A Survey on Spark Ecosystem for Big Data Processing
With the explosive increase of big data in industry and academic fields, it is necessary to apply large-scale data processing systems to analysis Big Data. Arguably, Spark is state of the art in large-scale data computing systems nowadays, due to its good properties including generality, fault tolerance, high performance of in-memory data processing, and scalability. Spark adopts a flexible Resident Distributed Dataset (RDD) programming model with a set of provided transformation and action operators whose operating functions can be customized by users according to their applications. It is originally positioned as a fast and general data processing system. A large body of research efforts have been made to make it more efficient (faster) and general by considering various circumstances since its introduction. In this survey, we aim to have a thorough review of various kinds of optimization techniques on the generality and performance improvement of Spark. We introduce Spark programming model and computing system, discuss the pros and cons of Spark, and have an investigation and classification of various solving techniques in the literature. Moreover, we also introduce various data management and processing systems, machine learning algorithms and applications supported by Spark. Finally, we make a discussion on the open issues and challenges for large-scale in-memory data processing with Spark.
Reinforcement learning and inverse reinforcement learning with system 1 and system 2
Inferring a person’s goal from their behavior is an important problem in applications of AI (e.g. automated assistants, recommender systems). The workhorse model for this task is the rational actor model – this amounts to assuming that people have stable reward functions, discount the future exponentially, and construct optimal plans. Under the rational actor assumption techniques such as inverse reinforcement learning (IRL) can be used to infer a person’s goals from their actions. A competing model is the dual-system model. Here decisions are the result of an interplay between a fast, automatic, heuristic-based system 1 and a slower, deliberate, calculating system 2. We generalize the dual system framework to the case of Markov decision problems and show how to compute optimal plans for dual-system agents. We show that dual-system agents exhibit behaviors that are incompatible with rational actor assumption. We show that naive applications of rational-actor IRL to the behavior of dual-system agents can generate wrong inference about the agents’ goals and suggest interventions that actually reduce the agent’s overall utility. Finally, we adapt a simple IRL algorithm to correctly infer the goals of dual system decision-makers. This allows us to make interventions that help, rather than hinder, the dual-system agent’s ability to reach their true goals.
Entropy and Transfer Entropy: The Dow Jones and the build up to the 1997 Asian Crisis
Entropy measures in their various incarnations play an important role in the study of stochastic time series providing important insights into both the correlative and the causative structure of the stochastic relationships between the individual components of a system. Recent applications of entropic techniques and their linear progenitors such as Pearson correlations and Granger causality have have included both normal as well as critical periods in a system’s dynamical evolution. Here I measure the entropy, Pearson correlation and transfer entropy of the intra-day price changes of the Dow Jones Industrial Average in the period immediately leading up to and including the Asian financial crisis and subsequent mini-crash of the DJIA on the 27th October 1997. I use a novel variation of transfer entropy that dynamically adjusts to the arrival rate of individual prices and does not require the binning of data to show that quite different relationships emerge from those given by the conventional Pearson correlations between equities. These preliminary results illustrate how this modified form of the TE compares to results using Pearson correlation.
Castor: Contextual IoT Time Series Data and Model Management at Scale
We demonstrate Castor, a cloud-based system for contextual IoT time series data and model management at scale. Castor is designed to assist Data Scientists in (a) exploring and retrieving all relevant time series and contextual information that is required for their predictive modelling tasks; (b) seamlessly storing and deploying their predictive models in a cloud production environment; (c) monitoring the performance of all predictive models in productions and (semi-)automatically retraining them in case of performance deterioration. The main features of Castor are: (1) an efficient pipeline for ingesting IoT time series data in real time; (2) a scalable, hybrid data management service for both time series and contextual data; (3) a versatile semantic model for contextual information which can be easily adopted to different application domains; (4) an abstract framework for developing and storing predictive models in R or Python; (5) deployment services which automatically train and/or score predictive models upon user-defined conditions. We demonstrate Castor for a real-world Smart Grid use case and discuss how it can be adopted to other application domains such as Smart Buildings, Telecommunication, Retail or Manufacturing.
