ByGhazaleh Beigi andHuan Liu, Arizona State University
Web browsing history, which is a list of web pages (i.e., URLs) a user has visited in the past browsing sessions, is one of the most significant portions of data that users generate through their online activities. This information is critical for online vendors to profile users’ preferences from their activities to predict their future needs. Utility of browsing history therefore affects the quality of provided online personalized services and user’s satisfaction about the services. Conversely, people expect a privacy-preserving environment when surfing the web. Since users’ browsing histories are recorded by Internet Service Providers (ISPs) or by third-party trackers embedded on the web pages, users’ sensitive and private information such as political views, sexual orientation, medical and financial information could be easily inferred from their web browsing history.
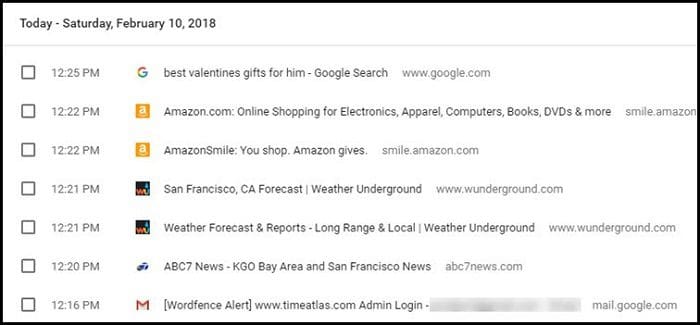
Figure1. By looking at this browsing history, we can easily infer that the user’s gender is female, she is living in San Francisco, and is married.
The privacy issues get even worse with the overturning of the Internet Privacy Rules by the Federal Communications Commission (FCC) in late March 2017 that allows Internet Service Providers (ISPs) to collect, share and sell their customers’ Web browsing data without their consent. All of these private information leakage and identity exposures may result in unexpected harms ranging from persecution by governments to targeted frauds.
The onus is now on the users to protect their browsing history from adversaries. There are approaches to help users shield their web browsing history such as browser add-ons or extensions (e.g., Ghostery', Privacy Badger’ and `HTTPS everywhere’), Virtual Private Networks (VPN) services, Tor, and HTTPS. However, using these solutions could result in the decreased quality of online personalized services due to the lack of customer’s information. User’s information is critical for online vendors to offer personalized services. Moreover, none of the above solutions can prevent ISPs from collecting users’ web browsing history and protect users’ identities when such information is revealed. Thus, users face a dilemma between user privacy and utility (i.e., personalized service satisfaction).
Figure 2. It is challenging to solve the dilemma between privacy and utility.
A recent paper accepted to the 12th ACM international conference on Web Search and Data Mining (WSDM’19)proposes a novel solution to the utility-privacy challenge, namely, PBooster. Achieving a solution that can both preserve privacy and retain high utility is challenging. The reason is twofold: first, it is not straightforward to quantify the privacy of users and the utility of their personalized services in the context of web browsing history data; and second, it is a tedious task to infer what the required number of links is and what links should be added to a user’s browsing history to boost privacy while retaining high utility. PBooster is a non-compromising and effective approach to achieve high user privacy and utility.
In order to quantify privacy and utility in the context of web browsing history data, two metrics have been proposed and used by PBooster. These two metrics utilize topic probability distribution of browsing history for a given user. Having introduced metrics for capturing user’s privacy and utility, the goal is now to find a set of new links to be added to the browsing history such that privacy is maximized, and utility loss is minimized. PBooster tackles this problem by dividing it into two subproblems:
1) topic selection and
2) link selection.
In the topic selection phase, PBooster searches for a subset of topics and calculates the number of links which should be added to each topic in order to maximize the privacy and minimize the utility loss for the manipulated history. Finally, in the link selection phase, PBooster exploits publicly available information in social media networks as an auxiliary source of information to select a proper set of links which corresponds to the identified topics and their numbers found in the previous step. These links will be then added to the user’s browsing history.
For more details about PBooster and how it works, interested readers can refer to the abovementioned WSDM’19 paper which is available at https://arxiv.org/abs/1811.09340 .
Bios: Ghazaleh Beigi is a PhD candidate of Computer Science and Engineering at Arizona State University. Her research interests include privacy protection, trust prediction, recommendation systems, sentiment analysis, and machine learning. Huan Liu is a professor of Computer Science and Engineering at Arizona State University.
Resources:
Related: