Text Summarization as Tree Transduction by Top-Down TreeLSTM
Extractive compression is a challenging natural language processing problem. This work contributes by formulating neural extractive compression as a parse tree transduction problem, rather than a sequence transduction task. Motivated by this, we introduce a deep neural model for learning structure-to-substructure tree transductions by extending the standard Long Short-Term Memory, considering the parent-child relationships in the structural recursion. The proposed model can achieve state of the art performance on sentence compression benchmarks, both in terms of accuracy and compression rate.
Stack-sorting for Words

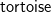
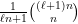



Decision Level Fusion: An Event Driven Approach
This paper presents a technique that combines the occurrence of certain events, as observed by different sensors, in order to detect and classify objects. This technique explores the extent of dependence between features being observed by the sensors, and generates more informed probability distributions over the events. Provided some additional information about the features of the object, this fusion technique can outperform other existing decision level fusion approaches that may not take into account the relationship between different features.
From Audio to Semantics: Approaches to end-to-end spoken language understanding
Conventional spoken language understanding systems consist of two main components: an automatic speech recognition module that converts audio to a transcript, and a natural language understanding module that transforms the resulting text (or top N hypotheses) into a set of domains, intents, and arguments. These modules are typically optimized independently. In this paper, we formulate audio to semantic understanding as a sequence-to-sequence problem [1]. We propose and compare various encoder-decoder based approaches that optimize both modules jointly, in an end-to-end manner. Evaluations on a real-world task show that 1) having an intermediate text representation is crucial for the quality of the predicted semantics, especially the intent arguments and 2) jointly optimizing the full system improves overall accuracy of prediction. Compared to independently trained models, our best jointly trained model achieves similar domain and intent prediction F1 scores, but improves argument word error rate by 18% relative.
A Distance-based Framework for Gaussian Processes over Probability Distributions
Gaussian processes constitute a very powerful and well-understood method for non-parametric regression and classification. In the classical framework, the training data consists of deterministic vector-valued inputs and the corresponding (noisy) measurements whose joint distribution is assumed to be Gaussian. In many practical applications, however, the inputs are either noisy, i.e., each input is a vector-valued sample from an unknown probability distribution, or the probability distributions are the inputs. In this paper, we address Gaussian process regression with inputs given in form of probability distributions and propose a framework that is based on distances between such inputs. To this end, we review different admissible distance measures and provide a numerical example that demonstrates our framework.
No Multiplication? No Floating Point? No Problem! Training Networks for Efficient Inference
For successful deployment of deep neural networks on highly–resource-constrained devices (hearing aids, earbuds, wearables), we must simplify the types of operations and the memory/power resources used during inference. Completely avoiding inference-time floating-point operations is one of the simplest ways to design networks for these highly-constrained environments. By discretizing both our in-network non-linearities and our network weights, we can move to simple, compact networks without floating point operations, without multiplications, and avoid all non-linear function computations. Our approach allows us to explore the spectrum of possible networks, ranging from fully continuous versions down to networks with bi-level weights and activations. Our results show that discretization can be done without loss of performance and that we can train a network that will successfully operate without floating-point, without multiplication, and with less RAM on both regression tasks (auto encoding) and multi-class classification tasks (ImageNet). The memory needed to deploy our discretized networks is less than one third of the equivalent architecture that does use floating-point operations.
Evaluating Fairness Metrics in the Presence of Dataset Bias
Data-driven algorithms play a large role in decision making across a variety of industries. Increasingly, these algorithms are being used to make decisions that have significant ramifications for people’s social and economic well-being, e.g. in sentencing, loan approval, and policing. Amid the proliferation of such systems there is a growing concern about their potential discriminatory impact. In particular, machine learning systems which are trained on biased data have the potential to learn and perpetuate those biases. A central challenge for practitioners is thus to determine whether their models display discriminatory bias. Here we present a case study in which we frame the issue of bias detection as a causal inference problem with observational data. We enumerate two main causes of bias, sampling bias and label bias, and we investigate the abilities of six different fairness metrics to detect each bias type. Based on these investigations, we propose a set of best practice guidelines to select the fairness metric that is most likely to detect bias if it is present. Additionally, we aim to identify the conditions in which certain fairness metrics may fail to detect bias and instead give practitioners a false belief that their biased model is making fair decisions.
