Activity Recognition using Hierarchical Hidden Markov Models on Streaming Sensor Data
Activity recognition from sensor data deals with various challenges, such as overlapping activities, activity labeling, and activity detection. Although each challenge in the field of recognition has great importance, the most important one refers to online activity recognition. The present study tries to use online hierarchical hidden Markov model to detect an activity on the stream of sensor data which can predict the activity in the environment with any sensor event. The activity recognition samples were labeled by the statistical features such as the duration of activity. The results of our proposed method test on two different datasets of smart homes in the real world showed that one dataset has improved 4% and reached (59%) while the results reached 64.6% for the other data by using the best methods.
Introducing a hybrid model of DEA and data mining in evaluating efficiency. Case study: Bank Branches
The banking industry is very important for an economic cycle of each country and provides some quality of services for us. With the advancement in technology and rapidly increasing of the complexity of the business environment, it has become more competitive than the past so that efficiency analysis in the banking industry attracts much attention in recent years. From many aspects, such analyses at the branch level are more desirable. Evaluating the branch performance with the purpose of eliminating deficiency can be a crucial issue for branch managers to measure branch efficiency. This work not only can lead to a better understanding of bank branch performance but also give further information to enhance managerial decisions to recognize problematic areas. To achieve this purpose, this study presents an integrated approach based on Data Envelopment Analysis (DEA), Clustering algorithms and Polynomial Pattern Classifier for constructing a classifier to identify a class of bank branches. First, the efficiency estimates of individual branches are evaluated by using the DEA approach. Next, when the range and number of classes were identified by experts, the number of clusters is identified by an agglomerative hierarchical clustering algorithm based on some statistical methods. Next, we divide our raw data into k clusters By means of self-organizing map (SOM) neural networks. Finally, all clusters are fed into the reduced multivariate polynomial model to predict the classes of data.
Conceptual Knowledge Markup Language: An Introduction
Conceptual Knowledge Markup Language (CKML) is an application of XML. Earlier versions of CKML followed rather exclusively the philosophy of Conceptual Knowledge Processing (CKP), a principled approach to knowledge representation and data analysis that ‘advocates methods and instruments of conceptual knowledge processing which support people in their rational thinking, judgment and acting and promote critical discussion.’ The new version of CKML continues to follow this approach, but also incorporates various principles, insights and techniques from Information Flow (IF), the logical design of distributed systems. Among other things, this allows diverse communities of discourse to compare their own information structures, as coded in logical theories, with that of other communities that share a common generic ontology. CKML incorporates the CKP ideas of concept lattice and formal context, along with the IF ideas of classification (= formal context), infomorphism, theory, interpretation and local logic. Ontology Markup Language (OML), a subset of CKML that is a self-sufficient markup language in its own right, follows the principles and ideas of Conceptual Graphs (CG). OML is used for structuring the specifications and axiomatics of metadata into ontologies. OML incorporates the CG ideas of concept, conceptual relation, conceptual graph, conceptual context, participants and ontology. The link from OML to CKML is the process of conceptual scaling, which is the interpretive transformation of ontologically structured knowledge to conceptual structured knowledge.
Physics-Informed Regularization of Deep Neural Networks
This paper presents a novel physics-informed regularization method for training of deep neural networks (DNNs). In particular, we focus on the DNN representation for the response of a physical or biological system, for which a set of governing laws are known. These laws often appear in the form of differential equations, derived from first principles, empirically-validated laws, and/or domain expertise. We propose a DNN training approach that utilizes these known differential equations in addition to the measurement data, by introducing a penalty term to the training loss function to penalize divergence form the governing laws. Through three numerical examples, we will show that the proposed regularization produces surrogates that are physically interpretable with smaller generalization errors, when compared to other common regularization methods.
Bilinear Factor Matrix Norm Minimization for Robust PCA: Algorithms and Applications
The heavy-tailed distributions of corrupted outliers and singular values of all channels in low-level vision have proven effective priors for many applications such as background modeling, photometric stereo and image alignment. And they can be well modeled by a hyper-Laplacian. However, the use of such distributions generally leads to challenging non-convex, non-smooth and non-Lipschitz problems, and makes existing algorithms very slow for large-scale applications. Together with the analytic solutions to lp-norm minimization with two specific values of p, i.e., p=1/2 and p=2/3, we propose two novel bilinear factor matrix norm minimization models for robust principal component analysis. We first define the double nuclear norm and Frobenius/nuclear hybrid norm penalties, and then prove that they are in essence the Schatten-1/2 and 2/3 quasi-norms, respectively, which lead to much more tractable and scalable Lipschitz optimization problems. Our experimental analysis shows that both our methods yield more accurate solutions than original Schatten quasi-norm minimization, even when the number of observations is very limited. Finally, we apply our penalties to various low-level vision problems, e.g., text removal, moving object detection, image alignment and inpainting, and show that our methods usually outperform the state-of-the-art methods.
The Impact of Annotation Guidelines and Annotated Data on Extracting App Features from App Reviews
Annotation guidelines used to guide the annotation of training and evaluation datasets can have a considerable impact on the quality of machine learning models. In this study, we explore the effects of annotation guidelines on the quality of app feature extraction models. As a main result, we propose several changes to the existing annotation guidelines with a goal of making the extracted app features more useful and informative to the app developers. We test the proposed changes via simulating the application of the new annotation guidelines and then evaluating the performance of the supervised machine learning models trained on datasets annotated with initial and simulated guidelines. While the overall performance of automatic app feature extraction remains the same as compared to the model trained on the dataset with initial annotations, the features extracted by the model trained on the dataset with simulated new annotations are less noisy and more informative to the app developers. Secondly, we are interested in what kind of annotated training data is necessary for training an automatic app feature extraction model. In particular, we explore whether the training set should contain annotated app reviews from those apps/app categories on which the model is subsequently planned to be applied, or is it sufficient to have annotated app reviews from any app available for training, even when these apps are from very different categories compared to the test app. Our experiments show that having annotated training reviews from the test app is not necessary although including them into training set helps to improve recall. Furthermore, we test whether augmenting the training set with annotated product reviews helps to improve the performance of app feature extraction. We find that the models trained on augmented training set lead to improved recall but at the cost of the drop in precision.
Mind the GAP: A Balanced Corpus of Gendered Ambiguous Pronouns
Coreference resolution is an important task for natural language understanding, and the resolution of ambiguous pronouns a longstanding challenge. Nonetheless, existing corpora do not capture ambiguous pronouns in sufficient volume or diversity to accurately indicate the practical utility of models. Furthermore, we find gender bias in existing corpora and systems favoring masculine entities. To address this, we present and release GAP, a gender-balanced labeled corpus of 8,908 ambiguous pronoun-name pairs sampled to provide diverse coverage of challenges posed by real-world text. We explore a range of baselines which demonstrate the complexity of the challenge, the best achieving just 66.9% F1. We show that syntactic structure and continuous neural models provide promising, complementary cues for approaching the challenge.
MDGAN: Boosting Anomaly Detection Using \Multi-Discriminator Generative Adversarial Networks
Anomaly detection is often considered a challenging field of machine learning due to the difficulty of obtaining anomalous samples for training and the need to obtain a sufficient amount of training data. In recent years, autoencoders have been shown to be effective anomaly detectors that train only on ‘normal’ data. Generative adversarial networks (GANs) have been used to generate additional training samples for classifiers, thus making them more accurate and robust. However, in anomaly detection GANs are only used to reconstruct existing samples rather than to generate additional ones. This stems both from the small amount and lack of diversity of anomalous data in most domains. In this study we propose MDGAN, a novel GAN architecture for improving anomaly detection through the generation of additional samples. Our approach uses two discriminators: a dense network for determining whether the generated samples are of sufficient quality (i.e., valid) and an autoencoder that serves as an anomaly detector. MDGAN enables us to reconcile two conflicting goals: 1) generate high-quality samples that can fool the first discriminator, and 2) generate samples that can eventually be effectively reconstructed by the second discriminator, thus improving its performance. Empirical evaluation on a diverse set of datasets demonstrates the merits of our approach.
Efficient Augmentation via Data Subsampling
Data augmentation is commonly used to encode invariances in learning methods. However, this process is often performed in an inefficient manner, as artificial examples are created by applying a number of transformations to all points in the training set. The resulting explosion of the dataset size can be an issue in terms of storage and training costs, as well as in selecting and tuning the optimal set of transformations to apply. In this work, we demonstrate that it is possible to significantly reduce the number of data points included in data augmentation while realizing the same accuracy and invariance benefits of augmenting the entire dataset. We propose a novel set of subsampling policies, based on model influence and loss, that can achieve a 90% reduction in augmentation set size while maintaining the accuracy gains of standard data augmentation.
Practical Design Space Exploration
Multi-objective optimization is a crucial matter in computer systems design space exploration because real-world applications often rely on a trade-off between several objectives. Derivatives are usually not available or impractical to compute and the feasibility of an experiment can not always be determined in advance. These problems are particularly difficult when the feasible region is relatively small, and it may be prohibitive to even find a feasible experiment, let alone an optimal one. We introduce a new methodology and corresponding software framework, HyperMapper 2.0, which handles multi-objective optimization, unknown feasibility constraints, and categorical/ordinal variables. This new methodology also supports injection of user prior knowledge in the search when available. All of these features are common requirements in computer systems but rarely exposed in existing design space exploration systems. The proposed methodology follows a white-box model which is simple to understand and interpret (unlike, for example, neural networks) and can be used by the user to better understand the results of the automatic search. We apply and evaluate the new methodology to automatic static tuning of hardware accelerators within the recently introduced Spatial programming language, with minimization of design runtime and compute logic under the constraint of the design fitting in a target field programmable gate array chip. Our results show that HyperMapper 2.0 provides better Pareto fronts compared to state-of-the-art baselines, with better or competitive hypervolume indicator and with 8x improvement in sampling budget for most of the benchmarks explored.
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
Most existing studies in text-to-SQL tasks do not require generating complex SQL queries with multiple clauses or sub-queries, and generalizing to new, unseen databases. In this paper we propose SyntaxSQLNet, a syntax tree network to address the complex and cross-domain text-to-SQL generation task. SyntaxSQLNet employs a SQL specific syntax tree-based decoder with SQL generation path history and table-aware column attention encoders. We evaluate SyntaxSQLNet on the Spider text-to-SQL task, which contains databases with multiple tables and complex SQL queries with multiple SQL clauses and nested queries. We use a database split setting where databases in the test set are unseen during training. Experimental results show that SyntaxSQLNet can handle a significantly greater number of complex SQL examples than prior work, outperforming the previous state-of-the-art model by 8.3% in exact matching accuracy. We also show that SyntaxSQLNet can further improve the performance by an additional 8.1% using a cross-domain augmentation method, resulting in a 16.4% improvement in total. To our knowledge, we are the first to study this complex and cross-domain text-to-SQL task.
Stochastic $\ell_p$ Load Balancing and Moment Problems via the $L$-Function Method

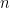

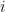
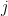
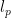

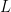
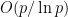
Measuring Sample Path Causal Influences with Relative Entropy
We present a sample path dependent measure of causal influence between time series. The proposed causal measure is a random sequence, a realization of which enables identification of specific patterns that give rise to high levels of causal influence. We show that these patterns cannot be identified by existing measures such as directed information (DI). We demonstrate how sequential prediction theory may be leveraged to estimate the proposed causal measure and introduce a notion of regret for assessing the performance of such estimators. We prove a finite sample bound on this regret that is determined by the worst case regret of the sequential predictors used in the estimator. Justification for the proposed measure is provided through a series of examples, simulations, and application to stock market data. Within the context of estimating DI, we show that, because joint Markovicity of a pair of processes does not imply the marginal Markovicity of individual processes, commonly used plug-in estimators of DI will be biased for a large subset of jointly Markov processes. We introduce a notion of DI with ‘stale history’, which can be combined with a plug-in estimator to upper and lower bound the DI when marginal Markovicity does not hold.
Offline Comparison of Ranking Functions using Randomized Data
Ranking functions return ranked lists of items, and users often interact with these items. How to evaluate ranking functions using historical interaction logs, also known as off-policy evaluation, is an important but challenging problem. The commonly used Inverse Propensity Scores (IPS) approaches work better for the single item case, but suffer from extremely low data efficiency for the ranked list case. In this paper, we study how to improve the data efficiency of IPS approaches in the offline comparison setting. We propose two approaches Trunc-match and Rand-interleaving for offline comparison using uniformly randomized data. We show that these methods can improve the data efficiency and also the comparison sensitivity based on one of the largest email search engines.
Aleph: A Leaderless, Asynchronous, Byzantine Fault Tolerant Consensus Protocol
In this paper we propose Aleph, a leaderless, fully asynchronous, Byzantine fault tolerant consensus protocol for ordering messages exchanged among processes. It is based on a distributed construction of a partially ordered set and the algorithm for reaching a consensus on its extension to a total order. To achieve the consensus, the processes perform computations based only on a local copy of the data structure, however, they are bound to end with the same results. Our algorithm uses a dual-threshold coin-tossing scheme as a randomization strategy and establishes the agreement in an expected constant number of rounds. In addition, we introduce a fast way of validating messages that can occur prior to determining the total ordering.
Rethinking the Value of Network Pruning
Network pruning is widely used for reducing the heavy computational cost of deep models. A typical pruning algorithm is a three-stage pipeline, i.e., training (a large model), pruning and fine-tuning. During pruning, according to a certain criterion, redundant weights are pruned and important weights are kept to best preserve the accuracy. In this work, we make several surprising observations which contradict common beliefs. For all the six state-of-the-art pruning algorithms we examined, fine-tuning a pruned model only gives comparable or even worse performance than training that model with randomly initialized weights. For pruning algorithms which assume a predefined target network architecture, one can get rid of the full pipeline and directly train the target network from scratch. Our observations are consistent for a wide variety of pruning algorithms with multiple network architectures, datasets, and tasks. Our results have several implications: 1) training a large, over-parameterized model is not necessary to obtain an efficient final model, 2) learned ‘important’ weights of the large model are not necessarily useful for the small pruned model, 3) the pruned architecture itself, rather than a set of inherited ‘important’ weights, is what leads to the efficiency benefit in the final model, which suggests that some pruning algorithms could be seen as performing network architecture search.
IOHprofiler: A Benchmarking and Profiling Tool for Iterative Optimization Heuristics

Online Multiclass Boosting with Bandit Feedback
We present online boosting algorithms for multiclass classification with bandit feedback, where the learner only receives feedback about the correctness of its prediction. We propose an unbiased estimate of the loss using a randomized prediction, allowing the model to update its weak learners with limited information. Using the unbiased estimate, we extend two full information boosting algorithms (Jung et al., 2017) to the bandit setting. We prove that the asymptotic error bounds of the bandit algorithms exactly match their full information counterparts. The cost of restricted feedback is reflected in the larger sample complexity. Experimental results also support our theoretical findings, and performance of the proposed models is comparable to the that of an existing bandit boosting algorithm, which is limited to use binary weak learners.
Important Attribute Identification in Knowledge Graph
The knowledge graph(KG) composed of entities with their descriptions and attributes, and relationship between entities, is finding more and more application scenarios in various natural language processing tasks. In a typical knowledge graph like Wikidata, entities usually have a large number of attributes, but it is difficult to know which ones are important. The importance of attributes can be a valuable piece of information in various applications spanning from information retrieval to natural language generation. In this paper, we propose a general method of using external user generated text data to evaluate the relative importance of an entity’s attributes. To be more specific, we use the word/sub-word embedding techniques to match the external textual data back to entities’ attribute name and values and rank the attributes by their matching cohesiveness. To our best knowledge, this is the first work of applying vector based semantic matching to important attribute identification, and our method outperforms the previous traditional methods. We also apply the outcome of the detected important attributes to a language generation task; compared with previous generated text, the new method generates much more customized and informative messages.
Dynamic Channel Pruning: Feature Boosting and Suppression

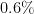
Multiplicative Weights Updates as a distributed constrained optimization algorithm: Convergence to second-order stationary points almost always

Decentralized Applications: The Blockchain-Empowered Software System
Blockchain technology has attracted tremendous attention in both academia and capital market. However, overwhelming speculations on thousands of available cryptocurrencies and numerous initial coin offering (ICO) scams have also brought notorious debates on this emerging technology. This paper traces the development of blockchain systems to reveal the importance of decentralized applications (dApps) and the future value of blockchain. We survey the state-of-the-art dApps and discuss the direction of blockchain development to fulfill the desirable characteristics of dApps. The readers will gain an overview of dApp research and get familiar with recent developments in the blockchain.
Neural Variational Hybrid Collaborative Filtering
Collaborative Filtering (CF) is one of the most used methods for Recommender System. Because of the Bayesian nature and non-linearity, deep generative models, e.g. Variational Autoencoder (VAE), have been applied into CF task, and have achieved great performance. However, most VAE-based methods suffer from matrix sparsity and consider the prior of users’ latent factors to be the same, which leads to poor latent representations of users and items. Additionally, most existing methods model latent factors of users only and but not items, which makes them not be able to recommend items to a new user. To tackle these problems, we propose a Neural Variational Hybrid Collaborative Filtering, \VDMF{}. Specifically, we consider both the generative processes of users and items, and the prior of latent factors of users and items to be \emph{side ~information-specific}, which enables our model to alleviate matrix sparsity and learn better latent representations of users and items. For inference purpose, we derived a Stochastic Gradient Variational Bayes (SGVB) algorithm to analytically approximate the intractable distributions of latent factors of users and items. Experiments conducted on two large datasets have showed our methods significantly outperform the state-of-the-art CF methods, including the VAE-based methods.
Technology Assisted Reviews: Finding the Last Few Relevant Documents by Asking Yes/No Questions to Reviewers
The goal of a technology-assisted review is to achieve high recall with low human effort. Continuous active learning algorithms have demonstrated good performance in locating the majority of relevant documents in a collection, however their performance is reaching a plateau when 80\%-90\% of them has been found. Finding the last few relevant documents typically requires exhaustively reviewing the collection. In this paper, we propose a novel method to identify these last few, but significant, documents efficiently. Our method makes the hypothesis that entities carry vital information in documents, and that reviewers can answer questions about the presence or absence of an entity in the missing relevance documents. Based on this we devise a sequential Bayesian search method that selects the optimal sequence of questions to ask. The experimental results show that our proposed method can greatly improve performance requiring less reviewing effort.
Cats or CAT scans: transfer learning from natural or medical image source datasets?
Transfer learning is a widely used strategy in medical image analysis. Instead of only training a network with a limited amount of data from the target task of interest, we can first train the network with other, potentially larger source datasets, creating a more robust model. The source datasets do not have to be related to the target task. For a classification task in lung CT images, we could use both head CT images, or images of cats, as the source. While head CT images appear more similar to lung CT images, the number and diversity of cat images might lead to a better model overall. In this survey we review a number of papers that have performed similar comparisons. Although the answer to which strategy is best seems to be ‘it depends’, we discuss a number of research directions we need to take as a community, to gain more understanding of this topic.
Mode Normalization
Normalization methods are a central building block in the deep learning toolbox. They accelerate and stabilize training, while decreasing the dependence on manually tuned learning rate schedules. When learning from multi-modal distributions, the effectiveness of batch normalization (BN), arguably the most prominent normalization method, is reduced. As a remedy, we propose a more flexible approach: by extending the normalization to more than a single mean and variance, we detect modes of data on-the-fly, jointly normalizing samples that share common features. We demonstrate that our method outperforms BN and other widely used normalization techniques in several experiments, including single and multi-task datasets.
Predictive Uncertainty through Quantization
High-risk domains require reliable confidence estimates from predictive models. Deep latent variable models provide these, but suffer from the rigid variational distributions used for tractable inference, which err on the side of overconfidence. We propose Stochastic Quantized Activation Distributions (SQUAD), which imposes a flexible yet tractable distribution over discretized latent variables. The proposed method is scalable, self-normalizing and sample efficient. We demonstrate that the model fully utilizes the flexible distribution, learns interesting non-linearities, and provides predictive uncertainty of competitive quality.
Uncertainty in Neural Networks: Bayesian Ensembling
Understanding the uncertainty of a neural network’s (NN) predictions is essential for many applications. The Bayesian framework provides a principled approach to this, however applying it to NNs is challenging due to the large number of parameters and data. Ensembling NNs provides a practical and scalable method for uncertainty quantification. Its drawback is that its justification is heuristic rather than Bayesian. In this work we propose one modification to the usual ensembling process, that does result in Bayesian behaviour: regularising parameters about values drawn from a prior distribution. Hence, we present an easily implementable, scalable technique for performing approximate Bayesian inference in NNs.
Feature Learning for Fault Detection in High-Dimensional Condition-Monitoring Signals
Complex industrial systems are continuously monitored by a large number of heterogenous sensors. The diversity of their operating conditions and the possible fault types make it impossible to collect enough data for learning all the possible fault patterns. The paper proposes an integrated automatic unsupervised feature learning approach for fault detection that uses healthy conditions data only for its training. The approach is based on stacked Extreme Learning Machines (namely Hierarchical, or HELM) and comprises stacked autoencoders performing unsupervised feature learning, and a one-class classifier monitoring the variations in the features to assess the health of the system. This study provides a comprehensive evaluation of HELM fault detection capability compared to other machine learning approaches, including Deep Belief Networks. The performance is first evaluated on a synthetic dataset with typical characteristics of condition monitoring data. Subsequently, the approach is evaluated on a real case study of a power plant fault. HELM demonstrates a better performance specifically in cases where several non-informative signals are included.
Variational Bayesian Monte Carlo
Bayesian Inference of Self-intention Attributed by Observer
Most of agents that learn policy for tasks with reinforcement learning (RL) lack the ability to communicate with people, which makes human-agent collaboration challenging. We believe that, in order for RL agents to comprehend utterances from human colleagues, RL agents must infer the mental states that people attribute to them because people sometimes infer an interlocutor’s mental states and communicate on the basis of this mental inference. This paper proposes PublicSelf model, which is a model of a person who infers how the person’s own behavior appears to their colleagues. We implemented the PublicSelf model for an RL agent in a simulated environment and examined the inference of the model by comparing it with people’s judgment. The results showed that the agent’s intention that people attributed to the agent’s movement was correctly inferred by the model in scenes where people could find certain intentionality from the agent’s behavior.
