By Mehmet Suzen, U. of Frankfurt
Preamble
Almost all businesses and industry embraced Machine learning (ML) technologies. Apart from ROI concerns, as it is an expensive endeavour to develop and deploy a service driven by ML techniques, sustainability as in going beyond proof-of-concept core development appears to be one of the roadblocks in data science. In this post, we will outline basic logical core principles that can help organisations for sustainable AI product development cycle, apart from reproducibility issues. The aim is giving a coarser view, rather than listing fine-grain good practice advice.
Research as a core driver: Research Environment
Regardless of the size of your organisation, if you are developing machine learning or AI products, the core asset you have is a research professional, data scientist or AI scientist, regardless of their academic background. Developing a model using software libraries blindly won’t resolve issues you might encounter after deployment of the product. For example, even if you need to do a simple hyperparameter search, this can easily yield to research. Why? Because most probably no one ever tried building a model or try a modelling task using your dataset and you might need a different approach than ML libraries provide. A simplest different angle or deviation from ML libraries will yield to a research problem.
No full ‘black-box’ approaches. No blind usage of software libraries. Awareness and skills in the mathematical and algorithmic aspect in detail.
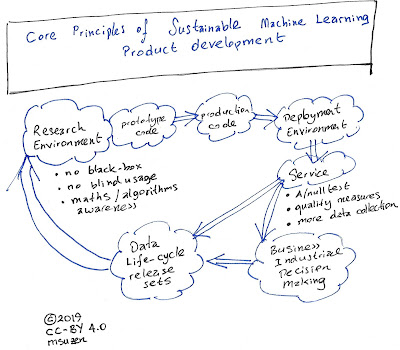
Software development is an integral part of ML product development. However, during research, a code development can go very wild and a scientist, even if they are very good software developers, would end up creating hard to follow and poor code. Once there is a confidence in reproducibility and robustness of results, the production code should be re-written with high-quality software engineering principles.
Data Standardisation: Release data-sets for research A cold start problem for ML products is to release and design data-sets before even doing any research like work. This, of course, has to be aligned with industrial requirements. Imagine datasets like MINST or imagenet for benchmarking. Released sets will be the first step for any model building or product development, and would constitute a data product themselves. Data versioning is also a must.
Do not obsess with workflows: All workflows are ad-hoc
There is no such thing as a universal or generic workflow. A workflow depends on a human understanding of processes and steps. Human understanding is based on language and linguistically there is no such thing as universal language, at least it isn’t practical yet c.f., universal grammar. Loosely defined steps are sufficient for research steps. However, once it entered into production, then much more strict workflow design might be needed, but be aware all workflows are ad-hoc.
Do not run sprints for core data science
Agile principles are suitable for software development innovations. Sprints or Agile is not suitable for AI research and research environment, it is a different kind of innovation than software engineering. Thinking that Agile is a cure to do scientific innovation is naive wishful thinking. Structuring a research group, periodic reviews and releases of the results via presentations and detailed technical reports are much more suitable for data science on top of mini-workshops. A simple proposal runs can also be made to decide which direction to invest, akin to research proposals.
Feedback loop: Service to Business decision making back to research
A service using ML technologies should produce more data. The very first service monitoring is A/Null testing, meaning that what would happen in the absence of the AI product. Detailed analysis of the service data would bring more insights both for business and to research.
produce impact assessment: A/null testing quality of service: Quality of service can be measured basically on what is the success of the ML model, this has to be technical.
Conclusion and outlook
There is no such thing as free-lunch and developing AI products won’t be fully automated soon. Tools may improve the productivity immensely but AI replacing a data scientist or AI scientist is far from reality, at least for now. If you are investing in AI products, basically you are investing in research at the core, missing that important point may cost organisations a lot. The basic core principles or variation of them may help in sustaining AI products longer and form your teams accordingly.
Bio:Dr. Mehmet Suzen is a Theoretical Physicist and Research Scientist. He blogs on data science at Memos’ Island.
Original. Reposted with permission.
Related: