Developmental Bayesian Optimization of Black-Box with Visual Similarity-Based Transfer Learning
We present a developmental framework based on a long-term memory and reasoning mechanisms (Vision Similarity and Bayesian Optimisation). This architecture allows a robot to optimize autonomously hyper-parameters that need to be tuned from any action and/or vision module, treated as a black-box. The learning can take advantage of past experiences (stored in the episodic and procedural memories) in order to warm-start the exploration using a set of hyper-parameters previously optimized from objects similar to the new unknown one (stored in a semantic memory). As example, the system has been used to optimized 9 continuous hyper-parameters of a professional software (Kamido) both in simulation and with a real robot (industrial robotic arm Fanuc) with a total of 13 different objects. The robot is able to find a good object-specific optimization in 68 (simulation) or 40 (real) trials. In simulation, we demonstrate the benefit of the transfer learning based on visual similarity, as opposed to an amnesic learning (i.e. learning from scratch all the time). Moreover, with the real robot, we show that the method consistently outperforms the manual optimization from an expert with less than 2 hours of training time to achieve more than 88% of success.
A Machine Learning Approach to Shipping Box Design
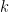
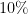
Towards a Hands-Free Query Optimizer through Deep Learning
Query optimization remains one of the most important and well-studied problems in database systems. However, traditional query optimizers are complex heuristically-driven systems, requiring large amounts of time to tune for a particular database and requiring even more time to develop and maintain in the first place. In this vision paper, we argue that a new type of query optimizer, based on deep reinforcement learning, can drastically improve on the state-of-the-art. We identify potential complications for future research that integrates deep learning with query optimization and describe three novel deep learning based approaches that can lead the way to end-to-end learning-based query optimizers.
Predicting computational reproducibility of data analysis pipelines in large population studies using collaborative filtering
Evaluating the computational reproducibility of data analysis pipelines has become a critical issue. It is, however, a cumbersome process for analyses that involve data from large populations of subjects, due to their computational and storage requirements. We present a method to predict the computational reproducibility of data analysis pipelines in large population studies. We formulate the problem as a collaborative filtering process, with constraints on the construction of the training set. We propose 6 different strategies to build the training set, which we evaluate on 2 datasets, a synthetic one modeling a population with a growing number of subject types, and a real one obtained with neuroinformatics pipelines. Results show that one sampling method, ‘Random File Numbers (Uniform)’ is able to predict computational reproducibility with a good accuracy. We also analyze the relevance of including file and subject biases in the collaborative filtering model. We conclude that the proposed method is able to speedup reproducibility evaluations substantially, with a reduced accuracy loss.
Batch-normalized Recurrent Highway Networks
Gradient control plays an important role in feed-forward networks applied to various computer vision tasks. Previous work has shown that Recurrent Highway Networks minimize the problem of vanishing or exploding gradients. They achieve this by setting the eigenvalues of the temporal Jacobian to 1 across the time steps. In this work, batch normalized recurrent highway networks are proposed to control the gradient flow in an improved way for network convergence. Specifically, the introduced model can be formed by batch normalizing the inputs at each recurrence loop. The proposed model is tested on an image captioning task using MSCOCO dataset. Experimental results indicate that the batch normalized recurrent highway networks converge faster and performs better compared with the traditional LSTM and RHN based models.
Measures of correlation and mixtures of product measures
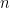
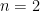



Repair-Based Degrees of Database Inconsistency: Computation and Complexity
We propose a generic numerical measure of the inconsistency of a database with respect to a set of integrity constraints. It is based on an abstract repair semantics. In particular, an inconsistency measure associated to cardinality-repairs is investigated in detail. More specifically, it is shown that it can be computed via answer-set programs, but sometimes its computation can be intractable in data complexity. However, polynomial-time fixed-parameter exact computation, and also deterministic and randomized approximations are exhibited. The behavior of this measure under small updates is analyzed. Furthermore, alternative inconsistency measures are proposed and discussed.
Multi-task Learning for Financial Forecasting
Financial forecasting is challenging and attractive in machine learning. There are many classic solutions, as well as many deep learning based methods, proposed to deal with it yielding encouraging performance. Stock time series forecasting is the most representative problem in financial forecasting. Due to the strong connections among stocks, the information valuable for forecasting is not only included in individual stocks, but also included in the stocks related to them. However, most previous works focus on one single stock, which easily ignore the valuable information in others. To leverage more information, in this paper, we propose a jointly forecasting approach to process multiple time series of related stocks simultaneously, using multi-task learning framework. Compared to the previous works, we use multiple networks to forecast multiple related stocks, using the shared and private information of them simultaneously through multi-task learning. Moreover, we propose an attention method learning an optimized weighted combination of shared and private information based on the idea of Capital Asset Pricing Model (CAPM) to help forecast. Experimental results on various data show improved forecasting performance over baseline methods.
Making View Update Strategies Programmable – Toward Controlling and Sharing Distributed Data –
Views are known mechanisms for controlling access of data and for sharing data of different schemas. Despite long and intensive research on views in both the database community and the programming language community, we are facing difficulties to use views in practice. The main reason is that we lack ways to directly describe view update strategies to deal with the inherent ambiguity of view updating. This paper aims to provide a new language-based approach to controlling and sharing distributed data based on views, and establish a software foundation for systematic construction of such data management systems. Our key observation is that a view should be defined through a view update strategy rather than a view definition. We show that Datalog can be used for specifying view update strategies whose unique view definition can be automatically derived, present a novel P2P-based programmable architecture for distributed data management where updatable views are fully utilized for controlling and sharing distributed data, and demonstrate its usefulness through the development of a privacy-preserving ride-sharing alliance system.
Queue-based Resampling for Online Class Imbalance Learning
Online class imbalance learning constitutes a new problem and an emerging research topic that focusses on the challenges of online learning under class imbalance and concept drift. Class imbalance deals with data streams that have very skewed distributions while concept drift deals with changes in the class imbalance status. Little work exists that addresses these challenges and in this paper we introduce queue-based resampling, a novel algorithm that successfully addresses the co-existence of class imbalance and concept drift. The central idea of the proposed resampling algorithm is to selectively include in the training set a subset of the examples that appeared in the past. Results on two popular benchmark datasets demonstrate the effectiveness of queue-based resampling over state-of-the-art methods in terms of learning speed and quality.
When Truth Discovery Meets Medical Knowledge Graph: Estimating Trustworthiness Degree for Medical Knowledge Condition
Medical knowledge graph is the core component for various medical applications such as automatic diagnosis and question-answering. However, medical knowledge usually associates with certain conditions, which can significantly affect the performance of the supported applications. In the light of this challenge, we propose a new truth discovery method to explore medical-related texts and infer trustworthiness degrees of knowledge triples associating with different conditions. Experiments on both synthetic and real-world datasets demonstrate the effectiveness of the proposed truth discovery method.
Image Reconstruction Using Deep Learning
This paper proposes a deep learning architecture that attains statistically significant improvements over traditional algorithms in Poisson image denoising espically when the noise is strong. Poisson noise commonly occurs in low-light and photon- limited settings, where the noise can be most accurately modeled by the Poission distribution. Poisson noise traditionally prevails only in specific fields such as astronomical imaging. However, with the booming market of surveillance cameras, which commonly operate in low-light environments, or mobile phones, which produce noisy night scene pictures due to lower-grade sensors, the necessity for an advanced Poisson image denoising algorithm has increased. Deep learning has achieved amazing breakthroughs in other imaging problems, such image segmentation and recognition, and this paper proposes a deep learning denoising network that outperforms traditional algorithms in Poisson denoising especially when the noise is strong. The architecture incorporates a hybrid of convolutional and deconvolutional layers along with symmetric connections. The denoising network achieved statistically significant 0.38dB, 0.68dB, and 1.04dB average PSNR gains over benchmark traditional algorithms in experiments with image peak values 4, 2, and 1. The denoising network can also operate with shorter computational time while still outperforming the benchmark algorithm by tuning the reconstruction stride sizes.
Entropy versions of additive inequalities
The connection between inequalities in additive combinatorics and analogous versions in terms of the entropy of random variables has been extensively explored over the past few years. This paper extends a device introduced by Ruzsa in his seminal work introducing this correspondence. This extension provides a toolbox for establishing the equivalence between sumset inequalities and their entropic versions. It supplies simpler proofs of known results and opens a path for obtaining new ones. Some new examples in nonabelian groups illustrate the power of the device.
