The Information Flow Foundation for Conceptual Knowledge Organization
The sharing of ontologies between diverse communities of discourse allows them to compare their own information structures with that of other communities that share a common terminology and semantics – ontology sharing facilitates interoperability between online knowledge organizations. This paper demonstrates how ontology sharing is formalizable within the conceptual knowledge model of Information Flow (IF). Information Flow indirectly represents sharing through a specifiable, ontology extension hierarchy augmented with synonymic type equivalencing – two ontologies share terminology and meaning through a common generic ontology that each extends. Using the paradigm of participant community ontologies formalized as IF logics, a common shared extensible ontology formalized as an IF theory, participant community specification links from the common ontology to the participating community ontology formalizable as IF theory interpretations, this paper argues that ontology sharing is concentrated in a virtual ontology of community connections, and demonstrates how this virtual ontology is computable as the fusion of the participant ontologies – the quotient of the sum of the participant ontologies modulo the ontological sharing structure.
LAMVI-2: A Visual Tool for Comparing and Tuning Word Embedding Models
Tuning machine learning models, particularly deep learning architectures, is a complex process. Automated hyperparameter tuning algorithms often depend on specific optimization metrics. However, in many situations, a developer trades one metric against another: accuracy versus overfitting, precision versus recall, smaller models and accuracy, etc. With deep learning, not only are the model’s representations opaque, the model’s behavior when parameters ‘knobs’ are changed may also be unpredictable. Thus, picking the ‘best’ model often requires time-consuming model comparison. In this work, we introduce LAMVI-2, a visual analytics system to support a developer in comparing hyperparameter settings and outcomes. By focusing on word-embedding models (‘deep learning for text’) we integrate views to compare both high-level statistics as well as internal model behaviors (e.g., comparing word ‘distances’). We demonstrate how developers can work with LAMVI-2 to more quickly and accurately narrow down an appropriate and effective application-specific model.
Towards a Ranking Model for Semantic Layers over Digital Archives
Archived collections of documents (like newspaper archives) serve as important information sources for historians, journalists, sociologists and other interested parties. Semantic Layers over such digital archives allow describing and publishing metadata and semantic information about the archived documents in a standard format (RDF), which in turn can be queried through a structured query language (e.g., SPARQL). This enables to run advanced queries by combining metadata of the documents (like publication date) and content-based semantic information (like entities mentioned in the documents). However, the results returned by structured queries can be numerous and also they all equally match the query. Thus, there is the need to rank these results in order to promote the most important ones. In this paper, we focus on this problem and propose a ranking model that considers and combines: i) the relativeness of documents to entities, ii) the timeliness of documents, and iii) the relations among the entities.
Ranking Archived Documents for Structured Queries on Semantic Layers
Archived collections of documents (like newspaper and web archives) serve as important information sources in a variety of disciplines, including Digital Humanities, Historical Science, and Journalism. However, the absence of efficient and meaningful exploration methods still remains a major hurdle in the way of turning them into usable sources of information. A semantic layer is an RDF graph that describes metadata and semantic information about a collection of archived documents, which in turn can be queried through a semantic query language (SPARQL). This allows running advanced queries by combining metadata of the documents (like publication date) and content-based semantic information (like entities mentioned in the documents). However, the results returned by such structured queries can be numerous and moreover they all equally match the query. In this paper, we deal with this problem and formalize the task of ‘ranking archived documents for structured queries on semantic layers’. Then, we propose two ranking models for the problem at hand which jointly consider: i) the relativeness of documents to entities, ii) the timeliness of documents, and iii) the temporal relations among the entities. The experimental results on a new evaluation dataset show the effectiveness of the proposed models and allow us to understand their limitations
CatBoost: gradient boosting with categorical features support
In this paper we present CatBoost, a new open-sourced gradient boosting library that successfully handles categorical features and outperforms existing publicly available implementations of gradient boosting in terms of quality on a set of popular publicly available datasets. The library has a GPU implementation of learning algorithm and a CPU implementation of scoring algorithm, which are significantly faster than other gradient boosting libraries on ensembles of similar sizes.
Superensemble Classifier for Improving Predictions in Imbalanced Datasets
Learning from an imbalanced dataset is a tricky proposition. Because these datasets are biased towards one class, most existing classifiers tend not to perform well on minority class examples. Conventional classifiers usually aim to optimize the overall accuracy without considering the relative distribution of each class. This article presents a superensemble classifier, to tackle and improve predictions in imbalanced classification problems, that maps Hellinger distance decision trees (HDDT) into radial basis function network (RBFN) framework. Regularity conditions for universal consistency and the idea of parameter optimization of the proposed model are provided. The proposed distribution-free model can be applied for feature selection cum imbalanced classification problems. We have also provided enough numerical evidence using various real-life data sets to assess the performance of the proposed model. Its effectiveness and competitiveness with respect to different state-of-the-art models are shown.
Automating Generation of Low Precision Deep Learning Operators
State of the art deep learning models have made steady progress in the fields of computer vision and natural language processing, at the expense of growing model sizes and computational complexity. Deploying these models on low power and mobile devices poses a challenge due to their limited compute capabilities and strict energy budgets. One solution that has generated significant research interest is deploying highly quantized models that operate on low precision inputs and weights less than eight bits, trading off accuracy for performance. These models have a significantly reduced memory footprint (up to 32x reduction) and can replace multiply-accumulates with bitwise operations during compute intensive convolution and fully connected layers. Most deep learning frameworks rely on highly engineered linear algebra libraries such as ATLAS or Intel’s MKL to implement efficient deep learning operators. To date, none of the popular deep learning directly support low precision operators, partly due to a lack of optimized low precision libraries. In this paper we introduce a work flow to quickly generate high performance low precision deep learning operators for arbitrary precision that target multiple CPU architectures and include optimizations such as memory tiling and vectorization. We present an extensive case study on low power ARM Cortex-A53 CPU, and show how we can generate 1-bit, 2-bit convolutions with speedups up to 16x over an optimized 16-bit integer baseline and 2.3x better than handwritten implementations.
RELF: Robust Regression Extended with Ensemble Loss Function
Ensemble techniques are powerful approaches that combine several weak learners to build a stronger one. As a meta-learning framework, ensemble techniques can easily be applied to many machine learning methods. Inspired by ensemble techniques, in this paper we propose an ensemble loss functions applied to a simple regressor. We then propose a half-quadratic learning algorithm in order to find the parameter of the regressor and the optimal weights associated with each loss function. Moreover, we show that our proposed loss function is robust in noisy environments. For a particular class of loss functions, we show that our proposed ensemble loss function is Bayes consistent and robust. Experimental evaluations on several datasets demonstrate that our proposed ensemble loss function significantly improves the performance of a simple regressor in comparison with state-of-the-art methods.
Generalised framework for multi-criteria method selection
Scalable Distributed DNN Training using TensorFlow and CUDA-Aware MPI: Characterization, Designs, and Performance Evaluation
TensorFlow has been the most widely adopted Machine/Deep Learning framework. However, little exists in the literature that provides a thorough understanding of the capabilities which TensorFlow offers for the distributed training of large ML/DL models that need computation and communication at scale. Most commonly used distributed training approaches for TF can be categorized as follows: 1) Google Remote Procedure Call (gRPC), 2) gRPC+X: X=(InfiniBand Verbs, Message Passing Interface, and GPUDirect RDMA), and 3) No-gRPC: Baidu Allreduce with MPI, Horovod with MPI, and Horovod with NVIDIA NCCL. In this paper, we provide an in-depth performance characterization and analysis of these distributed training approaches on various GPU clusters including the Piz Daint system (6 on Top500). We perform experiments to gain novel insights along the following vectors: 1) Application-level scalability of DNN training, 2) Effect of Batch Size on scaling efficiency, 3) Impact of the MPI library used for no-gRPC approaches, and 4) Type and size of DNN architectures. Based on these experiments, we present two key insights: 1) Overall, No-gRPC designs achieve better performance compared to gRPC-based approaches for most configurations, and 2) The performance of No-gRPC is heavily influenced by the gradient aggregation using Allreduce. Finally, we propose a truly CUDA-Aware MPI Allreduce design that exploits CUDA kernels and pointer caching to perform large reductions efficiently. Our proposed designs offer 5-17X better performance than NCCL2 for small and medium messages, and reduces latency by 29% for large messages. The proposed optimizations help Horovod-MPI to achieve approximately 90% scaling efficiency for ResNet-50 training on 64 GPUs. Further, Horovod-MPI achieves 1.8X and 3.2X higher throughput than the native gRPC method for ResNet-50 and MobileNet, respectively, on the Piz Daint cluster.
Promoting Distributed Trust in Machine Learning and Computational Simulation via a Blockchain Network
Policy decisions are increasingly dependent on the outcomes of simulations and/or machine learning models. The ability to share and interact with these outcomes is relevant across multiple fields and is especially critical in the disease modeling community where models are often only accessible and workable to the researchers that generate them. This work presents a blockchain-enabled system that establishes a decentralized trust between parties involved in a modeling process. Utilizing the OpenMalaria framework, we demonstrate the ability to store, share and maintain auditable logs and records of each step in the simulation process, showing how to validate results generated by computing workers. We also show how the system monitors worker outputs to rank and identify faulty workers via comparison to nearest neighbors or historical reward spaces as a means of ensuring model quality.
Optimizing Capacitated Vehicle Scheduling with Time Windows: A Case Study of RMC Delivery
Ready Mixed Concrete Delivery Problem (RMCDP) is a multi-objective multi-constraint dynamic combinatorial optimization problem. From the operational research prospective, it is a real life logistic problem that is hard to be solved with large instances. In RMCDP, there is a need to optimize the Ready Mixed Concrete ( RMC) delivery by predetermining an optimal schedule for the sites-trips assignments that adheres to strict time, distance, and capacity constraints. This optimization process is subjected to a domain of objectives ranging from achieving maximum revenue to minimizing the operational cost. In this paper, we analyze the problem based on realistic assumptions and introduce its theoretical foundation. We derive a complete projection of the problem in graph theory, and prove its NP-Completeness in the complexity theory, which constitutes the base of the proposed approaches. The first approach is a graph-based greedy algorithm that deploys dynamic graph weights and has polynomial time complexity. The second approach is a heuristic-based algorithm coupled with the dynamic programming and is referred to as Priority Algorithm. This algorithm is carefully designed to address the RMCDP dynamic characteristic, and satisfies its multi-objectivity. In comparison with the state-of-arts approaches, our algorithm achieves high feasibility rate, lower design complexity, and significantly lower computational time to find optimal or very slightly suboptimal solutions.
SQUAREM: An R Package for Off-the-Shelf Acceleration of EM, MM and Other EM-like Monotone Algorithms
Beyond A/B Testing: Sequential Randomization for Developing Interventions in Scaled Digital Learning Environments
Randomized experiments ensure robust causal inference that are critical to effective learning analytics research and practice. However, traditional randomized experiments, like A/B tests, are limiting in large scale digital learning environments. While traditional experiments can accurately compare two treatment options, they are less able to inform how to adapt interventions to continually meet learners’ diverse needs. In this work, we introduce a trial design for developing adaptive interventions in scaled digital learning environments — the sequential randomized trial (SRT). With the goal of improving learner experience and developing interventions that benefit all learners at all times, SRTs inform how to sequence, time, and personalize interventions. In this paper, we provide an overview of SRTs, and we illustrate the advantages they hold compared to traditional experiments. We describe a novel SRT run in a large scale data science MOOC. The trial results contextualize how learner engagement can be addressed through inclusive culturally targeted reminder emails. We also provide practical advice for researchers who aim to run their own SRTs to develop adaptive interventions in scaled digital learning environments.
Magnitude: A Fast, Efficient Universal Vector Embedding Utility Package
Vector space embedding models like word2vec, GloVe, fastText, and ELMo are extremely popular representations in natural language processing (NLP) applications. We present Magnitude, a fast, lightweight tool for utilizing and processing embeddings. Magnitude is an open source Python package with a compact vector storage file format that allows for efficient manipulation of huge numbers of embeddings. Magnitude performs common operations up to 60 to 6,000 times faster than Gensim. Magnitude introduces several novel features for improved robustness like out-of-vocabulary lookups.