Discursive Landscapes and Unsupervised Topic Modeling in IR: A Validation of Text-As-Data Approaches through a New Corpus of UN Security Council Speeches on Afghanistan
The recent turn towards quantitative text-as-data approaches in IR brought new ways to study the discursive landscape of world politics. Here seen as complementary to qualitative approaches, quantitative assessments have the advantage of being able to order and make comprehensible vast amounts of text. However, the validity of unsupervised methods applied to the types of text available in large quantities needs to be established before they can speak to other studies relying on text and discourse as data. In this paper, we introduce a new text corpus of United Nations Security Council (UNSC) speeches on Afghanistan between 2001 and 2017; we study this corpus through unsupervised topic modeling (LDA) with the central aim to validate the topic categories that the LDA identifies; and we discuss the added value, and complementarity, of quantitative text-as-data approaches. We set-up two tests using mixed- method approaches. Firstly, we evaluate the identified topics by assessing whether they conform with previous qualitative work on the development of the situation in Afghanistan. Secondly, we use network analysis to study the underlying social structures of what we will call ‘speaker-topic relations’ to see whether they correspondent to know divisions and coalitions in the UNSC. In both cases we find that the unsupervised LDA indeed provides valid and valuable outputs. In addition, the mixed-method approaches themselves reveal interesting patterns deserving future qualitative research. Amongst these are the coalition and dynamics around the ‘women and human rights’ topic as part of the UNSC debates on Afghanistan.
Is multiagent deep reinforcement learning the answer or the question? A brief survey
Deep reinforcement learning (DRL) has achieved outstanding results in recent years. This has led to a dramatic increase in the number of applications and methods. Recent works have explored learning beyond single-agent scenarios and have considered multiagent scenarios. Initial results report successes in complex multiagent domains, although there are several challenges to be addressed. In this context, first, this article provides a clear overview of current multiagent deep reinforcement learning (MDRL) literature. Second, it provides guidelines to complement this emerging area by (i) showcasing examples on how methods and algorithms from DRL and multiagent learning (MAL) have helped solve problems in MDRL and (ii) providing general lessons learned from these works. We expect this article will help unify and motivate future research to take advantage of the abundant literature that exists in both areas (DRL and MAL) in a joint effort to promote fruitful research in the multiagent community.
Fast Construction of Correcting Ensembles for Legacy Artificial Intelligence Systems: Algorithms and a Case Study
This paper presents a technology for simple and computationally efficient improvements of a generic Artificial Intelligence (AI) system, including Multilayer and Deep Learning neural networks. The improvements are, in essence, small network ensembles constructed on top of the existing AI architectures. Theoretical foundations of the technology are based on Stochastic Separation Theorems and the ideas of the concentration of measure. We show that, subject to mild technical assumptions on statistical properties of internal signals in the original AI system, the technology enables instantaneous and computationally efficient removal of spurious and systematic errors with probability close to one on the datasets which are exponentially large in dimension. The method is illustrated with numerical examples and a case study of ten digits recognition from American Sign Language.
Interpretable Fairness via Target Labels in Gaussian Process Models
Addressing fairness in machine learning models has recently attracted a lot of attention, as it will ensure continued confidence of the general public in the deployment of machine learning systems. Here, we focus on mitigating harm of a biased system that offers much better quality outputs for certain groups than for others. We show that bias in the output can naturally be handled in Gaussian process classification (GPC) models by introducing a latent target output that will modulate the likelihood function. This simple formulation has several advantages: first, it is a unified framework for several notions of fairness (demographic parity, equalized odds, and equal opportunity); second, it allows encoding our knowledge of what the bias in outputs should be; and third, it can be solved by using off-the-shelf GPC packages.
Stochastic (Approximate) Proximal Point Methods: Convergence, Optimality, and Adaptivity
We develop model-based methods for solving stochastic convex optimization problems, introducing the approximate-proximal point, or \aProx, family, which includes stochastic subgradient, proximal point, and bundle methods. When the modeling approaches we propose are appropriately accurate, the methods enjoy stronger convergence and robustness guarantees than classical approaches, even though the model-based methods typically add little to no computational overhead over stochastic subgradient methods. For example, we show that improved models converge with probability 1 and enjoy optimal asymptotic normality results under weak assumptions; these methods are also adaptive to a natural class of what we term easy optimization problems, achieving linear convergence under appropriate strong growth conditions on the objective. Our substantial experimental investigation shows the advantages of more accurate modeling over standard subgradient methods across many smooth and non-smooth optimization problems.