Asynchronous decentralized accelerated stochastic gradient descent


Resilient Computing with Reinforcement Learning on a Dynamical System: Case Study in Sorting
Robots and autonomous agents often complete goal-based tasks with limited resources, relying on imperfect models and sensor measurements. In particular, reinforcement learning (RL) and feedback control can be used to help a robot achieve a goal. Taking advantage of this body of work, this paper formulates general computation as a feedback-control problem, which allows the agent to autonomously overcome some limitations of standard procedural language programming: resilience to errors and early program termination. Our formulation considers computation to be trajectory generation in the program’s variable space. The computing then becomes a sequential decision making problem, solved with reinforcement learning (RL), and analyzed with Lyapunov stability theory to assess the agent’s resilience and progression to the goal. We do this through a case study on a quintessential computer science problem, array sorting. Evaluations show that our RL sorting agent makes steady progress to an asymptotically stable goal, is resilient to faulty components, and performs less array manipulations than traditional Quicksort and Bubble sort.
Neural Networks with Structural Resistance to Adversarial Attacks
In adversarial attacks to machine-learning classifiers, small perturbations are added to input that is correctly classified. The perturbations yield adversarial examples, which are virtually indistinguishable from the unperturbed input, and yet are misclassified. In standard neural networks used for deep learning, attackers can craft adversarial examples from most input to cause a misclassification of their choice. We introduce a new type of network units, called RBFI units, whose non-linear structure makes them inherently resistant to adversarial attacks. On permutation-invariant MNIST, in absence of adversarial attacks, networks using RBFI units match the performance of networks using sigmoid units, and are slightly below the accuracy of networks with ReLU units. When subjected to adversarial attacks, networks with RBFI units retain accuracies above 90% for attacks that degrade the accuracy of networks with ReLU or sigmoid units to below 2%. RBFI networks trained with regular input are superior in their resistance to adversarial attacks even to ReLU and sigmoid networks trained with the help of adversarial examples. The non-linear structure of RBFI units makes them difficult to train using standard gradient descent. We show that networks of RBFI units can be efficiently trained to high accuracies using pseudogradients, computed using functions especially crafted to facilitate learning instead of their true derivatives. We show that the use of pseudogradients makes training deep RBFI networks practical, and we compare several structural alternatives of RBFI networks for their accuracy.
Graph filtering for data reduction and reconstruction
A novel approach is put forth that utilizes data similarity, quantified on a graph, to improve upon the reconstruction performance of principal component analysis. The tasks of data dimensionality reduction and reconstruction are formulated as graph filtering operations, that enable the exploitation of data node connectivity in a graph via the adjacency matrix. The unknown reducing and reconstruction filters are determined by optimizing a mean-square error cost that entails the data, as well as their graph adjacency matrix. Working in the graph spectral domain enables the derivation of simple gradient descent recursions used to update the matrix filter taps. Numerical tests in real image datasets demonstrate the better reconstruction performance of the novel method over standard principal component analysis.
Tree-Based Optimization: A Meta-Algorithm for Metaheuristic Optimization
Designing search algorithms for finding global optima is one of the most active research fields, recently. These algorithms consist of two main categories, i.e., classic mathematical and metaheuristic algorithms. This article proposes a meta-algorithm, Tree-Based Optimization (TBO), which uses other heuristic optimizers as its sub-algorithms in order to improve the performance of search. The proposed algorithm is based on mathematical tree subject and improves performance and speed of search by iteratively removing parts of the search space having low fitness, in order to minimize and purify the search space. The experimental results on several well-known benchmarks show the outperforming performance of TBO algorithm in finding the global solution. Experiments on high dimensional search spaces show significantly better performance when using the TBO algorithm. The proposed algorithm improves the search algorithms in both accuracy and speed aspects, especially for high dimensional searching such as in VLSI CAD tools for Integrated Circuit (IC) design.
Triply Supervised Decoder Networks for Joint Detection and Segmentation
Joint object detection and semantic segmentation can be applied to many fields, such as self-driving cars and unmanned surface vessels. An initial and important progress towards this goal has been achieved by simply sharing the deep convolutional features for the two tasks. However, this simple scheme is unable to make full use of the fact that detection and segmentation are mutually beneficial. To overcome this drawback, we propose a framework called TripleNet where triple supervisions including detection-oriented supervision, class-aware segmentation supervision, and class-agnostic segmentation supervision are imposed on each layer of the decoder network. Class-agnostic segmentation supervision provides an objectness prior knowledge for both semantic segmentation and object detection. Besides the three types of supervisions, two light-weight modules (i.e., inner-connected module and attention skip-layer fusion) are also incorporated into each layer of the decoder. In the proposed framework, detection and segmentation can sufficiently boost each other. Moreover, class-agnostic and class-aware segmentation on each decoder layer are not performed at the test stage. Therefore, no extra computational costs are introduced at the test stage. Experimental results on the VOC2007 and VOC2012 datasets demonstrate that the proposed TripleNet is able to improve both the detection and segmentation accuracies without adding extra computational costs.
How to Become Instagram Famous: Post Popularity Prediction with Dual-Attention
With a growing number of social apps, people have become increasingly willing to share their everyday photos and events on social media platforms, such as Facebook, Instagram, and WeChat. In social media data mining, post popularity prediction has received much attention from both data scientists and psychologists. Existing research focuses more on exploring the post popularity on a population of users and including comprehensive factors such as temporal information, user connections, number of comments, and so on. However, these frameworks are not suitable for guiding a specific user to make a popular post because the attributes of this user are fixed. Therefore, previous frameworks can only answer the question ‘whether a post is popular’ rather than ‘how to become famous by popular posts’. In this paper, we aim at predicting the popularity of a post for a specific user and mining the patterns behind the popularity. To this end, we first collect data from Instagram. We then design a method to figure out the user environment, representing the content that a specific user is very likely to post. Based on the relevant data, we devise a novel dual-attention model to incorporate image, caption, and user environment. The dual-attention model basically consists of two parts, explicit attention for image-caption pairs and implicit attention for user environment. A hierarchical structure is devised to concatenate the explicit attention part and implicit attention part. We conduct a series of experiments to validate the effectiveness of our model and investigate the factors that can influence the popularity. The classification results show that our model outperforms the baselines, and a statistical analysis identifies what kind of pictures or captions can help the user achieve a relatively high ‘likes’ number.
Improved Parallel Cache-Oblivious Algorithms for Dynamic Programming and Linear Algebra
Hierarchical Deep Multiagent Reinforcement Learning
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.
A Survey of Learning Causality with Data: Problems and Methods
The era of big data provides researchers with convenient access to copious data. However, people often have little knowledge about it. The increasing prevalence of big data is challenging the traditional methods of learning causality because they are developed for the cases with limited amount of data and solid prior causal knowledge. This survey aims to close the gap between big data and learning causality with a comprehensive and structured review of traditional and frontier methods and a discussion about some open problems of learning causality. We begin with preliminaries of learning causality. Then we categorize and revisit methods of learning causality for the typical problems and data types. After that, we discuss the connections between learning causality and machine learning. At the end, some open problems are presented to show the great potential of learning causality with data.
Graph Variogram: A novel tool to measure spatial stationarity
Irregularly sampling a spatially stationary random field does not yield a graph stationary signal in general. Based on this observation, we build a definition of graph stationarity based on intrinsic stationarity, a less restrictive definition of classical stationarity. We introduce the concept of graph variogram, a novel tool for measuring spatial intrinsic stationarity at local and global scales for irregularly sampled signals by selecting subgraphs of local neighborhoods. Graph variograms are extensions of variograms used for signals defined on continuous Euclidean space. Our experiments with intrinsically stationary signals sampled on a graph, demonstrate that graph variograms yield estimates with small bias of true theoretical models, while being robust to sampling variation of the space.
Fully Implicit Online Learning
Regularized online learning is widely used in machine learning. In this paper we analyze a class of regularized online algorithm with both non-linearized losses and non-linearized regularizers, which we call fully implicit online learning (FIOL). It is shown that because of avoiding the error of linearization, an extra additive regret gain can be obtained for FIOL. Then we show that by exploring the structure of the loss and regularizer, each iteration of FIOL can be exactly solved with time comparable to its linearized version, even if no closed-form solution exists. Experiments validate the proposed approaches.
Accelerated Coordinate Descent with Arbitrary Sampling and Best Rates for Minibatches



Sparse-Group Bayesian Feature Selection Using Expectation Propagation for Signal Recovery and Network Reconstruction
We present a Bayesian method for feature selection in the presence of grouping information with sparsity on the between- and within group level. Instead of using a stochastic algorithm for parameter inference, we employ expectation propagation, which is a deterministic and fast algorithm. Available methods for feature selection in the presence of grouping information have a number of short-comings: on one hand, lasso methods, while being fast, underestimate the regression coefficients and do not make good use of the grouping information, and on the other hand, Bayesian approaches, while accurate in parameter estimation, often rely on the stochastic and slow Gibbs sampling procedure to recover the parameters, rendering them infeasible e.g. for gene network reconstruction. Our approach of a Bayesian sparse-group framework with expectation propagation enables us to not only recover accurate parameter estimates in signal recovery problems, but also makes it possible to apply this Bayesian framework to large-scale network reconstruction problems. The presented method is generic but in terms of application we focus on gene regulatory networks. We show on simulated and experimental data that the method constitutes a good choice for network reconstruction regarding the number of correctly selected features, prediction on new data and reasonable computing time.
S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning
State representation learning aims at learning compact representations from raw observations in robotics and control applications. Approaches used for this objective are auto-encoders, learning forward models, inverse dynamics or learning using generic priors on the state characteristics. However, the diversity in applications and methods makes the field lack standard evaluation datasets, metrics and tasks. This paper provides a set of environments, data generators, robotic control tasks, metrics and tools to facilitate iterative state representation learning and evaluation in reinforcement learning settings.
Non-Iterative Knowledge Fusion in Deep Convolutional Neural Networks
Incorporation of a new knowledge into neural networks with simultaneous preservation of the previous one is known to be a nontrivial problem. This problem becomes even more complex when new knowledge is contained not in new training examples, but inside the parameters (connection weights) of another neural network. Here we propose and test two methods allowing combining the knowledge contained in separate networks. One method is based on a simple operation of summation of weights of constituent neural networks. Another method assumes incorporation of a new knowledge by modification of weights nonessential for the preservation of already stored information. We show that with these methods the knowledge from one network can be transferred into another one non-iteratively without requiring training sessions. The fused network operates efficiently, performing classification far better than a chance level. The efficiency of the methods is quantified on several publicly available data sets in classification tasks both for shallow and deep neural networks.
Hypergraph Neural Networks
In this paper, we present a hypergraph neural networks (HGNN) framework for data representation learning, which can encode high-order data correlation in a hypergraph structure. Confronting the challenges of learning representation for complex data in real practice, we propose to incorporate such data structure in a hypergraph, which is more flexible on data modeling, especially when dealing with complex data. In this method, a hyperedge convolution operation is designed to handle the data correlation during representation learning. In this way, traditional hypergraph learning procedure can be conducted using hyperedge convolution operations efficiently. HGNN is able to learn the hidden layer representation considering the high-order data structure, which is a general framework considering the complex data correlations. We have conducted experiments on citation network classification and visual object recognition tasks and compared HGNN with graph convolutional networks and other traditional methods. Experimental results demonstrate that the proposed HGNN method outperforms recent state-of-the-art methods. We can also reveal from the results that the proposed HGNN is superior when dealing with multi-modal data compared with existing methods.
TTMF: A Triple Trustworthiness Measurement Frame for Knowledge Graphs
The Knowledge graph (KG) uses the triples to describe the facts in the real world. It has been widely used in intelligent analysis and understanding of big data. In constructing a KG, especially in the process of automation building, some noises and errors are inevitably introduced or much knowledges is missed. However, learning tasks based on the KG and its underlying applications both assume that the knowledge in the KG is completely correct and inevitably bring about potential errors. Therefore, in this paper, we establish a unified knowledge graph triple trustworthiness measurement framework to calculate the confidence values for the triples that quantify its semantic correctness and the true degree of the facts expressed. It can be used not only to detect and eliminate errors in the KG but also to identify new triples to improve the KG. The framework is a crisscrossing neural network structure. It synthesizes the internal semantic information in the triples and the global inference information of the KG to achieve the trustworthiness measurement and fusion in the three levels of entity-level, relationship-level, and KG-global-level. We conducted experiments on the common dataset FB15K (from Freebase) and analyzed the validity of the model’s output confidence values. We also tested the framework in the knowledge graph error detection or completion tasks. The experimental results showed that compared with other models, our model achieved significant and consistent improvements on the above tasks, further confirming the capabilities of our model.
Defining the Collective Intelligence Supply Chain
Organisations are increasingly open to scrutiny, and need to be able to prove that they operate in a fair and ethical way. Accountability should extend to the production and use of the data and knowledge assets used in AI systems, as it would for any raw material or process used in production of physical goods. This paper considers collective intelligence, comprising data and knowledge generated by crowd-sourced workforces, which can be used as core components of AI systems. A proposal is made for the development of a supply chain model for tracking the creation and use of crowdsourced collective intelligence assets, with a blockchain based decentralised architecture identified as an appropriate means of providing validation, accountability and fairness.
Modeling Dependence via Copula of Functionals of Fourier Coefficients
The goal of this paper is to develop a measure for characterizing complex dependence between stationary time series that cannot be captured by traditional measures such as correlation and coherence. Our approach is to use copula models of functionals of the Fourier coefficients which is a generalization of coherence. Here, we use standard parametric copula models with a single parameter both from elliptical and Archimedean families. Our approach is to analyze changes in local field potentials in the rat cortex prior to and immediately following the onset of stroke. We present the necessary theoretical background, the multivariate models and an illustration of our methodology on these local field potential data. Simulations with non-linear dependent data show information that were missed by not taking into account dependence on specific frequencies. Moreover, these simulations demonstrate how our proposed method captures more complex non-linear dependence between time series. Finally, we illustrate our copula-based approach in the analysis of local field potentials of rats.
Anderson Acceleration for Reinforcement Learning
Anderson acceleration is an old and simple method for accelerating the computation of a fixed point. However, as far as we know and quite surprisingly, it has never been applied to dynamic programming or reinforcement learning. In this paper, we explain briefly what Anderson acceleration is and how it can be applied to value iteration, this being supported by preliminary experiments showing a significant speed up of convergence, that we critically discuss. We also discuss how this idea could be applied more generally to (deep) reinforcement learning.
Evaluating stochastic seeding strategies in networks
When trying to maximize the adoption of a behavior in a population connected by a social network, it is common to strategize about where in the network to seed the behavior. Some seeding strategies require explicit knowledge of the network, which can be difficult to collect, while other strategies do not require such knowledge but instead rely on non-trivial stochastic ingredients. For example, one such stochastic seeding strategy is to select random network neighbors of random individuals, thus exploiting a version of the friendship paradox, whereby the friend of a random individual is expected to have more friends than a random individual. Empirical evaluations of these strategies have demanded large field experiments designed specifically for this purpose, but these experiments have yielded relatively imprecise estimates of the relative efficacy of these seeding strategies. Here we show both how stochastic seeding strategies can be evaluated using existing data arising from randomized experiments in networks designed for other purposes and how to design much more efficient experiments for this specific evaluation. In particular, we consider contrasts between two common stochastic seeding strategies and analyze nonparametric estimators adapted from policy evaluation or importance sampling. Using simulations on real networks, we show that the proposed estimators and designs can dramatically increase precision while yielding valid inference. We apply our proposed estimators to a field experiment that randomly assigned households to an intensive marketing intervention and a field experiment that randomly assigned students to an anti-bullying intervention.