Lossless (and Lossy) Compression of Random Forests
Ensemble methods are among the state-of-the-art predictive modeling approaches. Applied to modern big data, these methods often require a large number of sub-learners, where the complexity of each learner typically grows with the size of the dataset. This phenomenon results in an increasing demand for storage space, which may be very costly. This problem mostly manifests in a subscriber based environment, where a user-specific ensemble needs to be stored on a personal device with strict storage limitations (such as a cellular device). In this work we introduce a novel method for lossless compression of tree-based ensemble methods, focusing on random forests. Our suggested method is based on probabilistic modeling of the ensemble’s trees, followed by model clustering via Bregman divergence. This allows us to find a minimal set of models that provides an accurate description of the trees, and at the same time is small enough to store and maintain. Our compression scheme demonstrates high compression rates on a variety of modern datasets. Importantly, our scheme enables predictions from the compressed format and a perfect reconstruction of the original ensemble. In addition, we introduce a theoretically sound lossy compression scheme, which allows us to control the trade-off between the distortion and the coding rate.
Online Fault Classification in HPC Systems through Machine Learning
As High-Performance Computing (HPC) systems strive towards exascale goals, studies suggest that they will experience excessive failure rates, mainly due to the massive parallelism that they require. Long-running exascale computations would be severely affected by a variety of failures, which could occur as often as every few minutes. Therefore, detecting and classifying faults in HPC systems as they occur and initiating corrective actions through appropriate resiliency techniques before they can transform into failures will be essential for operating them. In this paper, we propose a fault classification method for HPC systems based on machine learning and designed for live streamed data. Our solution is cast within realistic operating constraints, especially those deriving from the desire to operate the classifier in an online manner. Our results show that almost perfect classification accuracy can be reached for different fault types with low computational overhead and minimal delay. Our study is based on a dataset, now publicly available, that was acquired by injecting faults to an in-house experimental HPC system.
Deep Poisson gamma dynamical systems
We develop deep Poisson-gamma dynamical systems (DPGDS) to model sequentially observed multivariate count data, improving previously proposed models by not only mining deep hierarchical latent structure from the data, but also capturing both first-order and long-range temporal dependencies. Using sophisticated but simple-to-implement data augmentation techniques, we derived closed-form Gibbs sampling update equations by first backward and upward propagating auxiliary latent counts, and then forward and downward sampling latent variables. Moreover, we develop stochastic gradient MCMC inference that is scalable to very long multivariate count time series. Experiments on both synthetic and a variety of real-world data demonstrate that the proposed model not only has excellent predictive performance, but also provides highly interpretable multilayer latent structure to represent hierarchical and temporal information propagation.
Spectral Analysis of High-dimensional Time Series
A useful approach for analysing multiple time series is via characterising their spectral density matrix as the frequency domain analog of the covariance matrix. When the dimension of the time series is large compared to their length, regularisation based methods can overcome the curse of dimensionality, but the existing ones lack theoretical justification. This paper develops the first non-asymptotic result for characterising the difference between the sample and population versions of the spectral density matrix, allowing one to justify a range of high-dimensional models for analysing time series. As a concrete example, we apply this result to establish the convergence of the smoothed periodogram estimators and sparse estimators of the inverse of spectral density matrices, namely precision matrices. These results, novel in the frequency domain time series analysis, are corroborated by simulations and an analysis of the Google Flu Trends data.
AutoParallel: A Python module for automatic parallelization and distributed execution of affine loop nests
The last improvements in programming languages, programming models, and frameworks have focused on abstracting the users from many programming issues. Among others, recent programming frameworks include simpler syntax, automatic memory management and garbage collection, which simplifies code re-usage through library packages, and easily configurable tools for deployment. For instance, Python has risen to the top of the list of the programming languages due to the simplicity of its syntax, while still achieving a good performance even being an interpreted language. Moreover, the community has helped to develop a large number of libraries and modules, tuning them to obtain great performance. However, there is still room for improvement when preventing users from dealing directly with distributed and parallel computing issues. This paper proposes and evaluates AutoParallel, a Python module to automatically find an appropriate task-based parallelization of affine loop nests to execute them in parallel in a distributed computing infrastructure. This parallelization can also include the building of data blocks to increase task granularity in order to achieve a good execution performance. Moreover, AutoParallel is based on sequential programming and only contains a small annotation in the form of a Python decorator so that anyone with little programming skills can scale up an application to hundreds of cores.