• Asynchronous Wi-Fi Control Interface (AWCI) Using Socket IO Technology• Federated Learning for Keyword Spotting• Effects of memory on spreading processes in non-Markovian temporal networks• Deterministic Pod Repositioning Problem in Robotic Mobile Fulfillment Systems• A Software Radio Challenge Accelerating Education and Innovation in Wireless Communications• Automatic Configuration of Deep Neural Networks with EGO• Regression Model for Predicting Expansion of Concrete Exposed to Sulfate Attack Based on Performance-based Classification• Probabilistic Blocking with An Application to the Syrian Conflict• Empowerment-driven Exploration using Mutual Information Estimation• Trivalent expanders, $(Δ-Y)$-transformation, and hyperbolic surfaces• On the applicability of distributed ledger architectures to peer-to-peer energy trading framework• Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation• A Constraint Propagation Algorithm for Sums-of-Squares Formulas over the Integers• Energy Flow Networks: Deep Sets for Particle Jets• Fighting Contextual Bandits with Stochastic Smoothing• Bayesian cosmic density field inference from redshift space dark matter maps• Maker-Breaker Percolation Games I: Crossing Grids• Bayesian neural networks increasingly sparsify their units with depth• Verification of Two-Dimensional Monte Carlo Ray-Trace Methodology in Radiation Heat Transfer Analysis• Realistic Adversarial Examples in 3D Meshes• On Kernel Derivative Approximation with Random Fourier Features• Distributionally Robust Transmission Expansion Planning: a Multi-scale Uncertainty Approach• Parallelized Linear Classification with Volumetric Chemical Perceptrons• Stochastic reachability of a target tube: Theory and computation• FeatureLego: Volume Exploration Using Exhaustive Clustering of Super-Voxels• Large Genus Asymptotics for Siegel-Veech Constants• Exploiting Low-Rank Structure in Semidefinite Programming by Approximate Operator Splitting• Generating Diverse Numbers of Diverse Keyphrases• Piano Genie• Real-time Fault Localization in Power Grids With Convolutional Neural Networks• Iterative Time-Varying Filter Algorithm Based on Discrete Linear Chirp Transform• A Doubly Stochastic Gauss-Seidel Algorithm for Solving Linear Equations and Certain Convex Minimization Problems• A Generalized Fading Model with Multiple Specular Components• A Novel Chaotic Uniform Quantizer for Speech Coding• Sidon sets and $C_4$-saturated graphs• Optimal pebbling number of the square grid• Instantaneous frequency estimation using the discrete linear chirp transform and the Wigner distribution• Fairness-Regularized DLMP-Based Bilevel Transactive Energy Mechanism in Distribution Systems• A graph with the partial order competition dimension greater than five• The niche graphs of bipartite tournaments• A new minimal chordal completion• Resilient Sparse Controller Design with Guaranteed Disturbance Attenuation• Stochastic Revealed Preferences with Measurement Error• signSGD with Majority Vote is Communication Efficient And Byzantine Fault Tolerant• Bayesian Hierarchical Spatial Model for Small Area Estimation with Non-ignorable Nonresponses and Its Applications to the NHANES Dental Caries Assessments• Parallelism in Randomized Incremental Algorithms• Block Stability for MAP Inference• Spatiotemporal Model for Uplink IoT Traffic: Scheduling & Random Access Paradox• Xorshift1024*, Xorshift1024+, Xorshift128+ and Xoroshiro128+ Fail Statistical Tests for Linearity• Learning to Reason• SCMA based resource management of D2D communications for maximum sum-revenue• Independence Equivalence Classes of Paths and Cycles• Rainbow matchings of size $m$ in graphs with total color degree at least $2mn$• Central limit theorem and moderate deviations for a stochastic Cahn-Hilliard equation• On the Properties of Gromov Matrices and their Applications in Network Inference• IndoSum: A New Benchmark Dataset for Indonesian Text Summarization• 4D Human Body Correspondences from Panoramic Depth Maps• Tails of exit times from unstable equilibria on the line• Optimal Hierarchical Learning Path Design with Reinforcement Learning• On The Equivalence of Tries and Dendrograms – Efficient Hierarchical Clustering of Traffic Data• Optimal Architecture for Deep Neural Networks with Heterogeneous Sensitivity• Unsupervised Facial Geometry Learning for Sketch to Photo Synthesis• First principles modeling of the structural, electronic, and vibrational properties of Ni${40}$Pd${40}$P$_{20}$ bulk metallic glass• FPGA-based Acceleration System for Visual Tracking• On the Margin Theory of Feedforward Neural Networks• Granularity of wagers in games and the (im)possibility of savings• Limitations of ‘Limitations of Bayesian leave-one-out cross-validation for model selection’• Optimal lower bounds on hitting probabilities for non-linear systems of stochastic fractional heat equations• On the