Nonconvex Optimization Meets Low-Rank Matrix Factorization: An Overview
Substantial progress has been made recently on developing provably accurate and efficient algorithms for low-rank matrix factorization via nonconvex optimization. While conventional wisdom often takes a dim view of nonconvex optimization algorithms due to their susceptibility to spurious local minima, simple iterative methods such as gradient descent have been remarkably successful in practice. The theoretical footings, however, had been largely lacking until recently. In this tutorial-style overview, we highlight the important role of statistical models in enabling efficient nonconvex optimization with performance guarantees. We review two contrasting approaches: (1) two-stage algorithms, which consist of a tailored initialization step followed by successive refinement; and (2) global landscape analysis and initialization-free algorithms. Several canonical matrix factorization problems are discussed, including but not limited to matrix sensing, phase retrieval, matrix completion, blind deconvolution, robust principal component analysis, phase synchronization, and joint alignment. Special care is taken to illustrate the key technical insights underlying their analyses. This article serves as a testament that the integrated thinking of optimization and statistics leads to fruitful research findings.
Optimal Change Point Detection and Localization in Sparse Dynamic Networks
We study the problem of change point detection and localization in dynamic networks. We assume that we observe a sequence of independent adjacency matrices of given size, each corresponding to one realization from an unknown inhomogeneous Bernoulli model. The underlying distribution of the adjacency matrices may change over a subset of the time points, called change points. Our task is to recover with high accuracy the unknown number and positions of the change points. Our generic model setting allows for all the model parameters to change with the total number of time points, including the network size, the minimal spacing between consecutive change points, the magnitude of the smallest change and the degree of sparsity of the networks. We first identify an impossible region in the space of the model parameters such that no change point estimator is provably consistent if the data are generated according to parameters falling in that region. We propose a computationally simple novel algorithm for network change point localization, called Network Binary Segmentation, which relies on weighted averages of the adjacency matrices. We show that Network Binary Segmentation is consistent over a range of the model parameters that nearly cover the complement of the impossibility region, thus demonstrating the existence of a phase transition for the problem at hand. Next, we devise a more sophisticated algorithm based on singular value thresholding, called Local Refinement, that delivers more accurate estimates of the change point locations. We show that, under appropriate conditions, Local Refinement guarantees a minimax optimal rate for network change point localization while remaining computationally feasible.
Size Agnostic Change Point Detection Framework for Evolving Networks
Changes in the structure of observed social and complex networks’ structure can indicate a significant underlying change in an organization, or reflect the response of the network to an external event. Automatic detection of change points in evolving networks is rudimentary to the research and the understanding of the effect of such events on networks. Here we present an easy-to-implement and fast framework for change point detection in temporal evolving networks. Unlike previous approaches, our method is size agnostic, and does not require either prior knowledge about the network’s size and structure, nor does it require obtaining historical information or nodal identities over time. We use both synthetic data derived from dynamic models and two real datasets: Enron email exchange and Ask-Ubuntu forum. Our framework succeeds with both precision and recall and outperforms previous solutions
