Last week I blogged about some different ways of dealing with data in a cross tab that has been suppressed as a means of disclosure control, when the count in a cell is less than six. I tried simple replacement of those cells with “3”, two different multiple imputation methods, and left-censored Poisson regression based on survival methods. I tested those methods on a single two-way simulated cross-tab of the counts of three different types of animals in four different regions, with two suppressed cells.
Anticipating the next move in data science – my interview with Thomson Reuters
Congress Over Time
Since the U.S. midterm elections I’ve been playing around with some Congressional Quarterly data about the composition of the House and Senate since 1945. Unfortunately I’m not allowed to share the data, but here are two or three things I had to do with it that you might find useful.
“Using numbers to replace judgment”
Julian Marewski and Lutz Bornmann write:
Benford’s Law for Fraud Detection with an Application to all Brazilian Presidential Elections from 2002 to 2018
The intuition
Let us begin with a brief explanation about Benford’s law and why should it work as a fraud detector method. Given a set of numbers, the first thing we need to do is to extract the first digit of each number. For example, for (121,245,12,55) the first digits will be (1,2,1,5). Perhaps our intuition would say that for a large set of numbers, each first digit, from 1 to 9, would appear in equal proportion, that is 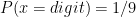
Convert Data Frame to Dictionary List in R
In R, there are a couple ways to convert the column-oriented data frame to a row-oriented dictionary list or alike, e.g. a list of lists.
Document worth reading: “Multi-Agent Reinforcement Learning: A Report on Challenges and Approaches”
Reinforcement Learning (RL) is a learning paradigm concerned with learning to control a system so as to maximize an objective over the long term. This approach to learning has received immense interest in recent times and success manifests itself in the form of human-level performance on games like \textit{Go}. While RL is emerging as a practical component in real-life systems, most successes have been in Single Agent domains. This report will instead specifically focus on challenges that are unique to Multi-Agent Systems interacting in mixed cooperative and competitive environments. The report concludes with advances in the paradigm of training Multi-Agent Systems called \textit{Decentralized Actor, Centralized Critic}, based on an extension of MDPs called \textit{Decentralized Partially Observable MDP}s, which has seen a renewed interest lately. Multi-Agent Reinforcement Learning: A Report on Challenges and Approaches
Tis the Season to Check your SSL/TLS Cipher List Thrice (RCurl/curl/openssl)
The libcurl library (the foundational library behind the RCurl and curl packages) has switched to using OpenSSL’s default ciphers since version 7.56.0 (October 4 2017). If you’re a regular updater of curl/httr you should be fairly current with these cipher suites, but if you’re not a keen updater or use RCurl for your web-content tasks, you are likely not working with a recent cipher list and may start running into trouble as the internet self-proclaimed web guardians keep their wild abandon push towards “HTTPS Everywhere�.
If you did not already know
Halide  Halide is a computer programming language designed for writing digital image processing code that takes advantage of memory locality, vectorized computation and multi-core CPUs and GPUs. Halide is implemented as an internal domain-specific language (DSL) in C++. The main innovation Halide brings is the separation of the algorithm being implemented from its execution schedule, i.e. code specifying the loop nesting, parallelization, loop unrolling and vector instruction. These two are usually interleaved together and experimenting with changing the schedule requires the programmer to rewrite large portions of the algorithm with every change. With Halide, changing the schedule does not require any changes to the algorithm and this allows the programmer to experiment with scheduling and finding the most efficient one.
Halide is a computer programming language designed for writing digital image processing code that takes advantage of memory locality, vectorized computation and multi-core CPUs and GPUs. Halide is implemented as an internal domain-specific language (DSL) in C++. The main innovation Halide brings is the separation of the algorithm being implemented from its execution schedule, i.e. code specifying the loop nesting, parallelization, loop unrolling and vector instruction. These two are usually interleaved together and experimenting with changing the schedule requires the programmer to rewrite large portions of the algorithm with every change. With Halide, changing the schedule does not require any changes to the algorithm and this allows the programmer to experiment with scheduling and finding the most efficient one. DNN Dataflow Choice Is Overrated …
DNN Dataflow Choice Is Overrated …
If you did not already know
Information Extraction Technology
With rise of digital age, there is an explosion of information in the form of news, articles, social media, and so on. Much of this data lies in unstructured form and manually managing and effectively making use of it is tedious, boring and labor intensive. This explosion of information and need for more sophisticated and efficient information handling tools gives rise to Information Extraction(IE) and Information Retrieval(IR) technology. Information Extraction systems takes natural language text as input and produces structured information specified by certain criteria, that is relevant to a particular application. Various sub-tasks of IE such as Named Entity Recognition, Coreference Resolution, Named Entity Linking, Relation Extraction, Knowledge Base reasoning forms the building blocks of various high end Natural Language Processing (NLP) tasks such as Machine Translation, Question-Answering System, Natural Language Understanding, Text Summarization and Digital Assistants like Siri, Cortana and Google Now. This paper introduces Information Extraction technology, its various sub-tasks, highlights state-of-the-art research in various IE subtasks, current challenges and future research directions. …