relationship of energy and probability in models of classical statistical physics• Frequency Synchronization for Uplink Massive MIMO with Adaptive MUI Suppression in Angle-domain• Sequential Learning of Movement Prediction in Dynamic Environments using LSTM Autoencoder• Point Cloud Colorization Based on Densely Annotated 3D Shape Dataset• The good, the bad, and the ugly: Bayesian model selection produces spurious posterior probabilities for phylogenetic trees• Thermal Infrared Colorization via Conditional Generative Adversarial Network• Interference Alignment Schemes Using Latin Square for Kx3 MIMO X Channel• A Gentle Introduction to Deep Learning in Medical Image Processing• A convex approach to the Gilbert-Steiner problem• Deep Reinforcement Learning Autoencoder with Noisy Feedback• Cryo-CARE: Content-Aware Image Restoration for Cryo-Transmission Electron Microscopy Data• The use of blogs in the education field: A qualitative systematic review• A Survey: Non-Orthogonal Multiple Access with Compressed Sensing Multiuser Detection for mMTC• DeepScores and Deep Watershed Detection: current state and open issues• Real-time self-adaptive deep stereo• On the Existence and Uniqueness of Poincaré Maps for Systems with Impulse Effects• Sub-Finsler geodesics on the Cartan group• Constructions of Primitive Formally Dual Pairs Having Subsets with Unequal Sizes• HiTR: Hierarchical Topic Model Re-estimation for Measuring Topical Diversity of Documents• MPTV: Matching Pursuit Based Total Variation Minimization for Image Deconvolution• An Algebraic-Geometric Approach to Shuffled Linear Regression• Low-Complexity Detection of M-ary PSK Faster-than-Nyquist Signaling• Uniform random posets• Zeros of the Möbius function of permutations• Fast approximate inference for variable selection in Dirichlet process mixtures, with an application to pan-cancer proteomics• A Bounding Box Overlay for Competitive Routing in Hybrid Communication Networks• Modeling Varying Camera-IMU Time Offset in Optimization-Based Visual-Inertial Odometry• Reconstructing bifurcation behavior of a nonlinear dynamical system by introducing weak noise• Covert Communication with A Full-Duplex Receiver Based on Channel Distribution Information• Safe Grid Search with Optimal Complexity• Open and closed factors of Arnoux-Rauzy words• Bounds and Limit Theorems for a Layered Queueing Model in Electric Vehicle Charging• Pre-gen metrics: Predicting caption quality metrics without generating captions• Quantifying the amount of visual information used by neural caption generators• Interplay of minimax estimation and minimax support recovery under sparsity• Optimal control of electricity input given an uncertain demand• Social capital predicts corruption risk in towns• Training Deep Neural Network in Limited Precision• Quantization for Rapid Deployment of Deep Neural Networks• On the convergence problem in Mean Field Games: a two state model without uniqueness• On relative clique number of colored mixed graphs• Semi-Supervised Overlapping Community Finding based on Label Propagation with Pairwise Constraints• Grand challenges in social physics: In pursuit of moral behavior• Cubillages on cyclic zonotopes, membranes, and higher separatation• Reconciling cold pool dynamics with convective self-organization• Contracts as specifications for dynamical systems in driving variable form• Enumerative Gadget Phenomena for $(4,1)$-Adinkras• Effects of Image Degradations to CNN-based Image Classification• Optimal Source Codes for Timely Updates• Grand Challenge: Real-time Destination and ETA Prediction for Maritime Traffic• Characterization and extraction of condensed representation of correlated patterns based on formal concept analysis• Facility Locations Utility for Uncovering Classifier Overconfidence• Strong Structural Controllability of Systems on Colored Graphs• Chromatic Polynomials of Oriented Graphs• PointGrow: Autoregressively Learned Point Cloud Generation with Self-Attention• Uniform Lipschitz functions on the triangular lattice have logarithmic variations• Multivariate Myriad Filters based on Parameter Estimation of Student-$t$ Distributions• Custom Dual Transportation Mode Detection by Smartphone Devices Exploiting Sensor Diversity• Learning Grid-like Units with Vector Representation of Self-Position and Matrix Representation of Self-Motion• Eigenfunctions and Random Waves in the Benjamini-Schramm limit• Investigating the Power of Circuits with $MOD_6$ Gates• Limits of conformal images and conformal images of limits for planar random curves• Harvesting of interacting stochastic populations• Identities for Poincaré polynomials via Kostant cascades• Computing Elimination Ideals and Discriminants of Likelihood Equations• Multigrid Optimization for Large-Scale Ptychographic Phase Retrieval• Spiking and collapising in large noise limits of SDE’s
Like this:
Like Loading…
Related