Efficient Convolutional Neural Network Training with Direct Feedback Alignment
There were many algorithms to substitute the back-propagation (BP) in the deep neural network (DNN) training. However, they could not become popular because their training accuracy and the computational efficiency were worse than BP. One of them was direct feedback alignment (DFA), but it showed low training performance especially for the convolutional neural network (CNN). In this paper, we overcome the limitation of the DFA algorithm by combining with the conventional BP during the CNN training. To improve the training stability, we also suggest the feedback weight initialization method by analyzing the patterns of the fixed random matrices in the DFA. Finally, we propose the new training algorithm, binary direct feedback alignment (BDFA) to minimize the computational cost while maintaining the training accuracy compared with the DFA. In our experiments, we use the CIFAR-10 and CIFAR-100 dataset to simulate the CNN learning from the scratch and apply the BDFA to the online learning based object tracking application to examine the training in the small dataset environment. Our proposed algorithms show better performance than conventional BP in both two different training tasks especially when the dataset is small.
Geometrization of deep networks for the interpretability of deep learning systems
How to understand deep learning systems remains an open problem. In this paper we propose that the answer may lie in the geometrization of deep networks. Geometrization is a bridge to connect physics, geometry, deep network and quantum computation and this may result in a new scheme to reveal the rule of the physical world. By comparing the geometry of image matching and deep networks, we show that geometrization of deep networks can be used to understand existing deep learning systems and it may also help to solve the interpretability problem of deep learning systems.
Towards Self-constructive Artificial Intelligence: Algorithmic basis (Part I)

Large-Scale Markov Decision Problems via the Linear Programming Dual
We consider the problem of controlling a fully specified Markov decision process (MDP), also known as the planning problem, when the state space is very large and calculating the optimal policy is intractable. Instead, we pursue the more modest goal of optimizing over some small family of policies. Specifically, we show that the family of policies associated with a low-dimensional approximation of occupancy measures yields a tractable optimization. Moreover, we propose an efficient algorithm, scaling with the size of the subspace but not the state space, that is able to find a policy with low excess loss relative to the best policy in this class. To the best of our knowledge, such results did not exist in the literature previously. We bound excess loss in the average cost and discounted cost cases, which are treated separately. Preliminary experiments show the effectiveness of the proposed algorithms in a queueing application.
Recurrent Control Nets for Deep Reinforcement Learning
Central Pattern Generators (CPGs) are biological neural circuits capable of producing coordinated rhythmic outputs in the absence of rhythmic input. As a result, they are responsible for most rhythmic motion in living organisms. This rhythmic control is broadly applicable to fields such as locomotive robotics and medical devices. In this paper, we explore the possibility of creating a self-sustaining CPG network for reinforcement learning that learns rhythmic motion more efficiently and across more general environments than the current multilayer perceptron (MLP) baseline models. Recent work introduces the Structured Control Net (SCN), which maintains linear and nonlinear modules for local and global control, respectively. Here, we show that time-sequence architectures such as Recurrent Neural Networks (RNNs) model CPGs effectively. Combining previous work with RNNs and SCNs, we introduce the Recurrent Control Net (RCN), which adds a linear component to the, RCNs match and exceed the performance of baseline MLPs and SCNs across all environment tasks. Our findings confirm existing intuitions for RNNs on reinforcement learning tasks, and demonstrate promise of SCN-like structures in reinforcement learning.
Analogy-Based Preference Learning with Kernels
Building on a specific formalization of analogical relationships of the form ‘A relates to B as C relates to D’, we establish a connection between two important subfields of artificial intelligence, namely analogical reasoning and kernel-based machine learning. More specifically, we show that so-called analogical proportions are closely connected to kernel functions on pairs of objects. Based on this result, we introduce the analogy kernel, which can be seen as a measure of how strongly four objects are in analogical relationship. As an application, we consider the problem of object ranking in the realm of preference learning, for which we develop a new method based on support vector machines trained with the analogy kernel. Our first experimental results for data sets from different domains (sports, education, tourism, etc.) are promising and suggest that our approach is competitive to state-of-the-art algorithms in terms of predictive accuracy.
Bayesian Inference for Persistent Homology
Persistence diagrams offer a way to summarize topological and geometric properties latent in datasets. While several methods have been developed that utilize persistence diagrams in statistical inference, a full Bayesian treatment remains absent. This paper, relying on the theory of point processes, lays the foundation for Bayesian inference with persistence diagrams. We model persistence diagrams as Poisson point processes with prior intensities and compute posterior intensities by adopting techniques from the theory of marked point processes. We then propose a family of conjugate prior intensities via Gaussian mixtures and proceed with a classification application in materials science using Bayes factors.
A New Perspective on Machine Learning: How to do Perfect Supervised Learning
In this work, we introduce the concept of bandlimiting into the theory of machine learning because all physical processes are bandlimited by nature, including real-world machine learning tasks. After the bandlimiting constraint is taken into account, our theoretical analysis has shown that all practical machine learning tasks are asymptotically solvable in a perfect sense. Furthermore, the key towards this solvability almost solely relies on two factors: i) a sufficiently large amount of training samples beyond a threshold determined by a difficulty measurement of the underlying task; ii) a sufficiently complex model that is properly bandlimited. Moreover, for unimodal data distributions, we have derived a new error bound for perfect learning, which can quantify the difficulty of learning. This case-specific bound is much tighter than the uniform bounds in conventional learning theory.
DPPNet: Approximating Determinantal Point Processes with Deep Networks
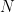
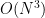

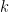
Multi-Source Transfer Learning for Non-Stationary Environments
In data stream mining, predictive models typically suffer drops in predictive performance due to concept drift. As enough data representing the new concept must be collected for the new concept to be well learnt, the predictive performance of existing models usually takes some time to recover from concept drift. To speed up recovery from concept drift and improve predictive performance in data stream mining, this work proposes a novel approach called Multi-sourcE onLine TrAnsfer learning for Non-statIonary Environments (Melanie). Melanie is the first approach able to transfer knowledge between multiple data streaming sources in non-stationary environments. It creates several sub-classifiers to learn different aspects from different source and target concepts over time. The sub-classifiers that match the current target concept well are identified, and used to compose an ensemble for predicting examples from the target concept. We evaluate Melanie on several synthetic data streams containing different types of concept drift and on real world data streams. The results indicate that Melanie can deal with a variety drifts and improve predictive performance over existing data stream learning algorithms by making use of multiple sources.
Optimal Differentially Private ADMM for Distributed Machine Learning


K-Core Minimization: A Game Theoretic Approach
Tree Tensor Networks for Generative Modeling
Matrix product states (MPS), a tensor network designed for one-dimensional quantum systems, has been recently proposed for generative modeling of natural data (such as images) in terms of `Born machine’. However, the exponential decay of correlation in MPS restricts its representation power heavily for modeling complex data such as natural images. In this work, we push forward the effort of applying tensor networks to machine learning by employing the Tree Tensor Network (TTN) which exhibits balanced performance in expressibility and efficient training and sampling. We design the tree tensor network to utilize the 2-dimensional prior of the natural images and develop sweeping learning and sampling algorithms which can be efficiently implemented utilizing Graphical Processing Units (GPU). We apply our model to random binary patterns and the binary MNIST datasets of handwritten digits. We show that TTN is superior to MPS for generative modeling in keeping correlation of pixels in natural images, as well as giving better log-likelihood scores in standard datasets of handwritten digits. We also compare its performance with state-of-the-art generative models such as the Variational AutoEncoders, Restricted Boltzmann machines, and PixelCNN. Finally, we discuss the future development of Tensor Network States in machine learning problems.
Uncertainty-Based Out-of-Distribution Detection in Deep Reinforcement Learning
We consider the problem of detecting out-of-distribution (OOD) samples in deep reinforcement learning. In a value based reinforcement learning setting, we propose to use uncertainty estimation techniques directly on the agent’s value estimating neural network to detect OOD samples. The focus of our work lies in analyzing the suitability of approximate Bayesian inference methods and related ensembling techniques that generate uncertainty estimates. Although prior work has shown that dropout-based variational inference techniques and bootstrap-based approaches can be used to model epistemic uncertainty, the suitability for detecting OOD samples in deep reinforcement learning remains an open question. Our results show that uncertainty estimation can be used to differentiate in- from out-of-distribution samples. Over the complete training process of the reinforcement learning agents, bootstrap-based approaches tend to produce more reliable epistemic uncertainty estimates, when compared to dropout-based approaches.