• The inverse cyclotomic Discrete Fourier Transform algorithm• On central fields in the calculus of variations• Learning to Address Health Inequality in the United States with a Bayesian Decision Network• Modified hybrid combination synchronization of chaotic fractional order systems• Low Complexity Full Duplex MIMO: Novel Analog Cancellation Architectures and Transceiver Design• Controllability of Neutral Stochastic Functional Integro-Differential Equations Driven by Fractional Brownian Motion with Hurst Parameter Lesser than 1/2• How to run on rough terrains• Population preferences through Wikipedia edits• A Revised and Verified Proof of the Scalable Commutativity Rule• On Reinforcement Learning for Full-length Game of StarCraft• Central Bank Communication and the Yield Curve: A Semi-Automatic Approach using Non-Negative Matrix Factorization• A family of neighborhood contingency logics• Propagation of wind power induced fluctuations in power grids• Measuring the effect of node aggregation on community detection• The Balanced Connected Subgraph Problem• On $k$-abelian Equivalence and Generalized Lagrange Spectra• Mott, Floquet, and the response of periodically driven Anderson insulators• EpiRL: A Reinforcement Learning Agent to Facilitate Epistasis Detection• Better Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning• Real-Time Monocular Object-Model Aware Sparse SLAM• A First-order Method for Monotone Stochastic Variational Inequalities on Semidefinite Matrix Spaces• Exact adaptive confidence intervals for small areas• Learning without Interaction Requires Separation• Numerical Aspects for Approximating Governing Equations Using Data• Zoom-RNN: A Novel Method for Person Recognition Using Recurrent Neural Networks• Discrete Optimal Control of Interconnected Mechanical Systems• Stochastic Answer Networks for SQuAD 2.0• Towards Automated Post-Earthquake Inspections with Deep Learning-based Condition-Aware Models• Power and Energy-efficiency Roofline Model for GPUs• Realizing Information Erasure in Finite Time• On Finding the Largest Minimum Distance of Locally Recoverable Codes• Tunable Measures for Information Leakage and Applications to Privacy-Utility Tradeoffs• On minimal Ramsey graphs and Ramsey equivalence in multiple colours• Nonconvex Robust Low-rank Matrix Recovery• Flexible Mixture Modeling on Constrained Spaces• Strong and Weak Equilibria for Time-Inconsistent Stochastic Control in Continuous Time• T-count Optimized Quantum Circuits for Bilinear Interpolation• Low Precision Policy Distillation with Application to Low-Power, Real-time Sensation-Cognition-Action Loop with Neuromorphic Computing• Robustness in the Optimization of Risk Measures• Statistics on integer partitions arising from seaweed algebras• A Berry-Esseen theorem for Pitman’s $α$-diversity• Knowledge-Aided Normalized Iterative Hard Thresholding Algorithms and Applications to Sparse Reconstruction• MedAL: Deep Active Learning Sampling Method for Medical Image Analysis• Relating broadcast independence and independence• Covfefe: A Computer Vision Approach For Estimating Force Exertion• Object Detection from Scratch with Deep Supervision• Fast and Simple Mixture of Softmaxes with BPE and Hybrid-LightRNN for Language Generation• Gradient-Based Low-Light Image Enhancement• Optimal Equi-difference Conflict-avoiding Codes• Partitioning The Edge Set of a Hypergraph Into Almost Regular Cycles• Resolvable Cycle Decompositions of Complete Multigraphs and Complete Equipartite Multigraphs via Layering and Detachment• Utilizing Class Information for DNN Representation Shaping• Scenic: Language-Based Scene Generation• A Budget Feasible Peer Graded Mechanism For IoT-Based Crowdsourcing• Floyd-Warshall Reinforcement Learning Learning from Past Experiences to Reach New Goals• $k$-projective sequences I-toward to a generalization of Mahler functions-• Automated, predictive, and interpretable inference of C. elegans escape dynamics• Mutigrid Backprojection Super-Resolution and Deep Filter Visualization• Collaborative Learning for Extremely Low Bit Asymmetric Hashing• Early Identification of Pathogenic Social Media Accounts• Path Planning and Controlled Crash Landing of a Quadcopter in case of a Rotor Failure• A Model-Driven Deep Learning Network for MIMO Detection• Subexponential algorithms for variants of homomorphism problem in string graphs• Note on 3-Choosability of Planar Graphs with Maximum Degree 4• Algorithms for Euclidean Degree Bounded Spanning Tree Problems• The jamming transition as a paradigm to understand the loss landscape of deep neural networks• New and Updated Semidefinite Programming Bounds for Subspace