Scheduling on (Un-)Related Machines with Setup Times


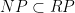
Generating Ontologies from Templates: A Rule-Based Approach for Capturing Regularity
We present a second-order language that can be used to succinctly specify ontologies in a consistent and transparent manner. This language is based on ontology templates (OTTR), a framework for capturing recurring patterns of axioms in ontological modelling. The language and our results are independent of any specific DL. We define the language and its semantics, including the case of negation-as-failure, investigate reasoning over ontologies specified using our language, and show results about the decidability of useful reasoning tasks about the language itself. We also state and discuss some open problems that we believe to be of interest.
Statistical dependence: Beyond Pearson’s $ρ$
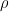
Sample Efficient Adaptive Text-to-Speech
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.
Learning to Train a Binary Neural Network
Convolutional neural networks have achieved astonishing results in different application areas. Various methods which allow us to use these models on mobile and embedded devices have been proposed. Especially binary neural networks seem to be a promising approach for these devices with low computational power. However, understanding binary neural networks and training accurate models for practical applications remains a challenge. In our work, we focus on increasing our understanding of the training process and making it accessible to everyone. We publish our code and models based on BMXNet for everyone to use. Within this framework, we systematically evaluated different network architectures and hyperparameters to provide useful insights on how to train a binary neural network. Further, we present how we improved accuracy by increasing the number of connections in the network.
On the Regret Minimization of Nonconvex Online Gradient Ascent for Online PCA
Non-convex optimization with global convergence guarantees is gaining significant interest in machine learning research in recent years. However, while most works consider either offline settings in which all data is given beforehand, or simple online stochastic i.i.d. settings, very little is known about non-convex optimization for adversarial online learning settings. In this paper we focus on the problem of Online Principal Component Analysis in the regret minimization framework. For this problem, all existing regret minimization algorithms are based on a positive semidefinite convex relaxation, and hence require quadratic memory and SVD computation (either thin of full) on each iteration, which amounts to at least quadratic runtime per iteration. This is in stark contrast to a corresponding stochastic i.i.d. variant of the problem which admits very efficient gradient ascent algorithms that work directly on the natural non-convex formulation of the problem, and hence require only linear memory and linear runtime per iteration. This raises the question: \textit{can non-convex online gradient ascent algorithms be shown to minimize regret in online adversarial settings?} In this paper we take a step forward towards answering this question. We introduce an \textit{adversarially-perturbed spiked-covariance model} in which, each data point is assumed to follow a fixed stochastic distribution, but is then perturbed by adversarial noise. We show that in a certain regime of parameters, when the non-convex online gradient ascent algorithm is initialized with a ‘warm-start’ vector, it provably minimizes the regret with high probability. We further discuss the possibility of computing such a ‘warm-start’ vector. Our theoretical findings are supported by empirical experiments on both synthetic and real-world data.
Benchmarking in cluster analysis: A white paper
To achieve scientific progress in terms of building a cumulative body of knowledge, careful attention to benchmarking is of the utmost importance. This means that proposals of new methods of data pre-processing, new data-analytic techniques, and new methods of output post-processing, should be extensively and carefully compared with existing alternatives, and that existing methods should be subjected to neutral comparison studies. To date, benchmarking and recommendations for benchmarking have been frequently seen in the context of supervised learning. Unfortunately, there has been a dearth of guidelines for benchmarking in an unsupervised setting, with the area of clustering as an important subdomain. To address this problem, discussion is given to the theoretical conceptual underpinnings of benchmarking in the field of cluster analysis by means of simulated as well as empirical data. Subsequently, the practicalities of how to address benchmarking questions in clustering are dealt with, and foundational recommendations are made.
Model-free Study of Ordinary Least Squares Linear Regression
Ordinary least squares (OLS) linear regression is one of the most basic statistical techniques for data analysis. In the main stream literature and the statistical education, the study of linear regression is typically restricted to the case where the covariates are fixed, errors are mean zero Gaussians with variance independent of the (fixed) covariates. Even though OLS has been studied under misspecification from as early as the 1960’s, the implications have not yet caught up with the main stream literature and applied sciences. The present article is an attempt at a unified viewpoint that makes the various implications of misspecification stand out.