Offloading Execution from Edge to Cloud: a Dynamic Node-RED Based Approach
Fog computing enables use cases where data produced in end devices are stored, processed, and acted on directly at the edges of the network, yet computation can be offloaded to more powerful instances through the edge to cloud continuum. Such offloading mechanism is especially needed in case of modern multi-purpose IoT gateways, where both demand and operation conditions can vary largely between deployments. To facilitate the development and operations of gateways, we implement offloading directly as part of the IoT rapid prototyping process embedded in the software stack, based on Node-RED. We evaluate the implemented method using an image processing example, and compare various offloading strategies based on resource consumption and other system metrics, highlighting the differences in handling demand and service levels reached.
Interruptible Algorithms for Multiproblem Solving
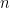
Software Expert Discovery via Knowledge Domain Embeddings in a Collaborative Network
Community Question Answering (CQA) websites can be claimed as the most major venues for knowledge sharing, and the most effective way of exchanging knowledge at present. Considering that massive amount of users are participating online and generating huge amount data, management of knowledge here systematically can be challenging. Expert recommendation is one of the major challenges, as it highlights users in CQA with potential expertise, which may help match unresolved questions with existing high quality answers while at the same time may help external services like human resource systems as another reference to evaluate their candidates. In this paper, we in this work we propose to exploring experts in CQA websites. We take advantage of recent distributed word representation technology to help summarize text chunks, and in a semantic view exploiting the relationships between natural language phrases to extract latent knowledge domains. By domains, the users’ expertise is determined on their historical performance, and a rank can be compute to given recommendation accordingly. In particular, Stack Overflow is chosen as our dataset to test and evaluate our work, where inclusive experiment shows our competence.
A fast algorithm for computing distance correlation
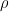

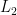



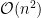

Improving the Stability of the Knockoff Procedure: Multiple Simultaneous Knockoffs and Entropy Maximization
The Model-X knockoff procedure has recently emerged as a powerful approach for feature selection with statistical guarantees. The advantage of knockoff is that if we have a good model of the features X, then we can identify salient features without knowing anything about how the outcome Y depends on X. An important drawback of knockoffs is its instability: running the procedure twice can result in very different selected features, potentially leading to different conclusions. Addressing this instability is critical for obtaining reproducible and robust results. Here we present a generalization of the knockoff procedure that we call simultaneous multi-knockoffs. We show that multi-knockoff guarantees false discovery rate (FDR) control, and is substantially more stable and powerful compared to the standard (single) knockoff. Moreover we propose a new algorithm based on entropy maximization for generating Gaussian multi-knockoffs. We validate the improved stability and power of multi-knockoffs in systematic experiments. We also illustrate how multi-knockoffs can improve the accuracy of detecting genetic mutations that are causally linked to phenotypes.
Theoretical research without projects
We propose a funding scheme for theoretical research that does not rely on project proposals, but on recent past scientific productivity. Given a quantitative figure of merit on the latter and the total research budget, we introduce a number of policies to decide the allocation of funds in each grant call. Under some assumptions on scientific productivity, some of such policies are shown to converge, in the limit of many grant calls, to a funding configuration that maximizes the total productivity of the whole scientific community. We present numerical simulations showing evidence that these schemes would also perform well in the presence of statistical noise in the scientific productivity and/or its evaluation. Finally, we argue that one of our policies cannot be cheated. Our work must be understood as a first step towards a scientific theory of research funding.
Robust Inference Using Inverse Probability Weighting
Inverse Probability Weighting (IPW) is widely used in program evaluation and other empirical economics applications. As Gaussian approximations perform poorly in the presence of ‘small denominators,’ trimming is routinely employed as a regularization strategy. However, ad hoc trimming of the observations renders usual inference procedures invalid for the target estimand, even in large samples. In this paper, we propose an inference procedure that is robust not only to small probability weights entering the IPW estimator, but also to a wide range of trimming threshold choices. Our inference procedure employs resampling with a novel bias correction technique. Specifically, we show that both the IPW and trimmed IPW estimators can have different (Gaussian or non-Gaussian) limiting distributions, depending on how ‘close to zero’ the probability weights are and on the trimming threshold. Our method provides more robust inference for the target estimand by adapting to these different limiting distributions. This robustness is partly achieved by correcting a non-negligible trimming bias. We demonstrate the finite-sample accuracy of our method in a simulation study, and we illustrate its use by revisiting a dataset from the National Supported Work program.