A Hierarchical Spatio-Temporal Statistical Model for Physical Systems
In this paper, we extend and analyze a Bayesian hierarchical spatio-temporal model for physical systems. A novelty is to model the discrepancy between the output of a computer simulator for a physical process and the actual process values with a multivariate random walk. For computational efficiency, linear algebra for bandwidth limited matrices is utilized, and first-order emulator inference allows for the fast emulation of a numerical partial differential equation (PDE) solver. A test scenario from a physical system motivated by glaciology is used to examine the speed and accuracy of the computational methods used, in addition to the viability of modeling assumptions. We conclude by discussing how the model and associated methodology can be applied in other physical contexts besides glaciology.
Model-Based Reinforcement Learning in Contextual Decision Processes
We study the sample complexity of model-based reinforcement learning in general contextual decision processes. We design new algorithms for RL with an abstract model class and analyze their statistical properties. Our algorithms have sample complexity governed by a new structural parameter called the witness rank, which we show to be small in several settings of interest, including Factored MDPs and reactive POMDPs. We also show that the witness rank of a problem is never larger than the recently proposed Bellman rank parameter governing the sample complexity of the model-free algorithm OLIVE (Jiang et al., 2017), the only other provably sample efficient algorithm at this level of generality. Focusing on the special case of Factored MDPs, we prove an exponential lower bound for all model-free approaches, including OLIVE, which when combined with our algorithmic results demonstrates exponential separation between model-based and model-free RL in some rich-observation settings.
Bitcoin: A Natural Oligopoly
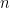


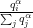
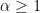
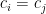


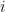
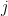



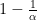

How the Softmax Output is Misleading for Evaluating the Strength of Adversarial Examples
Even before deep learning architectures became the de facto models for complex computer vision tasks, the softmax function was, given its elegant properties, already used to analyze the predictions of feedforward neural networks. Nowadays, the output of the softmax function is also commonly used to assess the strength of adversarial examples: malicious data points designed to fail machine learning models during the testing phase. However, in this paper, we show that it is possible to generate adversarial examples that take advantage of some properties of the softmax function, leading to undesired outcomes when interpreting the strength of the adversarial examples at hand. Specifically, we argue that the output of the softmax function is a poor indicator when the strength of an adversarial example is analyzed and that this indicator can be easily tricked by already existing methods for adversarial example generation.
Recent Advances in Open Set Recognition: A Survey
In real-world recognition/classification tasks, limited by various objective factors, it is usually difficult to collect training samples to exhaust all classes when training a recognizer or classifier. A more realistic scenario is open set recognition (OSR), where incomplete knowledge of the world exists at training time, and unknown classes can be submitted to an algorithm during testing, requiring the classifiers not only to accurately classify the seen classes, but also to effectively deal with the unseen ones. This paper provides a comprehensive survey of existing open set recognition techniques covering various aspects ranging from related definitions, representations of models, datasets, experiment setup and evaluation metrics. Furthermore, we briefly analyze the relationships between OSR and its related tasks including zero-shot, one-shot (few-shot) recognition/learning techniques, classification with reject option, and so forth. Additionally, we also overview the open world recognition which can be seen as a natural extension of OSR. Importantly, we highlight the limitations of existing approaches and point out some promising subsequent research directions in this field.
Progressive Feature Alignment for Unsupervised Domain Adaptation
Unsupervised domain adaptation (UDA) transfers knowledge from a label-rich source domain to a fully-unlabeled target domain. To tackle this task, recent approaches resort to discriminative domain transfer in virtue of pseudo-labels to enforce the class-level distribution alignment across the source and target domains. These methods, however, are vulnerable to the error accumulation and thus incapable of preserving cross-domain category consistency, as the pseudo-labeling accuracy is not guaranteed explicitly. In this paper, we propose the Progressive Feature Alignment Network (PFAN) to align the discriminative features across domains progressively and effectively, via exploiting the intra-class variation in the target domain. To be specific, we first develop an Easy-to-Hard Transfer Strategy (EHTS) and an Adaptive Prototype Alignment (APA) step to train our model iteratively and alternatively. Moreover, upon observing that a good domain adaptation usually requires a non-saturated source classifier, we consider a simple yet efficient way to retard the convergence speed of the source classification loss by further involving a temperature variate into the soft-max function. The extensive experimental results reveal that the proposed PFAN exceeds the state-of-the-art performance on three UDA datasets.
