neural networks have been widely used in numerous applications, but their demanding storage and computational resource requirements prevent their applications on mobile devices. Knowledge distillation aims to optimize a portable student network by taking the knowledge from a well-trained heavy teacher network. Traditional teacher-student based methods used to rely on additional fully-connected layers to bridge intermediate layers of teacher and student networks, which brings in a large number of auxiliary parameters. In contrast, this paper aims to propagate information from teacher to student without introducing new variables which need to be optimized. We regard the teacher-student paradigm from a new perspective of feature embedding. By introducing the locality preserving loss, the student network is encouraged to generate the low-dimensional features which could inherit intrinsic properties of their corresponding high-dimensional features from teacher network. The resulting portable network thus can naturally maintain the performance as that of the teacher network. Theoretical analysis is provided to justify the lower computation complexity of the proposed method. Experiments on benchmark datasets and well-trained networks suggest that the proposed algorithm is superior to state-of-the-art teacher-student learning methods in terms of computational and storage complexity.
Deep Heterogeneous Autoencoders for Collaborative Filtering
This paper leverages heterogeneous auxiliary information to address the data sparsity problem of recommender systems. We propose a model that learns a shared feature space from heterogeneous data, such as item descriptions, product tags and online purchase history, to obtain better predictions. Our model consists of autoencoders, not only for numerical and categorical data, but also for sequential data, which enables capturing user tastes, item characteristics and the recent dynamics of user preference. We learn the autoencoder architecture for each data source independently in order to better model their statistical properties. Our evaluation on two MovieLens datasets and an e-commerce dataset shows that mean average precision and recall improve over state-of-the-art methods.
Interpretable Matrix Completion: A Discrete Optimization Approach
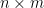
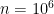

Robust Graph Learning from Noisy Data
Learning graphs from data automatically has shown encouraging performance on clustering and semisupervised learning tasks. However, real data are often corrupted, which may cause the learned graph to be inexact or unreliable. In this paper, we propose a novel robust graph learning scheme to learn reliable graphs from real-world noisy data by adaptively removing noise and errors in the raw data. We show that our proposed model can also be viewed as a robust version of manifold regularized robust PCA, where the quality of the graph plays a critical role. The proposed model is able to boost the performance of data clustering, semisupervised classification, and data recovery significantly, primarily due to two key factors: 1) enhanced low-rank recovery by exploiting the graph smoothness assumption, 2) improved graph construction by exploiting clean data recovered by robust PCA. Thus, it boosts the clustering, semi-supervised classification, and data recovery performance overall. Extensive experiments on image/document clustering, object recognition, image shadow removal, and video background subtraction reveal that our model outperforms the previous state-of-the-art methods.
TechKG: A Large-Scale Chinese Technology-Oriented Knowledge Graph
Spartan Networks: Self-Feature-Squeezing Neural Networks for increased robustness in adversarial settings
Deep learning models are vulnerable to adversarial examples which are input samples modified in order to maximize the error on the system. We introduce Spartan Networks, resistant deep neural networks that do not require input preprocessing nor adversarial training. These networks have an adversarial layer designed to discard some information of the network, thus forcing the system to focus on relevant input. This is done using a new activation function to discard data. The added layer trains the neural network to filter-out usually-irrelevant parts of its input. Our performance evaluation shows that Spartan Networks have a slightly lower precision but report a higher robustness under attack when compared to unprotected models. Results of this study of Adversarial AI as a new attack vector are based on tests conducted on the MNIST dataset.
A Tutorial on Deep Latent Variable Models of Natural Language
There has been much recent, exciting work on combining the complementary strengths of latent variable models and deep learning. Latent variable modeling makes it easy to explicitly specify model constraints through conditional independence properties, while deep learning makes it possible to parameterize these conditional likelihoods with powerful function approximators. While these ‘deep latent variable’ models provide a rich, flexible frameworks for modeling many real-world phenomena, difficulties exist: deep parameterizations of conditional likelihoods usually make posterior inference intractable, and latent variable objectives often complicate backpropagation by introducing points of non-differentiability. This tutorial explores these issues in depth through the lens of variational inference.
Tensor Ensemble Learning for Multidimensional Data
In big data applications, classical ensemble learning is typically infeasible on the raw input data and dimensionality reduction techniques are necessary. To this end, novel framework that generalises classic flat-view ensemble learning to multidimensional tensor-valued data is introduced. This is achieved by virtue of tensor decompositions, whereby the proposed method, referred to as tensor ensemble learning (TEL), decomposes every input data sample into multiple factors which allows for a flexibility in the choice of multiple learning algorithms in order to improve test performance. The TEL framework is shown to naturally compress multidimensional data in order to take advantage of the inherent multi-way data structure and exploit the benefit of ensemble learning. The proposed framework is verified through the application of Higher Order Singular Value Decomposition (HOSVD) to the ETH-80 dataset and is shown to outperform the classical ensemble learning approach of bootstrap aggregating.
Accelerating Multigrid Optimization via SESOP
A merger of two optimization frameworks is introduced: SEquential Subspace OPtimization (SESOP) with the MultiGrid (MG) optimization. At each iteration of the combined algorithm, search directions implied by the coarse-grid correction process of MG are added to the low dimensional search-spaces of SESOP, which include the (preconditioned) gradient and search directions involving the previous iterates (so-called history). The resulting accelerated technique is called SESOP-MG. The {\color{black} asymptotic convergence rate} of the two-level version of SESOP-MG (dubbed SESOP-TG) is studied via Fourier mode analysis for linear problems (i.e., optimization of quadratic functionals). Numerical tests on linear and nonlinear {\color{black} problems} demonstrate the effectiveness of the approach.
Domain Adaptation on Graphs by Learning Graph Topologies: Theoretical Analysis and an Algorithm
Traditional machine learning algorithms assume that the training and test data have the same distribution, while this assumption can be easily violated in real applications. Learning by taking into account the changes in the data distribution is called domain adaptation. In this work, we treat the domain adaptation problem in a graph setting. We consider a source and a target data graph that are constructed with samples drawn from a source and a target data manifold. We study the problem of estimating the unknown labels on the target graph by employing the label information in the source graph and the similarity between the two graphs. We particularly focus on a setting where the target label function is learnt such that its spectrum (frequency content when regarded as a graph signal) is similar to that of the source label function. We first present an overview of the recent field of graph signal processing and introduce concepts such as the Fourier transform on graphs. We then propose a theoretical analysis of domain adaptation over graphs, and present performance bounds relating the target classification error to the properties of the graph topologies and the manifold geometries. Finally, we propose a graph domain adaptation algorithm inspired by our theoretical findings, which estimates the label functions while learning the source and target graph topologies at the same time. Experiments on synthetic and real data sets suggest that the proposed method outperforms baseline approaches.
Like this:
Like Loading…
Related