There’s no shortage of websites and repositories that aggregate various machine learning datasets and pre-trained models (Kaggle, UCI MLR, DeepDive, individual repos like gloVe, FastText, Quora, blogs, individual university pages…). The only problem is, they all use widely different formats, cover widely different use-cases and go out of service with worrying regularity.
For this reason, we decided to include free datasets and models relevant to unsupervised text analysis (Gensim’s sweet spot), directly in Gensim, using a stable data repository (Github) and a common data format and access API. Gensim has been around for nearly 10 years, and deserves its own stable, reliable set of resources.

In the spirit of the good old standards proliferation… (image: XKCD)
This is a graduating blog post by Chaitali Saini, one of our wonderful Incubator students.
API Design To make the life of our users easier, we had a look at how other popular packages (such as scikit-learn, NLTK or spaCy) deal with dataset access, packaging and upgrades.
Our design goals were:
- ease of use: users must be able to load up a pre-packaged dataset (text corpus or pretrained model) and use it in a single line of code.
- efficiency: accessing the datasets must be streamed and efficient, i.e. no unnecessary decompressing (disk or RAM)
- extendibility: users must be able to share their own domain-specific dataset or model, to be included in the Gensim repository.
All of this using open source tools and licenses, naturally.
Did we succeed? The rest of this post introduces this new functionality, so you be the judge.
Core API concepts Where are the corpora / models stored?
Globally, the datasets live in a new central dedicated Github repository, gensim-data. Its README contains a list of resources available right now (more in the making, domain-specific contributions welcome!).
Locally, on your machine after you download them, the datasets live inside the ~/gensim-data folder. The relevant files are retrieved from Github and re-assembled here if necessary (more on that below).
Github allows storing an unlimited number of files, acts as a good CDN, has (mostly) good world-wide availability (except some shenanigans by China), DOS protection. The only limitation is that all files must be smaller than 2GB, which is annoying because many NLP corpora hit that limit easily.
We solved that problem by splitting large files into several smaller files on storage (in Github), then re-assembling them transparently during the download (your disk).
Note that you don’t have to clone or install this gensim-data repository, it’s a technical detail you can simply ignore. Gensim knows the data location and when you call something like gensim.downloader.api.load(“text8�), Gensim will automatically locate and download the correct file.
What’s in a dataset?
In NLP, both corpora and models are typically a result of a longer pipeline, which includes things like crawling (a specific website or database), text filtering (removing boilerplate or document subsampling), preprocessing (text normalization, encoding, tokenization) etc.
These are all critical values to know, as a different choice of parameters leads to a different dataset – even if it’s just running the same pipeline code at a later date.
For this reason, we also store metadata about each dataset. This typically includes the original authors, related published paper(s) (where applicable), things like the vectorizer, dimensionality and so on. This is how you’d retrieve this metadata:
from CLI
$ python -m gensim.downloader -i dataset_name
from Python
print(api.info(‘text8’)) { u’description’: u’First 100,000,000 bytes of plain text from Wikipedia. Used for testing purposes; see wiki-english-* for proper full Wikipedia datasets.’, u’read_more’: [u’http://mattmahoney.net/dc/textdata.html’]} u’file_size’: 33182058, u’num_records’: 1701, u’record_format’: u’list of str (tokens)’, u’file_name’: u’text8.gz’, u’reader_code’: u’https://github.com/RaRe-Technologies/gensim-data/releases/download/text8/init.py’, u’license’: u’public domain’, u’parts’: 1, u’checksum’: u’68799af40b6bda07dfa47a32612e5364’, … }
What datasets are there?
A core concept of the new API is a dataset name, a unique string identifier of each dataset. You can get a list of all available dataset names:
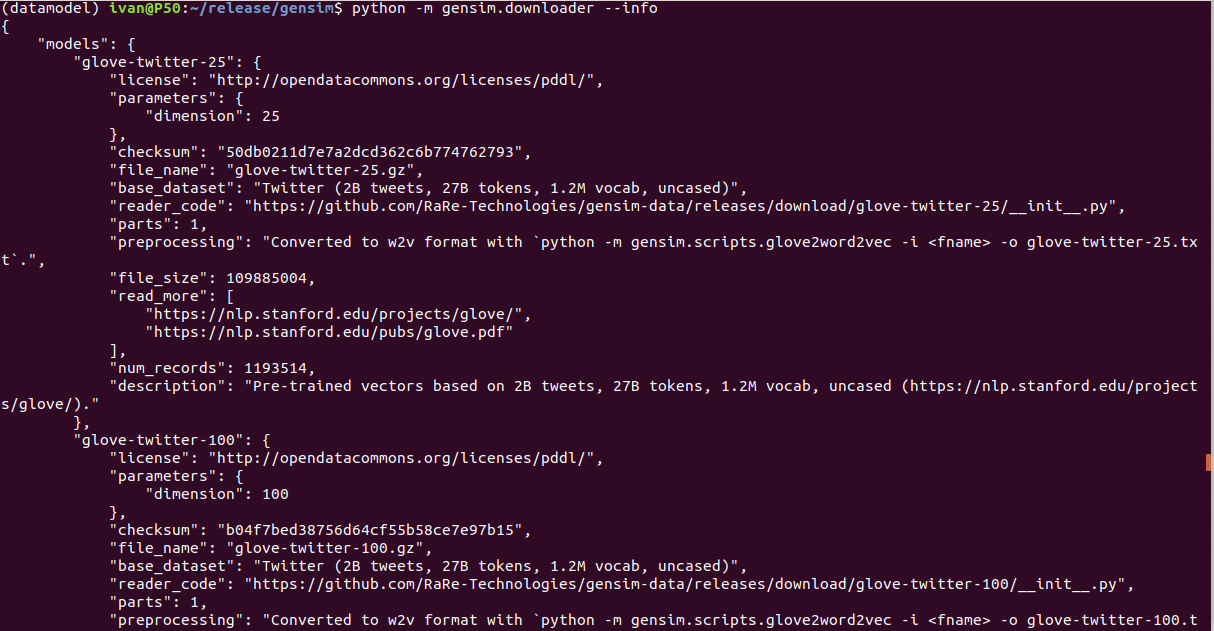
using the command line
$ python -m gensim.downloader –info
This is a graduating blog post by Chaitali Saini, one of our wonderful Incubator students.
Our design goals were:
- ease of use: users must be able to load up a pre-packaged dataset (text corpus or pretrained model) and use it in a single line of code.
- efficiency: accessing the datasets must be streamed and efficient, i.e. no unnecessary decompressing (disk or RAM)
- extendibility: users must be able to share their own domain-specific dataset or model, to be included in the Gensim repository.
Did we succeed? The rest of this post introduces this new functionality, so you be the judge.
Core API concepts
Locally, on your machine after you download them, the datasets live inside the ~/gensim-data folder. The relevant files are retrieved from Github and re-assembled here if necessary (more on that below).
We solved that problem by splitting large files into several smaller files on storage (in Github), then re-assembling them transparently during the download (your disk).
What’s in a dataset?
In NLP, both corpora and models are typically a result of a longer pipeline, which includes things like crawling (a specific website or database), text filtering (removing boilerplate or document subsampling), preprocessing (text normalization, encoding, tokenization) etc.
For this reason, we also store metadata about each dataset. This typically includes the original authors, related published paper(s) (where applicable), things like the vectorizer, dimensionality and so on. This is how you’d retrieve this metadata:
A core concept of the new API is a dataset name, a unique string identifier of each dataset. You can get a list of all available dataset names:
Output for python -m gensim.downloader --info
from Python
import gensim.downloader as api print(api.info())
Accessing a dataset
Finally, this is how you’d download a dataset locally and load it up, ready for use in Python:
load a corpus
text8_corpus = api.load(‘text8’)
load a pre-trained model; the API is the same
glove_model = api.load(‘glove-twitter-200’)
The commands above will both download the dataset (if not already present) and load it as a Python object, ready for use:
print(next(iter(text8_corpus))[:10]) # corpora are streamed iterables [u’anarchism’, u’originated’, u’as’, u’a’, u’term’, u’of’, u’abuse’, u’first’, u’used’, u’against’] print(glove_model.most_similar(“science”, topn=3)) [(‘physics’, 0.7786292433738708), (‘biology’, 0.754408061504364), (‘math’, 0.7445053458213806)]
Note that the loaded corpora are not loaded into RAM as whole, but rather streamed from disk, document-by-document as iterables, which is Gensim’s native format for scalability reasons. (Confused about Python’s iterators, iterables and data streaming? See our tutorial blog post Data streaming in Python: generators, iterators, iterables.)