Dropout Distillation for Efficiently Estimating Model Confidence
We propose an efficient way to output better calibrated uncertainty scores from neural networks. The Distilled Dropout Network (DDN) makes standard (non-Bayesian) neural networks more introspective by adding a new training loss which prevents them from being overconfident. Our method is more efficient than Bayesian neural networks or model ensembles which, despite providing more reliable uncertainty scores, are more cumbersome to train and slower to test. We evaluate DDN on the the task of image classification on the CIFAR-10 dataset and show that our calibration results are competitive even when compared to 100 Monte Carlo samples from a dropout network while they also increase the classification accuracy. We also propose better calibration within the state of the art Faster R-CNN object detection framework and show, using the COCO dataset, that DDN helps train better calibrated object detectors.
A novel active learning framework for classification: using weighted rank aggregation to achieve multiple query criteria
Multiple query criteria active learning (MQCAL) methods have a higher potential performance than conventional active learning methods in which only one criterion is deployed for sample selection. A central issue related to MQCAL methods concerns the development of an integration criteria strategy (ICS) that makes full use of all criteria. The conventional ICS adopted in relevant research all facilitate the desired effects, but several limitations still must be addressed. For instance, some of the strategies are not sufficiently scalable during the design process, and the number and type of criteria involved are dictated. Thus, it is challenging for the user to integrate other criteria into the original process unless modifications are made to the algorithm. Other strategies are too dependent on empirical parameters, which can only be acquired by experience or cross-validation and thus lack generality; additionally, these strategies are counter to the intention of active learning, as samples need to be labeled in the validation set before the active learning process can begin. To address these limitations, we propose a novel MQCAL method for classification tasks that employs a third strategy via weighted rank aggregation. The proposed method serves as a heuristic means to select high-value samples of high scalability and generality and is implemented through a three-step process: (1) the transformation of the sample selection to sample ranking and scoring, (2) the computation of the self-adaptive weights of each criterion, and (3) the weighted aggregation of each sample rank list. Ultimately, the sample at the top of the aggregated ranking list is the most comprehensively valuable and must be labeled. Several experiments generating 257 wins, 194 ties and 49 losses against other state-of-the-art MQCALs are conducted to verify that the proposed method can achieve superior results.
Scalar Arithmetic Multiple Data: Customizable Precision for Deep Neural Networks

Counterfactual Fairness in Text Classification through Robustness
In this paper, we study counterfactual fairness in text classification, which asks the question: How would the prediction change if the sensitive attribute discussed in the example were something else? We offer a heuristic for measuring this particular form of fairness in text classifiers by substituting individual tokens pertaining to attributes (e.g. sexual orientation, race, and religion), and describe the relationship with other notions, including individual and group fairness. Further, we offer methods, including hard ablation, blindness, and counterfactual logit pairing, for optimizing this counterfactual fairness metric during model training, bridging the robustness literature and the fairness literature. Empirically, counterfactual logit pairing performs as well as hard ablation and blindness to sensitive tokens, but generalizes better to unseen tokens. Interestingly, we find that in practice, the methods do not significantly harm classifier performance, and have varying tradeoffs with group fairness. These approaches, both for measurement and optimization, provide a new path forward for addressing counterfactual fairness issues.
Scalable visualisation methods for modern Generalized Additive Models
In the last two decades the growth of computational resources has made it possible to handle Generalized Additive Models (GAMs) that formerly were too costly for serious applications. However, the growth in model complexity has not been matched by improved visualisations for model development and results presentation. Motivated by an industrial application in electricity load forecasting, we identify the areas where the lack of modern visualisation tools for GAMs is particularly severe, and we address the shortcomings of existing methods by proposing a set of visual tools that a) are fast enough for interactive use, b) exploit the additive structure of GAMs, c) scale to large data sets and d) can be used in conjunction with a wide range of response distributions. All the new visual methods proposed in this work are implemented by the mgcViz R package, which can be found on the Comprehensive R Archive Network.
Inference for Individual Mediation Effects and Interventional Effects in Sparse High-Dimensional Causal Graphical Models
We consider the problem of identifying intermediate variables (or mediators) that regulate the effect of a treatment on a response variable. While there has been significant research on this topic, little work has been done when the set of potential mediators is high-dimensional and when they are interrelated. In particular, we assume that the causal structure of the treatment, the potential mediators and the response is a directed acyclic graph (DAG). High-dimensional DAG models have previously been used for the estimation of causal effects from observational data and methods called IDA and joint-IDA have been developed for estimating the effects of single interventions and multiple simultaneous interventions respectively. In this paper, we propose an IDA-type method called MIDA for estimating mediation effects from high-dimensional observational data. Although IDA and joint-IDA estimators have been shown to be consistent in certain sparse high-dimensional settings, their asymptotic properties such as convergence in distribution and inferential tools in such settings remained unknown. We prove high-dimensional consistency of MIDA for linear structural equation models with sub-Gaussian errors. More importantly, we derive distributional convergence results for MIDA in similar high-dimensional settings, which are applicable to IDA and joint-IDA estimators as well. To the best of our knowledge, these are the first distributional convergence results facilitating inference for IDA-type estimators. These results have been built on our novel theoretical results regarding uniform bounds for linear regression estimators over varying subsets of high-dimensional covariates, which may be of independent interest. Finally, we empirically validate our asymptotic theory and demonstrate the usefulness of MIDA in identifying large mediation effects via simulations and application to real data in genomics.
• Computer-Aided Diagnosis of Label-Free 3-D Optical Coherence Microscopy Images of Human Cervical Tissue• Multi-Scale Fully Convolutional Network for Cardiac Left Ventricle Segmentation• Visual Diver Recognition for Underwater Human-Robot Collaboration• Learning to Interpret Satellite Images Using Wikipedia• High Performance Zero-Memory Overhead Direct Convolutions• Recent progress in semantic image segmentation• Generic Vehicle Tracking Framework Capable of Handling Occlusions Based on Modified Mixture Particle Filter• C4Synth: Cross-Caption Cycle-Consistent Text-to-Image Synthesis• Empty Cities: Image Inpainting for a Dynamic-Object-Invariant Space• ConvPath: A Software Tool for Lung Adenocarcinoma Digital Pathological Image Analysis Aided by Convolutional Neural Network• Classifying Mammographic Breast Density by Residual Learning• Predicting the confirmation time of Bitcoin transactions• Seeding Deep Learning using Wireless Localization• Leveraging Transfer Learning for Segmenting Lesions and their Attributes in Dermoscopy Images• Autonomously and Simultaneously Refining Deep Neural Network Parameters by a Bi-Generative Adversarial Network Aided Genetic Algorithm• Cylindrical Transform: 3D Semantic Segmentation of Kidneys With Limited Annotated Images• WaveCycleGAN: Synthetic-to-natural speech waveform conversion using cycle-consistent adversarial networks• Second Order Optimality Conditions for Optimal Control Problems Governed by 2D Nonlocal Cahn Hilliard Navier Stokes Equations• On Supports of Sums of Nonnegative Circuit Polynomials• An Adaptive Tabu Search Algorithm for Market Clearing Problem in Turkish Day-Ahead Market• Adding Neural Network Controllers to Behavior Trees without Destroying Performance Guarantees• When is there a Representer Theorem? Reflexive Banach spaces• dynamicMF: A Matrix Factorization Approach to Monitor Resource Usage in High Performance Computing Systems• Learning-Based Delay-Aware Caching in Wireless D2D Caching Networks• Ramsey and Gallai-Ramsey numbers for two classes of unicyclic graphs• Cellular-automaton decoders with provable thresholds for topological codes• A Quantum Multiparty Packing Lemma and the Relay Channel• ‘Senator, We Sell Ads’: Analysis of the 2016 Russian Facebook Ads Campaign• Bayesian inference for PCA and MUSIC algorithms with unknown number of sources• Open Source Presentation Attack Detection Baseline for Iris Recognition• Berry-Esseen bounds in