This week I’m tweeting from the @shefunilife account, an account that is switched once a week between staff and students at the University of Sheffield.
RSiteCatalyst Version 1.4.8 Release Notes
For being in RSiteCatalyst retirement, I’m ending up working on more functionality lately ¯(ツ)/¯. Here are the changes for RSiteCatalyst 1.4.8, which should be available on CRAN shortly:
Solar Eclipses
 |
Relative to the Earth, the Sun is pretty big. However, it’s also 93 million miles away. The product of these two facts is that it subtends an area of the sky of approximately 60 µsr (60 Micro-Steradians). This is about the same size as your thumbnail, when you hold your hand out at arm’s length.The Steradian is a normalized measurement for solid angles. It’s the solid angle (3D) equivalent of radians, which are dimensionless measurements of 2D angles relative to a circle.A surface patch of area r2 on a sphere of radius r, subtends 1 Steradian. There are 4π Steradians in sphere. The 60 µsr for the Sun, is a measure of the area the ‘disc’ of the Sun takes up in the sphere of the celestial sky. | 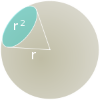 |
Generating Large Images from Latent Vectors
April 1, 2016
Representational Power of Deeper Layers
The hidden layers in a neural network can be seen as different representations of the input. Do deeper layers learn “better” representations? In a network trained to solve a classification problem, this would mean that deeper layers provide better features than earlier layers. The natural hypothesis is that this is indeed the case. In this post, I test this hypothesis on an network with three hidden layers trained to classify the MNIST dataset. It is shown that deeper layers do in fact produce better representations of the input.
Implementing Batch Normalization in Tensorflow
Batch normalization, as described in the March 2015 paper (the BN2015 paper) by Sergey Ioffe and Christian Szegedy, is a simple and effective way to improve the performance of a neural network. In the BN2015 paper, Ioffe and Szegedy show that batch normalization enables the use of higher learning rates, acts as a regularizer and can speed up training by 14 times. In this post, I show how to implement batch normalization in Tensorflow.
Becoming a Data Scientist Podcast Episode 08: Sebastian Raschka
Renee interviews computational biologist, author, data scientist, and Michigan State PhD candidate Sebastian Raschka about how he became a data scientist, his current research, and about his book Python Machine Learning. In the audio interview, Sebastian also joins us to discuss k-fold cross-validation for our model evaluation Data Science Learning Club activity.
Feather: A Fast On-Disk Format for Data Frames for R and Python, powered by Apache Arrow
This past January, we (Hadley and Wes) met and discussed some of the systems challenges facing the Python and R open source communities. In particular, we wanted to explore opportunities to collaborate on tools for improving interoperability between Python, R, and external compute and storage systems.
Crowdsourcing Fantasy Baseball Leagues
With MLB Opening Day just over a week away, it’s time for another season of fantasy baseball. If your leagues are anything like mine, that means chains of 200+ emails hashing out every detail of league rules and setup. When are we drafting? Should we change our keeper rules? Wait, what are the keeper rules? What about changing scoring or roster settings? This goes on and on, and we usually end up changing nothing from the previous year. It’s ridiculous, but given that leagues can have a wide variety of configurations, it makes sense that the managers will almost never immediately align on an acceptable setup.
Akka Stream
Recent advances in hardware and software have enabled the capture and the generation of different measurements of data in a wide range of fields. These measurements are generated continuously and in a very high fluctuating data rates. Examples include sensor networks, web logs, financial market, and computer network traffic. The storage, querying and processing of such data sets are highly computationally challenging tasks. Thus, there is an increasing interest on streaming architecture with some interesting outcome like Storm, Spark Streaming and Flink.