• The Role of Emotion in Problem Solving: First Results from Observing Chess• Free energies of Boltzmann Machines: self-averaging, annealed and replica symmetric approximations in the thermodynamic limit• A simulated annealing approach to the student-project allocation problem• SwitchNet: a neural network model for forward and inverse scattering problems• Viewpoint Discovery and Understanding in Social Networks• Analysis and Development of SiC MOSFET Boost Converter as Solar PV Pre-regulator• Tracking the History and Evolution of Entities: Entity-centric Temporal Analysis of Large Social Media Archives• A Text Classification Application: Poet Detection from Poetry• On random primitive sets, directable NDFAs and the generation of slowly synchronizing DFAs• Some Requests for Machine Learning Research from the East African Tech Scene• 5Gperf: signal processing performance for 5G• Vertex connectivity of the power graph of a finite cyclic group II• Automatic Analysis of Facial Expressions Based on Deep Covariance Trajectories• Analysis of the Smart Grid as a System of Systems• On the dissection of degenerate cosmologies with machine learning• The probability of positivity in symmetric and quasisymmetric functions• Geometrically Convergent Simulation of the Extrema of Lévy Processes• Optimal post-selection inference for sparse signals: a nonparametric empirical-Bayes approach• One-Shot Hierarchical Imitation Learning of Compound Visuomotor Tasks• A new look at weather-related health impacts through functional regression• Uniform Convergence of Gradients for Non-Convex Learning and Optimization• Teaching Syntax by Adversarial Distraction• Scaling and Balancing for High-Performance Computation of Optimal Controls• Automatic sequences based on Parry or Bertrand numeration systems• Radiomic Synthesis Using Deep Convolutional Neural Networks• Hyper $b$-ary expansions and Stern polynomials• Provable Gaussian Embedding with One Observation• UniMorph 2.0: Universal Morphology• Adaptive Density Estimation on Bounded Domains• Factor-Driven Two-Regime Regression• The complement of a nIL graph with thirteen vertices is IL• Sparse approximation of multivariate functions from small datasets via weighted orthogonal matching pursuit• Mimetic vs Anchored Value Alignment in Artificial Intelligence• Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model• Improving Document Binarization via Adversarial Noise-Texture Augmentation• An Optimal and Distributed Feedback Voltage Control under Limited Reactive Power• Finite-sample Guarantees for Winsorized Importance Sampling• The Impact of Position Errors on Crowd Simulation• Humans are still the best lossy image compressors• Dead Time Compensation for High-Flux Ranging• Efficient and High-Quality Seeded Graph Matching: Employing High Order Structural Information• Development and Analysis of Deterministic Privacy-Preserving Policies Using Non-Stochastic Information Theory• Communication Efficient Parallel Algorithms for Optimization on Manifolds• Size-Noise Tradeoffs in Generative Networks• Data-specific Adaptive Threshold for Face Recognition and Authentication• Distributed Multi-Player Bandits – a Game of Thrones Approach• Anti-lock Brake System for Integrated Electric Parking Brake Actuator Based on Sliding-mode Control• Efficient learning of neighbor representations for boundary trees and forests• Linear Convergence of Cyclic SAGA• Learning sparse relational transition models• Using solar and load predictions in battery scheduling at the residential level• Hanson-Wright inequality in Hilbert spaces with application to $K$-means clustering for non-Euclidean data• Neural Modular Control for Embodied Question Answering• TarMAC: Targeted Multi-Agent Communication• Fine-grained Video Categorization with Redundancy Reduction Attention• Trajectory Generation for Millimeter Scale Ferromagnetic Swimmers: Theory and Experiments• Integrating Transformer and Paraphrase Rules for Sentence Simplification• Distributed Market Clearing Approach for Local Energy Trading in Transactive Market• Lifting degenerate simplices with a single volume constraint• Optimal Offloading and Resource Allocation in Mobile-Edge Computing with Inter-user Task Dependency• CrystalGAN: Learning to Discover Crystallographic Structures with Generative Adversarial Networks• Sample covariances of random-coefficient AR(1) panel model• Deep learning based 2.5D flow field estimation for maximum intensity projections of 4D optical coherence tomography• Managing Many Simultaneous Systematic Uncertainties• Generalized Concordance for Competing Risks• Relationships between the Distribution of Watanabe–Strogatz Variables and Circular Cumulants for Ensembles of Phase Elements• Internal rapid stabilization of a 1-D linear transport equation with a scalar feedback• Capsule-Forensics: Using Capsule Networks to Detect Forged Images and Videos• Packing Returning Secretaries• Building Footprint Generation Using Improved Generative Adversarial Networks• Federating distributed storage for clouds in ATLAS• From the EM Algorithm to the CM-EM Algorithm for Global Convergence of Mixture Models• Probabilistic Analysis of Optimization Problems on Generalized Random Shortest Path Metrics• Normal distribution of correlation measures of binary sum-of-digits functions• Rational Quartic Spectrahedra• Existence of the anchored isoperimetric profile in supercritical bond percolation in dimension two and higher• A note on independence number, connectivity and $k$-ended tree• Unified Overview of Matrix-Monotonic Optimization for MIMO Transceivers• $L^{p}$ – Variational Solution of Backward Stochastic Differential Equation driven by subdifferential operators on a deterministic interval time• Video-based Person Re-identification Using Spatial-Temporal Attention Networks• Some comments on the structure of the best known networks sorting 16 elements• Convergence Analysis of Signed Nonlinear Networks• Texture variation adaptive image denoising with nonlocal PCA• Real-time Context-aware Learning System for IoT Applications• Exponential decay in the loop $O(n)$ model: $n> 1$, $x<\tfrac{1}{\sqrt{3}}+\varepsilon(n)$• Investigating non-classical correlations between decision fused multi-modal documents• Sub-O(log n) Out-of-Order Sliding-Window Aggregation• Omnidirectional Quasi-Orthogonal Space-Time Block Coded Massive MIMO Systems• HYPE: Massive Hypergraph Partitioning with Neighborhood Expansion• Comparing Multilayer Perceptron and Multiple Regression Models for Predicting Energy Use in the Balkans• Outlier Detection using Generative Models with Theoretical Performance Guarantees• Data Assimilation for Navier-Stokes using the Least-Squares Finite-Element Method• Benefits of over-parameterization with EM• Generating equilibrium molecules with deep neural networks• Security Event Recognition for Visual Surveillance• Static and Dynamic Vector Semantics for Lambda Calculus Models of Natural Language• New Designs on MVDR Robust Adaptive Beamforming Based on Optimal Steering Vector Estimation• Relay self-oscillations for second order, stable, nonminimum phase plants• Pattern avoidance and quasisymmetric functions• A Large deviation principle for last passage times in an asymmetric Bernoulli potential• YatSim: an Open-Source Simulator For Testing Consensus-based Control Strategies in Urban Traffic Networks• Data-driven Variable Speed Limit Design for Highways via Distributionally Robust Optimization• On a Diagonal Conjecture for Classical Ramsey Numbers• Deep Intrinsically Motivated Continuous Actor-Critic for Efficient Robotic Visuomotor Skill Learning• Joint Estimation of DOA and Frequency with Sub-Nyquist Sampling in a Binary Array Radar System• Finding dissimilar explanations in Bayesian networks: Complexity results• Dendritic cortical microcircuits approximate the backpropagation algorithm• Optimal control of ODEs with state suprema• Position weighted backpressure intersection control for connected urban networks• Anytime Stereo Image Depth Estimation on Mobile Devices• Mining Maximal Induced Bicliques using Odd Cycle Transversals• Resampled Priors for Variational Autoencoders• American Sign Language fingerspelling recognition in the wild• Energy Efficient Adversarial Routing in Shared Channels• Statistics of eigenstates near the localization transition on random regular graphs• Scalable Unbalanced Optimal Transport using Generative Adversarial Networks
Like this:
Like Loading…
Related