the inhomogeneous Curie-Weiss model with external field• A FEM for an optimal control problem subject to the fractional Laplace equation• A reaction coefficient identification problem for fractional diffusion• Graph Convolution over Pruned Dependency Trees Improves Relation Extraction• Monge-Ampère Flow for Generative Modeling• Content Based Image Retrieval from AWiFS Images Repository of IRS Resourcesat-2 Satellite Based on Water Bodies and Burnt Areas• On some properties of LS algebras• Absent-minded passengers• On some distance-regular graphs with many vertices• Optimal scheduling of isolated microgrid with an electric vehicle battery swapping station in multi-stakeholder scenarios: a bi-level programming approach via real-time pricing• Trading information complexity for error II• Left Ventricle Segmentation and Quantification from Cardiac Cine MR Images via Multi-task Learning• Optimal Noise-Adding Mechanism in Additive Differential Privacy• Symmetry Exploits for Bayesian Cubature Methods• CNN-based Pore Detection and Description for High-Resolution Fingerprint Recognition• A Kernel for Multi-Parameter Persistent Homology• Learning Preconditioners on Lie Groups• Experimental Evaluation of Continuum Deformation with a Five Quadrotor Team• Deeply Informed Neural Sampling for Robot Motion Planning• Scaling simulation-to-real transfer by learning composable robot skills• VelocityGAN: Data-Driven Full-Waveform Inversion Using Conditional Adversarial Networks• Counting Shellings of Complete Bipartite Graphs and Trees• Supporting Answerers with Feedback in Social Q• Semantic Sentence Embeddings for Paraphrasing and Text Summarization• Reviews Matter: How Distributed Mentoring Predicts Lexical Diversity on FanFiction.net• Semantically Invariant Text-to-Image Generation• Growing and Retaining AI Talent for the United States Government• Unsupervised Person Image Synthesis in Arbitrary Poses• Adaptive Pruning of Neural Language Models for Mobile Devices• Asymptotic Loss in Privacy due to Dependency in Gaussian Traces• Geometry-Aware Network for Non-Rigid Shape Prediction from a Single View• Using SOS for Optimal Semialgebraic Representation of Sets: Finding Minimal Representations of Limit Cycles, Chaotic Attractors and Unions• Vector Learning for Cross Domain Representations• Efficient Dictionary Learning with Gradient Descent• Smooth Inter-layer Propagation of Stabilized Neural Networks for Classification• Improved Bound on Sets Including No Sunflower with Three Petals• Iterative Document Representation Learning Towards Summarization with Polishing• Being Corrupt Requires Being Clever, But Detecting Corruption Doesn’t• Boosting Trust Region Policy Optimization by Normalizing Flows Policy• Diagnostics in Semantic Segmentation• Evaluation of Ride-Sourcing Search Frictions and Driver Productivity: A Spatial Denoising Approach• On some variance reduction properties of the reparameterization trick• Using Autoencoders To Learn Interesting Features For Detecting Surveillance Aircraft• An oracle-based projection and rescaling algorithm for linear semi-infinite feasibility problems and its application to SDP and SOCP• Deep Graph Infomax• Maximizing spectral radius and number of spanning trees in bipartite graphs• Multi-View Frame Reconstruction with Conditional GAN• $(g,f)$-Chromatic spanning trees and forests• Optimal Exploitation of Subspace Prior Information in Matrix Sensing• PolyShard: Coded Sharding Achieves Linearly Scaling Efficiency and Security Simultaneously• Spanoids – an abstraction of spanning structures, and a barrier for LCCs• An analytic theory of generalization dynamics and transfer learning in deep linear networks• Simultaneous Scheduling of Multiple Frequency Services in Stochastic Unit Commitment• A parameter estimator based on Smoluchowski-Kramers approximation• An Intelligent Extraversion Analysis Scheme from Crowd Trajectories for Surveillance• A Prototype Performance Analysis for V2V Communications using USRP-based Software Defined Radio Platform• Deformable Object Tracking with Gated Fusion• A State-Space Model for Assimilating Passenger and Vehicle Flow Data with User Feedback in a Transit Network• Towards increased trustworthiness of deep learning segmentation methods on cardiac MRI• CNN Based Posture-Free Hand Detection• Impact of Integrated Circuit Packaging on Synaptic Dynamics of Memristive Devices• Wafer Quality Inspection using Memristive LSTM, ANN, DNN and HTM• Compressing the Input for