I’ve been experimenting with OpenAI gym recently, and one of the simplest environments is CartPole. The problem consists of balancing a pole connected with one joint on top of a moving cart. The only actions are to add a force of -1 or +1 to the cart, pushing it left or right.
example of balancing the pole in CartPole
In this post, I will be going over some of the methods described in the CartPole request for research, including implementations and some intuition behind how they work.
In CartPole’s environment, there are four observations at any given state, representing information such as the angle of the pole and the position of the cart.
Using these observations, the agent needs to decide on one of two possible actions: move the cart left or right.
A simple way to map these observations to an action choice is a linear combination. We define a vector of weights, each weight corresponding to one of the observations. Start off by initializing them randomly between [-1, 1].
1 | |
How is the weight vector used? Each weight is multiplied by its respective observation, and the products are summed up. This is equivalent to performing an inner product (matrix multiplication) of the two vectors. If the total is less than 0, we move left. Otherwise, we move right.
1 | |
Now we’ve got a basic model for choosing actions based on observations. How do we modify these weights to keep the pole standing up?
First, we need some concept of how well we’re doing. For every timestep we keep the pole straight, we get +1 reward. Therefore, to estimate how good a given set of weights is, we can just run an episode until the pole drops and see how much reward we got.
1 | |
We now have a basic model, and can run episodes to test how well it performs. The problem is now much simpler: how can we select these weights/parameters, to receive the highest amount of average reward?
Random Search
One fairly straightforward strategy is to keep trying random weights, and pick the one that performs the best.
1 | |
Since the CartPole environment is relatively simple, with only 4 observations, this basic method works surprisingly well.
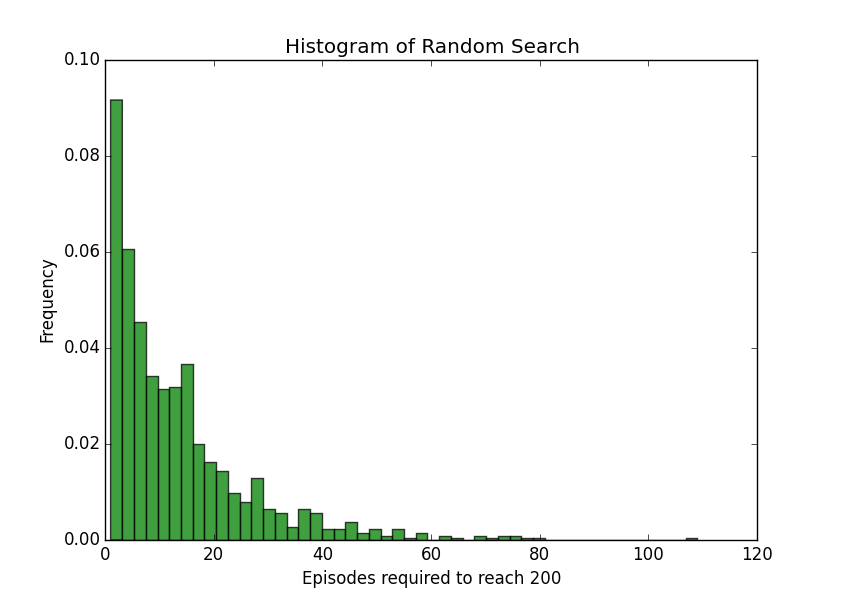
I ran the random search method 1,000 times, keeping track of how many episodes it took until the agent kept the pole up for 200 timesteps. On average, it took 13.53 episodes.
Hill-Climbing
Another method of choosing weights is the hill-climbing algorithm. We start with some randomly chosen initial weights. Every episode, add some noise to the weights, and keep the new weights if the agent improves.
1 | |
The idea here is to gradually improve the weights, rather than keep jumping around and hopefully finding some combination that works. If noise_scaling is high enough in comparison to the current weights, this algorithm is essentially the same as random search.
As usual, this algorithm has its pros and cons. If the range of weights that successfully solve the problem is small, hill climbing can iteratively move closer and closer while random search may take a long time jumping around until it finds it.
However, if the weights are initialized badly, adding noise may have no effect on how well the agent performs, causing it to get stuck.
To visualize this, let’s pretend we only had one observation and one weight. Performing random search might look something like this. 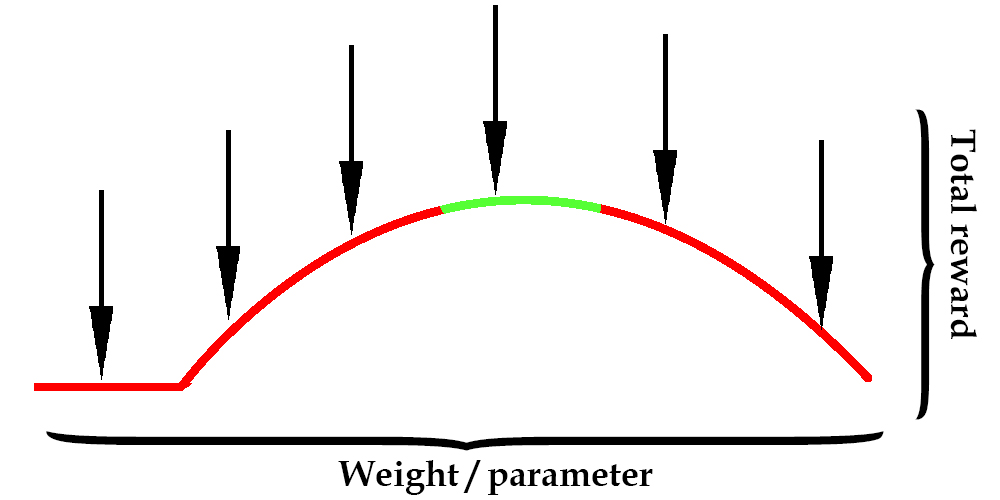
In the image above, the x-axis represents the value of the weight from -1 to 1. The curve represents how much reward the agent gets for using that weight, and the green represents when the reward was high enough to solve the environment (balance for 200 timesteps).
An arrow represents a random guess as to where the optimal weight might be. With enough guesses, the agent will eventually try a weight in the green zone and be successful.
How does this change with hill climbing? 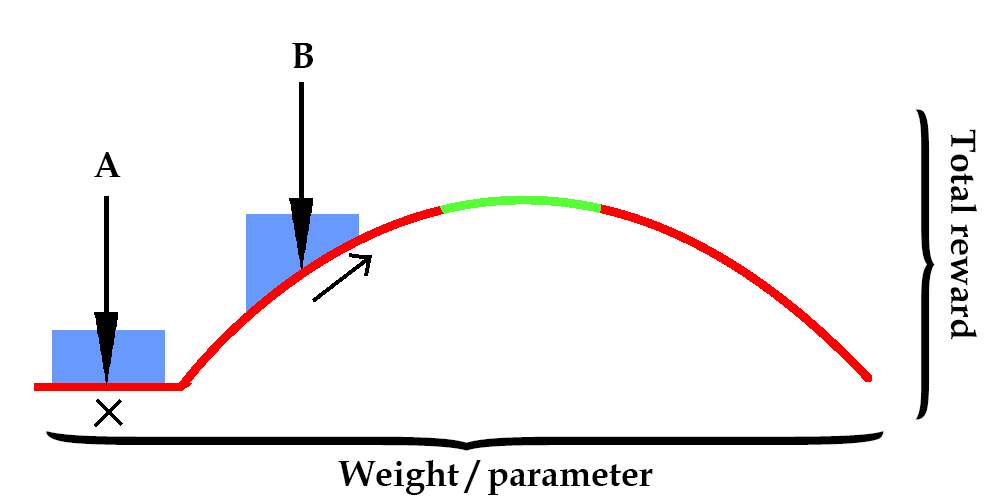
Here, an arrow represents the value that weights are initialized at. The blue region is noise that is added at every iteration.
If the weight starts at arrow B, then hill-climbing can try other weights near arrow B until it finds one that improves the reward. This can continue until the weight is in the green zone.
However, arrow A has a problem. If the weight is initialized at a location where changing it slightly gives no improvement at all, the hill climbing is stuck and won’t find a good answer.
It turns out that in CartPole, there are many initializations that get stuck. 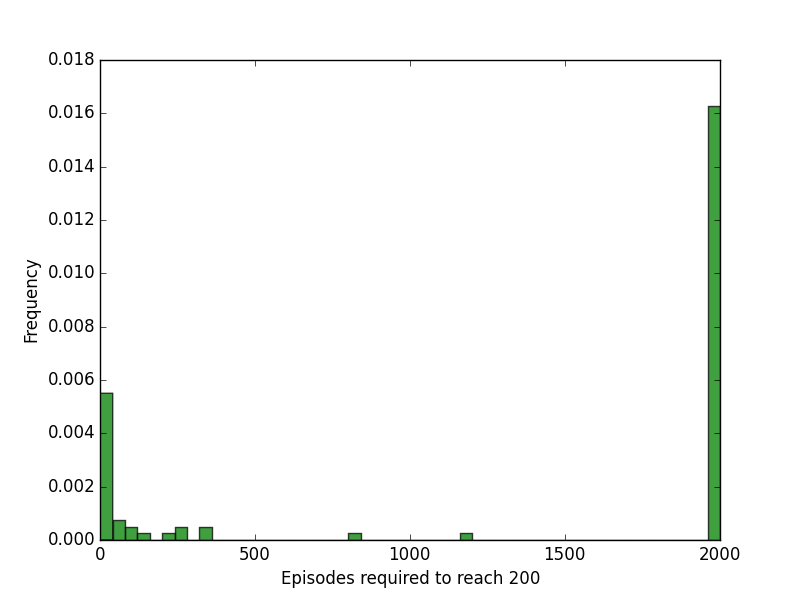
More than half of the trials got stuck and couldn’t improve (the bar on the right). However, of the trials that reach a solution, it took an average of 7.43 episodes to do so, less than random search.
A possible fix to this problem would be to slightly increase the noise_factor every iteration that the agent does not improve, and eventually reach a set of weights that improves the reward.
Another change that may improve accuracy is to replace
1 | |
with
1 | |
Instead of only running one episode to measure how good a set of weights is, we run it multiple times and sum up the rewards. Although it might take longer to evaluate, this decreases variance and results in a more accurate measurement of whether one set of weights performs better.
Policy Gradient
The next method is a little more complicated than needed to solve the CartPole environment. When possible, simple methods such as random search and hill climbing are better to start with. However, it’s a good concept to learn and performs better in environments with lots of states or actions.
In order to implement a policy gradient, we need a policy that can change little by little. In practice, this means switching from an absolute limit (move left if the total is < 0, otherwise move right) to probabilities. This changes our agent from a deterministic to a stochastic (random) policy.
Instead of only having one linear combination, we have two: one for each possible action. Passing these two values through a softmax function gives the probabilities of taking the respective actions, given a set of observations. This also generalizes to multiple actions, unlike the threshold we were using before.
Since we’re going be computing gradients, it’s time to bust out Tensorflow.
1 | |
We also need a way to change the policy, increasing the probability of taking a certain action given a certain state.
Here’s a crude implementation of an optimizer that allows us to incrementally update our policy. The vector actions is a one-hot vector, with a one at the action we want to increase the probability of.
1 | |
So we know how to update our policy to prefer certain actions. If we knew exactly what the perfect to move in every state was, we could just continously perform supervised learning and the problem would be solved. Unfortunately, we don’t have some magic oracle that knows all the right moves.
We want to know how good it is to take some action from some state. Thankfully, we do have some measure of success that we can make decisions based on: the return, or total reward from that state onwards.
