offset
According to the official R documentation, offset should be
A vector of length nobs that is included in the linear predictor (a nobs x nc matrix for the “multinomial� family).
Its default value is NULL: in that case, glmnet internally sets the offset to be a vector of zeros having the same length as the response y.
Here is some example code for using the offset option:
If we specify offset in the glmnet call, then when making predictions with the model, we must specify the newoffset option. For example, if we want the predictions fit1 gives us at 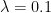
newoffset will give us an error:

This is the correct code:
So, what does offset actually do (or mean)? Recall that glmnet is fitting a linear model. More concretely, our data is 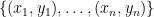


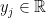
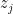

For ordinary regression, 
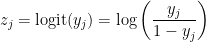
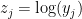
So, we are trying to find 
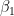
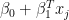
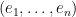

Why might we want to use offsets? There are two primary reasons for them stated in the documentation:
Useful for the “poisson� family (e.g. log of exposure time), or for refining a model by starting at a current fit.
Let me elaborate. First, offsets are useful for Poisson regression. The official vignette has a little section explaining this; let me explain it through an example.
Imagine that we are trying to predict how many points an NBA basketball player will score per minute based on his physical attributes. If the player’s physical attributes (i.e. the covariates of our model) are denoted by 
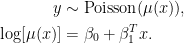
Having described the model, let’s turn to our data. For each player 
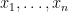
Offsets allow us to use our data as is. In our example above, loosely speaking 12/30 (points per minute) is our estimate for 
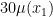
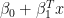
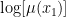

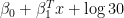
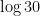
Taking this to the full dataset: if player 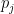
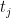
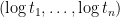
glmnet is 
The second reason one might want to use offsets is to improve on an existing model. Continuing the example above: say we have a friend who has trained a model (not necessarily a linear model) to predict 

where 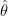

newoffset option in the predict call.
Related