PyOD: A Python Toolbox for Scalable Outlier Detection
Toward a Theory of Cyber Attacks
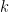



Causality and Bayesian network PDEs for multiscale representations of porous media
Microscopic (pore-scale) properties of porous media affect and often determine their macroscopic (continuum- or Darcy-scale) counterparts. Understanding the relationship between processes on these two scales is essential to both the derivation of macroscopic models of, e.g., transport phenomena in natural porous media, and the design of novel materials, e.g., for energy storage. Most microscopic properties exhibit complex statistical correlations and geometric constraints, which presents challenges for the estimation of macroscopic quantities of interest (QoIs), e.g., in the context of global sensitivity analysis (GSA) of macroscopic QoIs with respect to microscopic material properties. We present a systematic way of building correlations into stochastic multiscale models through Bayesian networks. This allows us to construct the joint probability density function (PDF) of model parameters through causal relationships that emulate engineering processes, e.g., the design of hierarchical nanoporous materials. Such PDFs also serve as input for the forward propagation of parametric uncertainty; our findings indicate that the inclusion of causal relationships impacts predictions of macroscopic QoIs. To assess the impact of correlations and causal relationships between microscopic parameters on macroscopic material properties, we use a moment-independent GSA based on the differential mutual information. Our GSA accounts for the correlated inputs and complex non-Gaussian QoIs. The global sensitivity indices are used to rank the effect of uncertainty in microscopic parameters on macroscopic QoIs, to quantify the impact of causality on the multiscale model’s predictions, and to provide physical interpretations of these results for hierarchical nanoporous materials.
Better Guider Predicts Future Better: Difference Guided Generative Adversarial Networks
Predicting the future is a fantasy but practicality work. It is the key component to intelligent agents, such as self-driving vehicles, medical monitoring devices and robotics. In this work, we consider generating unseen future frames from previous obeservations, which is notoriously hard due to the uncertainty in frame dynamics. While recent works based on generative adversarial networks (GANs) made remarkable progress, there is still an obstacle for making accurate and realistic predictions. In this paper, we propose a novel GAN based on inter-frame difference to circumvent the difficulties. More specifically, our model is a multi-stage generative network, which is named the Difference Guided Generative Adversarial Netwok (DGGAN). The DGGAN learns to explicitly enforce future-frame predictions that is guided by synthetic inter-frame difference. Given a sequence of frames, DGGAN first uses dual paths to generate meta information. One path, called Coarse Frame Generator, predicts the coarse details about future frames, and the other path, called Difference Guide Generator, generates the difference image which include complementary fine details. Then our coarse details will then be refined via guidance of difference image under the support of GANs. With this model and novel architecture, we achieve state-of-the-art performance for future video prediction on UCF-101, KITTI.
Generalization in Deep Networks: The Role of Distance from Initialization

Ten ways to fool the masses with machine learning
If you want to tell people the truth, make them laugh, otherwise they’ll kill you. (source unclear) Machine learning and deep learning are the technologies of the day for developing intelligent automatic systems. However, a key hurdle for progress in the field is the literature itself: we often encounter papers that report results that are difficult to reconstruct or reproduce, results that mis-represent the performance of the system, or contain other biases that limit their validity. In this semi-humorous article, we discuss issues that arise in running and reporting results of machine learning experiments. The purpose of the article is to provide a list of watch out points for researchers to be aware of when developing machine learning models or writing and reviewing machine learning papers.
Vector representations of text data in deep learning
In this dissertation we report results of our research on dense distributed representations of text data. We propose two novel neural models for learning such representations. The first model learns representations at the document level, while the second model learns word-level representations. For document-level representations we propose Binary Paragraph Vector: a neural network models for learning binary representations of text documents, which can be used for fast document retrieval. We provide a thorough evaluation of these models and demonstrate that they outperform the seminal method in the field in the information retrieval task. We also report strong results in transfer learning settings, where our models are trained on a generic text corpus and then used to infer codes for documents from a domain-specific dataset. In contrast to previously proposed approaches, Binary Paragraph Vector models learn embeddings directly from raw text data. For word-level representations we propose Disambiguated Skip-gram: a neural network model for learning multi-sense word embeddings. Representations learned by this model can be used in downstream tasks, like part-of-speech tagging or identification of semantic relations. In the word sense induction task Disambiguated Skip-gram outperforms state-of-the-art models on three out of four benchmarks datasets. Our model has an elegant probabilistic interpretation. Furthermore, unlike previous models of this kind, it is differentiable with respect to all its parameters and can be trained with backpropagation. In addition to quantitative results, we present qualitative evaluation of Disambiguated Skip-gram, including two-dimensional visualisations of selected word-sense embeddings.
Stochastic Approximation Algorithms for Principal Component Analysis
Principal Component Analysis is a novel way of of dimensionality reduction. This problem essentially boils down to finding the top k eigen vectors of the data covariance matrix. A considerable amount of literature is found on algorithms meant to do so such as an online method be Warmuth and Kuzmin, Matrix Stochastic Gradient by Arora, Oja’s method and many others. In this paper we see some of these stochastic approaches to the PCA optimization problem and comment on their convergence and runtime to obtain an epsilon sub-optimal solution. We revisit convex relaxation based methods for stochastic optimization of principal component analysis. While methods that directly solve the non convex problem have been shown to be optimal in terms of statistical and computational efficiency, the methods based on convex relaxation have been shown to enjoy comparable, or even superior, empirical performance. This motivates the need for a deeper formal understanding of the latter.
Interactive Matching Network for Multi-Turn Response Selection in Retrieval-Based Chatbots
In this paper, we propose an interactive matching network (IMN) to enhance the representations of contexts and responses at both the word level and sentence level for the multi-turn response selection task. First, IMN constructs word representations from three aspects to address the challenge of out-of-vocabulary (OOV) words. Second, an attentive hierarchical recurrent encoder (AHRE), which is capable of encoding sentences hierarchically and generating more descriptive representations by aggregating with an attention mechanism, is designed. Finally, the bidirectional interactions between whole multi-turn contexts and response candidates are calculated to derive the matching information between them. Experiments on four public datasets show that IMN significantly outperforms the baseline models by large margins on all metrics, achieving new state-of-the-art performance and demonstrating compatibility across domains for multi-turn response selection.
Bloom Multifilters for Multiple Set Matching
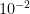
DSConv: Efficient Convolution Operator
We introduce a variation of the convolutional layer called DSConv (Distribution Shifting Convolution) that can be readily substituted into standard neural network architectures and achieve both lower memory usage and higher computational speed. DSConv breaks down the traditional convolution kernel into two components: Variable Quantized Kernel (VQK), and Distribution Shifts. Lower memory usage and higher speeds are achieved by storing only integer values in the VQK, whilst preserving the same output as the original convolution by applying both kernel and channel based distribution shifts. We test DSConv in ImageNet on ResNet50 and 34, as well as AlexNet and MobileNet. We achieve a reduction in memory usage of up to 14x in the convolutional kernels and speed up operations of up to 10x by substituting floating point operations to integer operations. Furthermore, unlike other quantization approaches, our work allows for a degree of retraining to new tasks and datasets.
Decision-making and Fuzzy Temporal Logic
There are moments where we make decisions involving tradeoffs among costs and benefits occurring in different times. Essentially, in these cases, we are evaluating dynamic processes with outcomes still unknown. So, do we use some intuitive logic to judge changes involving values and time? The fuzzy temporal logic, introduced in this paper, proposes to model the figures of thought necessary to form a rhetoric for decision-making. To exemplify, the intertemporal choices and the lotteries choices are analyzed. The first problem is related to the time preference of receiving amounts on different dates. So it is shown that a subadditive hyperbolic discount function is not anomaly, but it consistently describes the goods delay within the fuzzy temporal logic. The second problem is related to values and probabilities of lotteries, where Prospect Theory behaviors and the S-shaped curve can be described using tense operators and fuzzy set operators. In addition, it is shown that some behaviors are amount dependent where the fuzziness can be decisive in the judgment. Thus, time, uncertainty and fuzziness are unified in a single matter which models the rhetoric for decision-making in different contexts of gains and losses.
Like this:
Like Loading…
Related