We’re trying to determine the best action for a state, so the first thing we need is a baseline to compare from. We a define some value for each state, that contains the average return starting from that state. In this example, we’ll use a 1 hidden layer neural network.
1 | |
In order to train this network, we first need to run some episodes to gather data. This is pretty similar to the loop in random-search or hill climbing, except we want to record transitions for each step, containing what action we took from what state, and what reward we got for it.
1 | |
Next, we compute the return of each transition, and update the neural network to reflect this. We don’t care about the specific action we took from each state, only what the average return for the state over all actions is.
1 | |
If we let this run for a couple hundred episodes, the value of each state is represented pretty accurately. The decrease factor puts more of an emphasis on short-term reward rather than long-term reward. This introduces a little bias but can reduce variance by a lot, especially in the case of outliers, such as a lucky episode that lasted for 100 timeframes from a state that normally lasted only 30.
How can we use the newly found values of states in order to update our policy to reflect it? Obviously, we want to favor actions that return a total reward greater than the average of that state. We call this error between the actual return and the average an advantage. As it turns out, we can just plug in the advantage as a scale, and update our policy accordingly.
1 | |
This requires a slight change in our policy update: we add in a scaling factor for a given update. If a certain action results in a return of 150, while the state average is 60, we want to increase its probability more than an action with a return of 70 and a state average of 65. Furthermore, if the return for an action is 30 while the state is average is 40, we have a negative advantage, and instead decrease the probability.
1 | |
How well does our policy gradient perform on CartPole?
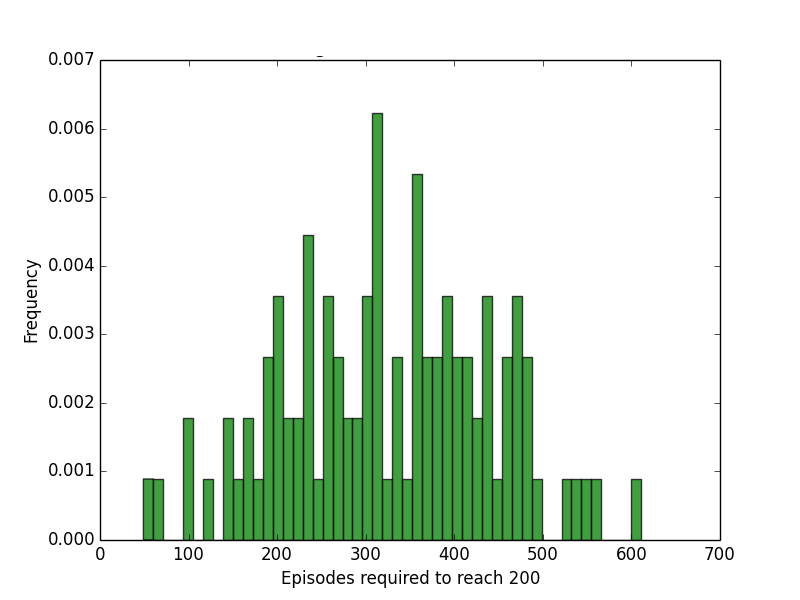
Turns out, it’s not very fast. Compared to random search and hill climbing, policy gradient takes much longer to solve CartPole.
This is partly due to having to learn a value function first, before the agent can make any solid assumptions as to which actions are better. While the first two methods can start improving right off the bat, the policy gradient needs to collect data on how to improve first.
However, this ensures that the updates are always making some form of improvement. In environments with much higher dimensional state spaces, the previous methods get much less efficient, as the probability of improving when adjusting randomly is small. A policy gradient ensures the agent is always heading toward some kind of optimum.
Since we always follow the gradient, our weights will always be changing and we doesn’t get stuck in bad initializations such as in hill climbing. It also can improve on an already good solution even further, which random search cannot do.
In the end, simple methods are almost always better when dealing with simple problems. For more complicated environments, a policy gradient allows our agent to perform more consistent updates and gradually improve.
The code for these methods is available on my Github