Deep Neural Network Approximation Theory
Deep neural networks have become state-of-the-art technology for a wide range of practical machine learning tasks such as image classification, handwritten digit recognition, speech recognition, or game intelligence. This paper develops the fundamental limits of learning in deep neural networks by characterizing what is possible if no constraints on the learning algorithm and the amount of training data are imposed. Concretely, we consider information-theoretically optimal approximation through deep neural networks with the guiding theme being a relation between the complexity of the function (class) to be approximated and the complexity of the approximating network in terms of connectivity and memory requirements for storing the network topology and the associated quantized weights. The theory we develop educes remarkable universality properties of deep networks. Specifically, deep networks are optimal approximants for vastly different function classes such as affine systems and Gabor systems. This universality is afforded by a concurrent invariance property of deep networks to time-shifts, scalings, and frequency-shifts. In addition, deep networks provide exponential approximation accuracy i.e., the approximation error decays exponentially in the number of non-zero weights in the network of vastly different functions such as the squaring operation, multiplication, polynomials, sinusoidal functions, general smooth functions, and even one-dimensional oscillatory textures and fractal functions such as the Weierstrass function, both of which do not have any known methods achieving exponential approximation accuracy. In summary, deep neural networks provide information-theoretically optimal approximation of a very wide range of functions and function classes used in mathematical signal processing.
Multi-turn Inference Matching Network for Natural Language Inference
Natural Language Inference (NLI) is a fundamental and challenging task in Natural Language Processing (NLP). Most existing methods only apply one-pass inference process on a mixed matching feature, which is a concatenation of different matching features between a premise and a hypothesis. In this paper, we propose a new model called Multi-turn Inference Matching Network (MIMN) to perform multi-turn inference on different matching features. In each turn, the model focuses on one particular matching feature instead of the mixed matching feature. To enhance the interaction between different matching features, a memory component is employed to store the history inference information. The inference of each turn is performed on the current matching feature and the memory. We conduct experiments on three different NLI datasets. The experimental results show that our model outperforms or achieves the state-of-the-art performance on all the three datasets.
Interpretable BoW Networks for Adversarial Example Detection
The standard approach to providing interpretability to deep convolutional neural networks (CNNs) consists of visualizing either their feature maps, or the image regions that contribute the most to the prediction. In this paper, we introduce an alternative strategy to interpret the results of a CNN. To this end, we leverage a Bag of visual Word representation within the network and associate a visual and semantic meaning to the corresponding codebook elements via the use of a generative adversarial network. The reason behind the prediction for a new sample can then be interpreted by looking at the visual representation of the most highly activated codeword. We then propose to exploit our interpretable BoW networks for adversarial example detection. To this end, we build upon the intuition that, while adversarial samples look very similar to real images, to produce incorrect predictions, they should activate codewords with a significantly different visual representation. We therefore cast the adversarial example detection problem as that of comparing the input image with the most highly activated visual codeword. As evidenced by our experiments, this allows us to outperform the state-of-the-art adversarial example detection methods on standard benchmarks, independently of the attack strategy.
CROSSBOW: Scaling Deep Learning with Small Batch Sizes on Multi-GPU Servers
Deep learning models are trained on servers with many GPUs, and training must scale with the number of GPUs. Systems such as TensorFlow and Caffe2 train models with parallel synchronous stochastic gradient descent: they process a batch of training data at a time, partitioned across GPUs, and average the resulting partial gradients to obtain an updated global model. To fully utilise all GPUs, systems must increase the batch size, which hinders statistical efficiency. Users tune hyper-parameters such as the learning rate to compensate for this, which is complex and model-specific. We describe CROSSBOW, a new single-server multi-GPU system for training deep learning models that enables users to freely choose their preferred batch size – however small – while scaling to multiple GPUs. CROSSBOW uses many parallel model replicas and avoids reduced statistical efficiency through a new synchronous training method. We introduce SMA, a synchronous variant of model averaging in which replicas independently explore the solution space with gradient descent, but adjust their search synchronously based on the trajectory of a globally-consistent average model. CROSSBOW achieves high hardware efficiency with small batch sizes by potentially training multiple model replicas per GPU, automatically tuning the number of replicas to maximise throughput. Our experiments show that CROSSBOW improves the training time of deep learning models on an 8-GPU server by 1.3-4x compared to TensorFlow.
DEMN: Distilled-Exposition Enhanced Matching Network for Story Comprehension
This paper proposes a Distilled-Exposition Enhanced Matching Network (DEMN) for story-cloze test, which is still a challenging task in story comprehension. We divide a complete story into three narrative segments: an \textit{exposition}, a \textit{climax}, and an \textit{ending}. The model consists of three modules: input module, matching module, and distillation module. The input module provides semantic representations for the three segments and then feeds them into the other two modules. The matching module collects interaction features between the ending and the climax. The distillation module distills the crucial semantic information in the exposition and infuses it into the matching module in two different ways. We evaluate our single and ensemble model on ROCStories Corpus \cite{Mostafazadeh2016ACA}, achieving an accuracy of 80.1\% and 81.2\% on the test set respectively. The experimental results demonstrate that our DEMN model achieves a state-of-the-art performance.