Neural Collective Entity Linking
Entity Linking aims to link entity mentions in texts to knowledge bases, and neural models have achieved recent success in this task. However, most existing methods rely on local contexts to resolve entities independently, which may usually fail due to the data sparsity of local information. To address this issue, we propose a novel neural model for collective entity linking, named as NCEL. NCEL applies Graph Convolutional Network to integrate both local contextual features and global coherence information for entity linking. To improve the computation efficiency, we approximately perform graph convolution on a subgraph of adjacent entity mentions instead of those in the entire text. We further introduce an attention scheme to improve the robustness of NCEL to data noise and train the model on Wikipedia hyperlinks to avoid overfitting and domain bias. In experiments, we evaluate NCEL on five publicly available datasets to verify the linking performance as well as generalization ability. We also conduct an extensive analysis of time complexity, the impact of key modules, and qualitative results, which demonstrate the effectiveness and efficiency of our proposed method.
Equality of Voice: Towards Fair Representation in Crowdsourced Top-K Recommendations
To help their users to discover important items at a particular time, major websites like Twitter, Yelp, TripAdvisor or NYTimes provide Top-K recommendations (e.g., 10 Trending Topics, Top 5 Hotels in Paris or 10 Most Viewed News Stories), which rely on crowdsourced popularity signals to select the items. However, different sections of a crowd may have different preferences, and there is a large silent majority who do not explicitly express their opinion. Also, the crowd often consists of actors like bots, spammers, or people running orchestrated campaigns. Recommendation algorithms today largely do not consider such nuances, hence are vulnerable to strategic manipulation by small but hyper-active user groups. To fairly aggregate the preferences of all users while recommending top-K items, we borrow ideas from prior research on social choice theory, and identify a voting mechanism called Single Transferable Vote (STV) as having many of the fairness properties we desire in top-K item (s)elections. We develop an innovative mechanism to attribute preferences of silent majority which also make STV completely operational. We show the generalizability of our approach by implementing it on two different real-world datasets. Through extensive experimentation and comparison with state-of-the-art techniques, we show that our proposed approach provides maximum user satisfaction, and cuts down drastically on items disliked by most but hyper-actively promoted by a few users.
Privacy-Preserving Collaborative Prediction using Random Forests
We study the problem of privacy-preserving machine learning (PPML) for ensemble methods, focusing our effort on random forests. In collaborative analysis, PPML attempts to solve the conflict between the need for data sharing and privacy. This is especially important in privacy sensitive applications such as learning predictive models for clinical decision support from EHR data from different clinics, where each clinic has a responsibility for its patients’ privacy. We propose a new approach for ensemble methods: each entity learns a model, from its own data, and then when a client asks the prediction for a new private instance, the answers from all the locally trained models are used to compute the prediction in such a way that no extra information is revealed. We implement this approach for random forests and we demonstrate its high efficiency and potential accuracy benefit via experiments on real-world datasets, including actual EHR data.
Sequential Neural Methods for Likelihood-free Inference
Likelihood-free inference refers to inference when a likelihood function cannot be explicitly evaluated, which is often the case for models based on simulators. Most of the literature is based on sample-based `Approximate Bayesian Computation’ methods, but recent work suggests that approaches based on deep neural conditional density estimators can obtain state-of-the-art results with fewer simulations. The neural approaches vary in how they choose which simulations to run and what they learn: an approximate posterior or a surrogate likelihood. This work provides some direct controlled comparisons between these choices.
SpotTune: Transfer Learning through Adaptive Fine-tuning
Transfer learning, which allows a source task to affect the inductive bias of the target task, is widely used in computer vision. The typical way of conducting transfer learning with deep neural networks is to fine-tune a model pre-trained on the source task using data from the target task. In this paper, we propose an adaptive fine-tuning approach, called SpotTune, which finds the optimal fine-tuning strategy per instance for the target data. In SpotTune, given an image from the target task, a policy network is used to make routing decisions on whether to pass the image through the fine-tuned layers or the pre-trained layers. We conduct extensive experiments to demonstrate the effectiveness of the proposed approach. Our method outperforms the traditional fine-tuning approach on 12 out of 14 standard datasets.We also compare SpotTune with other state-of-the-art fine-tuning strategies, showing superior performance. On the Visual Decathlon datasets, our method achieves the highest score across the board without bells and whistles.
