One of the biggest mysteries for beginners in neural networks is figuring out when to use which optimization method. This post focuses on describing popular first-order methods: SGD, Momentum, Nesterov Momentum, Adagrad, RMSProp and Adam.
Second order methods are not included largely because inverting the Hessian takes too much computation power, and most deep learning researchers find it impractical to use second order methods.
Stochastic Gradient Descent
Using stochastic gradient descent, we simply follow the gradient. The gradient is controlled by a learning rate, which typically tends to be a linearly decreasing number.
The problem with SGD is that chosing a proper learning rate is difficult and it’s easy to get trapped in a saddle point when optimizing a highly non-convex loss function.
Momentum
Stochastic Gradient Descent can oscillate and have trouble converging. Momentum tries to improve on SGD by dampening the oscillation and emphasizing the optimal direction.
If we call the update , the SGD equation becomes . Momentum combines the past update along with the current update, in order to stablize the updates.
The value of is usually close to 1 e.g. 0.9, 0.95.
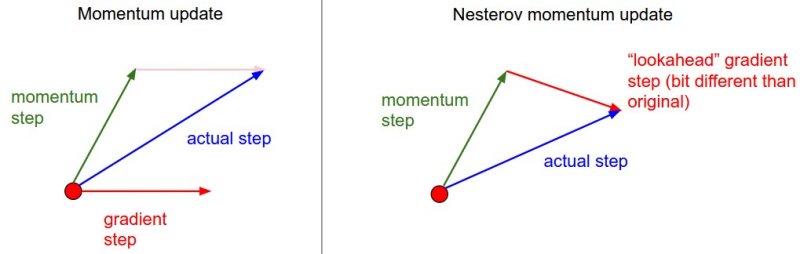
Nesterov Momentum
Momentum is an improvement on SGD because is combined with . However, because is very dependent on , momentum by itself is slow to adapt and change directions.
Nesterov momentum builds on raw momentum. Instead of calculating via , Nesterov tries to calculate . But how can we calculate the gradient of the parameters in the future? We can’t. However, we can approximate the future parameter by assuming that , which is largely true.
Adagrad
Adagrad, RMSProp and Adam take a different approach on how to improve SGD. SGD, Momentum and Nesterov Momentum all have a single learning rate for all parameters. The following 3 methods instead adaptively tune the learning rates for each parameter.
Adagrad normalizes the update for each parameter. Parameters that had large gradients will have smaller updates; small or infrequent gradients will be bumped to take larger steps.
Adagrad will eventually be unable to make any updates, because the size of cache becomes infinity.
RMSProp
RMSProp improves on adagrad by decaying the size of the cache. The cache is “leaky” and prevents the updates from becoming 0. Hinton recommends setting to 0.99 and to 0.01.
Adam
Adam is a variation of RMSProp.
When to use what?
There is no concensus which optimization methods are the best. In my experience, adagrad based methods are a lot safer but slower than momentum based methods. I usually stick to RMSProp for the first cut of the model and test other methods afterwards.