If you want to download a corpus or model without loading it as a Python object, use the optional return_path parameter instead:
text8corpus = api.load(‘text8’, return_path=True) print(text8corpus) # now it’s just a string ‘/home/username/gensim-data/text8/text8.gz’
End-to-end example
We’ll end with one end-to-end example. By now, it should be clear what’s happening and how to integrate the prepackaged resources into your own machine learning pipeline:
import gensim.downloader as api from gensim.models import Word2Vec print(api.info(‘text8’)) {u’source’: u’http://mattmahoney.net/dc/textdata’, u’checksum’: u’68799af40b6bda07dfa47a32612e5364’, u’parts’: 1, u’description’: u’Cleaned small sample from wikipedia’, u’file_name’: u’text8.gz’} text8_corpus = api.load(‘text8’) w2v_model = Word2Vec(text8_corpus) # train word2vec model on text8 corpus print(w2v_model.similarity(‘tree’, ‘leaf’)) # sanity check 0.702394119049
We hope you enjoy this new functionality. Let us know in the comments below or on twitter what you think!
FAQ
Q1: When does this functionality become available?
A: In the next Gensim release: gensim>=3.2.0 (planned for December 2017).
EDIT:already released!
This is an initial release and we have several domain-specific datasets in the pipeline (patents, medical, HR).
Q2: How to add a new corpus / model? A: We welcome datasets in any language, and especially domain domain-specific dataset (legal, HR, engineering, medical…). The only restriction is that the dataset must fit within Gensim’s mission: unsupervised text analysis for humans. And obviously have a license that allows (non-commercial) redistribution.
To contribute a new dataset, look at the gensim-data README. Compress your data to a single .gz file, share it with us through any file-sharing service. Then create a new issue with a detailed description with how the dataset was created, any related links/papers, parameters or settings used. Important: include a motivating use-case and a concrete Python example for how to load and use the dataset! A dataset is useless if people don’t know how to work with it.
Q3: How do you update the existing datasets? A: Short answer: never. The published datasets are immutable, published in their original form forever, no changes. We think this is the best way to ensure reproducibility.
At the same time, no one prevents you from adding new, updated models under a new name, as a new dataset. For example, we published the “wiki-english-20171001� corpus and once we release a new version, we’ll make a new dataset with a name like “wiki-english-20171201� (note the difference in the timestamp). But previous dataset versions will remain always available, under their original name.
Q4: What’s the dataset naming policy? A: Reasonably short, all lowercase, no spaces, hyphens instead of underscores. Example: “glove-twitter-25� as a model; “wiki-english-20171001� for a dataset. Do not stress about the name, we’ll choose something suitable or make adjustments.
Q5: How do I delete all Gensim datasets from my computer?
A: Remove the ~/gensim-data folder, all data is stored in there.
Q6: I don’t have enough disk space under ~/gensim-data for new datasets, what should I do?
A: Even though Gensim can stream from remote storages (S3, HDFS) using smart_open, a locally downloaded copy of the dataset is required here, for performance reasons. If you have another disk with more space, we recommend you create a symbolic link (symlink) and point ~/gensim-data to a location on this larger disk.
Q7: Are you planning to expand the API? A: Probably. Your suggestion and feedback welcome. One thing we already know we’ll implement in future versions is dataset tags, for simpler dataset filtering and navigation (tags for language, domain, purpose…).