Distinguishing correlation from causation using genome-wide association studies
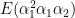
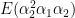



The Reduced Dynamic Chain Event Graph
In this paper we introduce a new class of probabilistic graphical models called the Reduced Dynamic Chain Event Graph (RDCEG) which is a novel mixture of a Chain Event Graph (CEG) and a semi-Markov process (SMP). It has been demonstrated that many real-world scenarios, particularly in the domain of public health and security, can be modelled as an unfolding of events in the life histories of individuals. Our interest not only lies in the future trajectories of an individual with a specified history and set of characteristics but also in the timescale associated with these developments. Such information is critical in developing suitable interventions and informs the prioritisation of policy decisions. The RDCEG was born out of the need for such a model. It is a coloured graph which inherits useful properties like fast conjugate model selection, conditional independence interrogations and a support for causal interventions from the family of probabilistic graphical models. Its novelty lies in its underlying semi-Markov structure which offers the flexibility of the holding time at each state being any arbitrary distribution. We demonstrate this new decision support system with a simulated intervention to reduce falls in the elderly.
Linear Programming for Decision Processes with Partial Information
Markov Decision Processes (MDPs) are stochastic optimization problems that model situations where a decision maker controls a system based on its state. Partially observed Markov decision processes (POMDPs) are generalizations of MDPs where the decision maker has only partial information on the state of the system.Decomposable POMDPs are specific cases of POMDPs that enable to model systems with several components. Such problems naturally model a wide range of applications such as predictive maintenance.Finding an optimal policy for a POMDP is NP-hard and practically challenging. We introduce a mixed integer linear programming (MILP) formulation for POMDPs, as well as valid inequalities that are based on a probabilistic interpretation of the dependence between variables. Solving decomposable POMDPs is especially challenging due to the curse of dimensionality. Leveraging our MILP formulation for POMDPs, we introduce a linear program based on ‘fluid formulation’ for decomposable POMDPs, that provides both a bound on the optimal value and a practically efficient heuristic to find a good policy. Numerical experiments show the efficiency of our approaches to POMDPs and decomposable POMDPs.
Stochastic Gradient Descent Optimizes Over-parameterized Deep ReLU Networks
We study the problem of training deep neural networks with Rectified Linear Unit (ReLU) activiation function using gradient descent and stochastic gradient descent. In particular, we study the binary classification problem and show that for a broad family of loss functions, with proper random weight initialization, both gradient descent and stochastic gradient descent can find the global minima of the training loss for an over-parameterized deep ReLU network, under mild assumption on the training data. The key idea of our proof is that Gaussian random initialization followed by (stochastic) gradient descent produces a sequence of iterates that stay inside a small perturbation region centering around the initial weights, in which the empirical loss function of deep ReLU networks enjoys nice local curvature properties that ensure the global convergence of (stochastic) gradient descent. Our theoretical results shed light on understanding the optimization of deep learning, and pave the way to study the optimization dynamics of training modern deep neural networks.
• Designing nearly tight window for improving time-frequency masking• Priming Deep Neural Networks with Synthetic Faces for Enhanced Performance• Learning Better Features for Face Detection with Feature Fusion and Segmentation Supervision• Multi-scale aggregation of phase information for reducing computational cost of CNN based DOA estimation• A Simple Proof for the Cycle Double Cover Conjecture• Economics of disagreement — financial intuition for the Rényi divergence• Diffusion geometry approach to efficiently remove electrical stimulation artifacts in intracranial electroencephalography• Blind Deconvolution using Modulated Inputs• Artificial Color Constancy via GoogLeNet with Angular Loss Function• Intermediate Level Adversarial Attack for Enhanced Transferability• Fading of collective attention shapes the evolution of linguistic variants• Double Refinement Network for Efficient Indoor Monocular Depth Estimation• Stable Opponent Shaping in Differentiable Games• Input-to-state stability of unbounded bilinear control systems• Supplemental Material For ‘Primal-Dual Q-Learning Framework for LQR Design’• A Unified Approach to Coupling SDEs driven by Lévy Noise and Some Applications• Higher significance with smaller samples: A modified Sequential Probability Ratio Test• VQA with no questions-answers training• MimicGAN: Corruption-Mimicking for Blind Image Recovery & Adversarial Defense• The Economic End of Life of Electrochemical Energy Storage• Fast classification of small X-ray diffraction datasets using data augmentation and deep neural networks• Adversarial Removal of Gender from Deep Image Representations• Are pre-trained CNNs good feature extractors for anomaly detection in surveillance videos?