Codes• On the Genus of a quotient of a numerical semigroup• Combinatorics of free and simplicial line arrangements• Adaptive Resonant Beam Charging for Intelligent Wireless Power Transfer• Geometric-based Line Segment Tracking for HDR Stereo Sequences• Optimal Resonant Beam Charging for Electronic Vehicles in Internet of Intelligent Vehicles• Fair Scheduling in Resonant Beam Charging for IoT Devices• Interplay of synchronization mechanisms by common noise and global coupling for a general class of limit-cycle oscillators• An Efficient Framework for Implementing Persist Data Structures on Remote NVM• Pre and Post-hoc Diagnosis and Interpretation of Malignancy from Breast DCE-MRI• Supervised Neural Models Revitalize the Open Relation Extraction• Vehicle Re-Identification in Context• Analysis of Outage Probabilities for Cooperative NOMA Users with Imperfect CSI• Explainable PCGML via Game Design Patterns• Co-Creative Level Design via Machine Learning• Coded Caching with Shared Caches: Fundamental Limits with Uncoded Prefetching• Towards Automated Let’s Play Commentary• Coset construction of Virasoro minimal models and coupling of Wess-Zumino-Witten theory with Schramm-Loewner evolution• Memory Management in Successive-Cancellation based Decoders for Multi-Kernel Polar Codes• Physical Layer Key Generation for Secure Power Line Communications• Temporal Relational Ranking for Stock Prediction• The characteristic function of the discrete Cauchy distribution• Fast Automatic Smoothing for Generalized Additive Models• Nested cross-validation when selecting classifiers is overzealous for most practical applications• Hessian barrier algorithms for linearly constrained optimization problems• The Winfree model with heterogeneous phase-response curves: Analytical results• An improved upper bound for the grid Ramsey problem• A Reverse Sidorenko Inequality• Automatic brain tumor grading from MRI data using convolutional neural networks and quality assessment• Flag-approximability of convex bodies and volume growth of Hilbert geometries• Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation• Correlation Clustering Generalized• Stable Multi-Level Monotonic Eroders• Practical bounds on the error of Bayesian posterior approximations: A nonasymptotic approach• Flexible unit commitment of a network-constrained combined heat and power system• Convergence rate of distributed Dykstra’s algorithm with sets defined as level sets of convex functions• Information Diffusion Power of Political Party Twitter Accounts During Japan’s 2017 Election• A dual ascent algorithm for asynchronous distributed optimization with unreliable directed communications• Cylindric multipartitions and level-rank duality• Earning Maximization with Quality of Charging Service Guarantee for IoT Devices• Mostly Harmless Simulations? On the Internal Validity of Empirical Monte Carlo Studies• ComQA: A Community-sourced Dataset for Complex Factoid Question Answering with Paraphrase Clusters• Optimal control under uncertainty: Application to the issue of CAT bonds• alphastable: An R Package for Modelling Multivariate Stable and Mixture of Symmetric Stable Distributions• Perturbation Bounds for Monte Carlo within Metropolis via Restricted Approximations• Coordinating and Integrating Faceted Classification with Rich Semantic Modeling• Human-Machine Interface for Remote Training of Robot Tasks• Girth, minimum degree, independence, and broadcast independence• Some Characterizations and Properties of COM-Poisson Random Variables• Tangent: Automatic differentiation using source-code transformation for dynamically typed array programming• Combined convolutional and recurrent neural networks for hierarchical classification of images• Contextual Bandits with Cross-learning• Deterministic Conditions for the Absence and Existence of Arbitrage in Continuous Financial Markets• Spherical and geodesic growth rates of right-angled Coxeter and Artin groups are Perron numbers• Exact entanglement cost of quantum states and channels under PPT-preserving operations• A counterexample to the DeMarco-Kahn Upper Tail Conjecture• HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering• A Re-ranker Scheme for Integrating Large Scale NLU models• Structural and object detection for phosphene images• On the counterexamples to Borsuk’s conjecture by Kahn and Kalai• Quantum Hall Valley Nematics
Like this:
Like Loading…
Related