CNNs with the First-Order Scattering Transform• A Way to Facilitate Decision Making in a Mixed Group of Manned and Unmanned Aerial Vehicles• New Radio beam-based Access to Unlicensed Spectrum: Design Challenges and Solutions• Solving Linear Bilevel Problems Using Big-Ms: Not All That Glitters Is Gold• A Simple Framework to Leverage State-Of-The-Art Single-Image Super-Resolution Methods to Restore Light Fields• Sequence Block based Compressed Sensing Multiuser Detection for 5G• On the Use of Metacognitive Evidence in Feedback-free Situations: Advice-taking and Trust Formation• Novel Codebook-based MC-CDMA with Compressive Sensing Multiuser Detection for Sporadic mMTC• Robust covariance estimation under $L_4-L_2$ norm equivalence• Edge and Corner Detection for Unorganized 3D Point Clouds with Application to Robotic Welding• Probabilistic Analysis of Edge Elimination for Euclidean TSP• Singular vector and singular subspace distribution for the matrix denoising model• Fast Stochastic Algorithms for Low-rank and Nonsmooth Matrix Problems• Budgeted Multi-Objective Optimization with a Focus on the Central Part of the Pareto Front – Extended Version• No New-Net• nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation• How does uncertainty about other voters determine a strategic vote?• A new consensus metric for Likert scales• Effective dynamics for non-reversible stochastic differential equations: a quantitative study• Collective behavior recognition using compact descriptors• Equilibria in Quantitative Concurrent Games• A rotation-equivariant convolutional neural network model of primary visual cortex• The Convergence of Sparsified Gradient Methods• Distance and routing labeling schemes for cube-free median graphs• Towards the optimal construction of a loss function without spurious local minima for solving quadratic equations• Consistency and Variation in Kernel Neural Ranking Model• Packing of Circles on Square Flat Torus as Global Optimization of Mixed Integer Nonlinear problem• Physics Informed Topology Learning in Networks of Linear Dynamical Systems• Identifying Long Term Voltage Stability Caused by Distribution Systems vs Transmission Systems• Novel Sparse Recovery Algorithms for 3D Debris Localization using Rotating Point Spread Function Imagery• Towards a classification of Lindenmayer systems• Convergence rate of Markov chains and hybrid numerical schemes to jump-diffusions with application to the Bates model• Real-time 3D Pose Estimation with a Monocular Camera Using Deep Learning and Object Priors On an Autonomous Racecar• Obladi: Oblivious Serializable Transactions in the Cloud• Modeling and Loop Shaping of Single-Joint Amplification Exoskeleton with Contact Sensing and Series Elastic Actuation• Weak order and descents for monotone triangles• Topological Insulator in an Atomic Liquid• Reoptimization of Parameterized Problems• On the Impact of Spillover Losses in 28 GHz Rotman Lens Arrays for 5G Applications• Kernel based low-rank sparse model for single image super-resolution• Industrial and Tramp Ship Routing Problems: Closing the Gap for Real-Scale Instances• Property testing and expansion in cubical complexes• A Deep Learning Approach to Denoise Optical Coherence Tomography Images of the Optic Nerve Head• On limited-memory quasi-Newton methods for minimizing a quadratic function• A note on connectivity of splitting matroids• AlphaGomoku: An AlphaGo-based Gomoku Artificial Intelligence using Curriculum Learning• Solving Statistical Mechanics using Variational Autoregressive Networks• A Successive-Elimination Approach to Adaptive Robotic Sensing• Enabling FAIR Research in Earth Science through Research Objects• Contamination Source Detection in Water Distribution Networks using Belief Propagation• Generative replay with feedback connections as a general strategy for continual learning• Conditional WaveGAN• Sharing Information with Competitors• Heat current rectification and mobility edges• Predictive Embeddings for Hate Speech Detection on Twitter• On the existence and uniqueness of the solution of a parabolic optimal control problem with uncertain inputs• Bohemian Upper Hessenberg Matrices• New Direct Numerical Methods for Some Multidimensional Problems of the Calculus of Variations• Learning to Coordinate Multiple Reinforcement Learning Agents for Diverse Query Reformulation• Tropical mirror symmetry in dimension one• Bohemian Upper Hessenberg Toeplitz Matrices
Like this:
Like Loading…
Related