• A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos• Triangulations of the product of spheres with few vertices• Tight Approximation Ratio for Minimum Maximal Matching• Joint association and classification analysis of multi-view data• Finding a Needle in the Haystack: Attention-Based Classification of High Resolution Microscopy Images• Probability Distributions on Partially Ordered Sets and Network Security Games• On Stanley’s Conjecture on k-fold Acyclic Complexes• How much data are needed to calibrate and test agent-based models?• Minimum Guesswork with an Unreliable Oracle• Extended formulations from communication protocols in output-efficient time• On compact representations of Voronoi cells of lattices• Exact Byzantine Consensus Under Local-Broadcast Model• Seeing in the dark with recurrent convolutional neural networks• Breaking symmetries to rescue Sum of Squares: The case of makespan scheduling• Neural Machine Translation with Adequacy-Oriented Learning• Predicting Electron-Ionization Mass Spectrometry using Neural Networks• Adjustable Real-time Style Transfer• Adaptive Re-ranking of Deep Feature for Person Re-identification• High-Level Strategy Selection under Partial Observability in StarCraft: Brood War• Unsupervised Single Image Deraining with Self-supervised Constraints• Trajectory Modeling and Prediction with Waypoint Information Using a Conditionally Markov Sequence• Population-aware Hierarchical Bayesian Domain Adaptation• Electric Vehicle Charging Station Network Equilibrium Models and Pricing Schemes• Colouring of generalized signed planar graphs• Urban Driving with Multi-Objective Deep Reinforcement Learning• A refinement of choosability of graphs• Real-Time 6D Object Pose Estimation on CPU• Graph-Adaptive Pruning for Efficient Inference of Convolutional Neural Networks• Measuring Depression Symptom Severity from Spoken Language and 3D Facial Expressions• A Lagrangian Decomposition Algorithm for Robust Green Transportation Location Problem• Learning to Attend Relevant Regions in Videos from Eye Fixations• On an Extension of Stochastic Approximation EM Algorithm for Incomplete Data Problems• SuperNeurons: FFT-based Gradient Sparsification in the Distributed Training of Deep Neural Networks• Randomized Rank-Revealing UZV Decomposition for Low-Rank Approximation of Matrices• M2E-Try On Net: Fashion from Model to Everyone• Contextualized Non-local Neural Networks for Sequence Learning• Cyclotomic factors of necklace polynomials• On-off Switched Interference Alignment for Diversity Multiplexing Tradeoff Improvement in the 2-User X-Network with Two Antennas• The value of forecasts: Quantifying the economic gains of accurate quarter-hourly electricity price forecasts• Scene Text Detection with Supervised Pyramid Context Network• Branching rules for Unitary and Symplectic matrices• On Sparse Graph Fourier Transform• Convolutional Spatial Attention Model for Reading Comprehension with Multiple-Choice Questions• A Novel Integrated Framework for Learning both Text Detection and Recognition• Tetris• Unsupervised Multimodal Representation Learning across Medical Images and Reports• Neural Networks with Activation Networks• Multi Task Deep Morphological Analyzer: Context Aware Joint Morphological Tagging and Lemma Prediction• Angular Triplet-Center Loss for Multi-view 3D Shape Retrieval• Benchmarking Inverse Rashba-Edelstein Magnetoelectric Devices for Neuromorphic Computing• A Deep Tree-Structured Fusion Model for Single Image Deraining• Compensated Integrated Gradients to Reliably Interpret EEG Classification• Synetgy: Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs• Passivity-Based Generalization of Primal-Dual Dynamics for Non-Strictly Convex Cost Functions• On Intercept Probability Minimization under Sparse Random Linear Network Coding• A Fingerprint Indexing Method Based on Minutia Descriptor and Clustering• On some identities in law involving exponential functionals of Brownian motion and Cauchy variable• Optimal design of experiments for a lithium-ion cell: parameters identification of a single particle model with electrolyte dynamics• PersEmoN: A Deep Network for Joint Analysis