Artificial Intelligence and Machine Learning to Predict and Improve Efficiency in Manufacturing Industry
The overall equipment effectiveness (OEE) is a performance measurement metric widely used. Its calculation provides to the managers the possibility to identify the main losses that reduce the machine effectiveness and then take the necessary decisions in order to improve the situation. However, this calculation is done a-posterior which is often too late. In the present research, we implemented different Machine Learning algorithms namely; Support vector machine, Optimized Support vector Machine (using Genetic Algorithm), Random Forest, XGBoost and Deep Learning to predict the estimate OEE value. The data used to train our models was provided by an automotive cable production industry. The results show that the Deep Learning and Random Forest are more accurate and present better performance for the prediction of the overall equipment effectiveness in our case study.
Multi-Perspective Fusion Network for Commonsense Reading Comprehension
Commonsense Reading Comprehension (CRC) is a significantly challenging task, aiming at choosing the right answer for the question referring to a narrative passage, which may require commonsense knowledge inference. Most of the existing approaches only fuse the interaction information of choice, passage, and question in a simple combination manner from a \emph{union} perspective, which lacks the comparison information on a deeper level. Instead, we propose a Multi-Perspective Fusion Network (MPFN), extending the single fusion method with multiple perspectives by introducing the \emph{difference} and \emph{similarity} fusion\deleted{along with the \emph{union}}. More comprehensive and accurate information can be captured through the three types of fusion. We design several groups of experiments on MCScript dataset \cite{Ostermann:LREC18:MCScript} to evaluate the effectiveness of the three types of fusion respectively. From the experimental results, we can conclude that the difference fusion is comparable with union fusion, and the similarity fusion needs to be activated by the union fusion. The experimental result also shows that our MPFN model achieves the state-of-the-art with an accuracy of 83.52\% on the official test set.
Fair Algorithms for Clustering

Contamination Attacks and Mitigation in Multi-Party Machine Learning
Machine learning is data hungry; the more data a model has access to in training, the more likely it is to perform well at inference time. Distinct parties may want to combine their local data to gain the benefits of a model trained on a large corpus of data. We consider such a case: parties get access to the model trained on their joint data but do not see each others individual datasets. We show that one needs to be careful when using this multi-party model since a potentially malicious party can taint the model by providing contaminated data. We then show how adversarial training can defend against such attacks by preventing the model from learning trends specific to individual parties data, thereby also guaranteeing party-level membership privacy.
Interpretable CNNs
This paper proposes a generic method to learn interpretable convolutional filters in a deep convolutional neural network (CNN), where each interpretable filter encodes features of a specific object part. Our method does not require additional annotations of object parts or textures for supervision. Instead, we use the same training data as traditional CNNs. Our method automatically assigns each interpretable filter in a high conv-layer with an object part of a certain category during the learning process. Such explicit knowledge representations in conv-layers of CNN help people clarify the logic encoded in the CNN, i.e., answering what patterns the CNN extracts from an input image and uses for prediction. We have tested our method using different benchmark CNNs with various structures to demonstrate the broad applicability of our method. Experiments have shown that our interpretable filters are much more semantically meaningful than traditional filters.
Learning with Collaborative Neural Network Group by Reflection
For the present engineering of neural systems, the preparing of extensive scale learning undertakings generally not just requires a huge neural system with a mind boggling preparing process yet additionally troublesome discover a clarification for genuine applications. In this paper, we might want to present the Collaborative Neural Network Group (CNNG). CNNG is a progression of neural systems that work cooperatively to deal with various errands independently in a similar learning framework. It is advanced from a solitary neural system by reflection. Along these lines, in light of various circumstances removed by the calculation, the CNNG can perform diverse techniques when handling the information. The examples of chose methodology can be seen by human to make profound adapting more reasonable. In our execution, the CNNG is joined by a few moderately little neural systems. We give a progression of examinations to assess the execution of CNNG contrasted with other learning strategies. The CNNG is able to get a higher accuracy with a much lower training cost. We can reduce the error rate by 74.5% and reached the accuracy of 99.45% in MNIST with three feedforward networks (4 layers) in one training epoch.
Like this:
Like Loading…
Related