of Apparent Personality, Emotion and Their Relationship• On the complexity of detecting positive eigenvectors of nonlinear cone maps• Retina U-Net: Embarrassingly Simple Exploitation of Segmentation Supervision for Medical Object Detection• A linear programming approach to Markov reward error bounds for queueing networks• Computational Decomposition of Style for Controllable and Enhanced Style Transfer• On the Proximity of Markets with Integral Equilibria• Graph Refinement based Tree Extraction using Mean-Field Networks and Graph Neural Networks• A state-space approach to sparse dynamic network reconstruction• Applying Itô calculus to Otto calculus• Surrogate-assisted parallel tempering for Bayesian neural learning• Improving PSO Global Method for Feature Selection According to Iterations Global Search and Chaotic Theory• N-vicinity method and 1D Ising Model• Inline Detection of Domain Generation Algorithms with Context-Sensitive Word Embeddings• The three-speed ballistic annihilation threshold is 1/4• Toplogical derivative for nonlinear magnetostatic problem• A result on power moments of Lévy-type perpetuities and its application to the $L_p$-convergence of Biggins’ martingales in branching Lévy processes• Maximal Positive Invariant Set Determination for Transient Stability Assessment in Power Systems• Marginal Weighted Maximum Log-likelihood for Efficient Learning of Perturb-and-Map models• AttentionMask: Attentive, Efficient Object Proposal Generation Focusing on Small Objects• Media-Based Modulation for Future Wireless Systems: A Tutorial• Disordered XY model: effective medium theory and beyond• Semantic Stereo for Incidental Satellite Images• Gated Context Aggregation Network for Image Dehazing and Deraining• An exactly solvable continuous-time Derrida–Retaux~model• Additive Approximation of Generalized Turán Questions• Chan-Vese Reformulation for Selective Image Segmentation• Network-Constrained Robust Unit Commitment for Hybrid AC/DC Transmission Grids• The Best of Both Worlds: Lexical Resources To Improve Low-Resource Part-of-Speech Tagging• Using AI to Design Stone Jewelry• Dynamic-Net: Tuning the Objective Without Re-training• MATMPC – A MATLAB Based Toolbox for Real-time Nonlinear Model Predictive Control• Tablet-based Information System for Commercial Air-craft: Onboard Context-Sensitive Information System (OCSIS)• Regularizing by the Variance of the Activations’ Sample-Variances• Electron effective mass and electronic structure and in nonstoichiometric a-IGZO films• Portmanteau test for the asymmetric power GARCH model when the power is unknown• Overcoming low-utility facets for complex answer retrieval• Short note on Randić energy• Reconstruction of jointly sparse vectors via manifold optimization• High Dimensional Linear GMM• Statistical Physics of Language Maps in the USA• Learning Quadratic Games on Networks• Artificial Intelligence-Defined 5G Radio Access Networks• A LQD-RKHS-based distribution-to-distribution regression method and its application to restore distributions of missing SHM data• Multi-layered Graph Embedding with Graph Convolution Networks• Bilinear control of evolution equations of parabolic type• Fast mean-reversion asymptotics for large portfolios of stochastic volatility models• $k$-Cut: A Simple Approximately-Uniform Method for Sampling Ballots in Post-Election Audits• Adversarial Classifier for Imbalanced Problems• Sharp non asymptotic oracle inequalities for non parametric computerized tomography model• Locally-Consistent Deformable Convolution Networks for Fine-Grained Action Detection• Neural Machine Translation based Word Transduction Mechanisms for Low-Resource Languages• Effectiveness of 3VQM in Capturing Depth Inconsistencies• Model instability in predictive exchange rate regressions• Trajectory PHD and CPHD filters• Coding of 3D Videos Based on Visual Discomfort• Early Fusion for Goal Directed Robotic Vision• Boosting in Image Quality Assessment• Multi-Panel Kendall Plot in Light of an ROC Curve Analysis Applied to Measuring Dependence• Recognizing Disguised Faces in the Wild• fastMRI: An Open Dataset and Benchmarks for Accelerated MRI• Integrating Reinforcement Learning to Self Training for Pulmonary Nodule Segmentation in Chest X-rays• Dispatchable Virtual Oscillator Control for Decentralized Inverter-dominated Power Systems: Analysis and Experiments• CoPaR: An Efficient Generic Partition Refiner• Resource Mention Extraction for MOOC Discussion Forums• Decoding Staircase Codes with Marked Bits• Approximability Models and Optimal System Identification• Efficient nonmyopic active search with applications in drug and materials discovery• Nonlinear quantum transport of light in a cold atomic cloud• Rethinking ImageNet Pre-training• Computing Convex Hulls in the Affine Building of SL_d• HAQ: Hardware-Aware Automated Quantization
Like this:
Like Loading…
Related