Automatic Summarization of Natural Language
Automatic summarization of natural language is a current topic in computer science research and industry, studied for decades because of its usefulness across multiple domains. For example, summarization is necessary to create reviews such as this one. Research and applications have achieved some success in extractive summarization (where key sentences are curated), however, abstractive summarization (synthesis and re-stating) is a hard problem and generally unsolved in computer science. This literature review contrasts historical progress up through current state of the art, comparing dimensions such as: extractive vs. abstractive, supervised vs. unsupervised, NLP (Natural Language Processing) vs Knowledge-based, deep learning vs algorithms, structured vs. unstructured sources, and measurement metrics such as Rouge and BLEU. Multiple dimensions are contrasted since current research uses combinations of approaches as seen in the review matrix. Throughout this summary, synthesis and critique is provided. This review concludes with insights for improved abstractive summarization measurement, with surprising implications for detecting understanding and comprehension in general.
Certainty of outlier and boundary points processing in data mining
Data certainty is one of the issues in the real-world applications which is caused by unwanted noise in data. Recently, more attentions have been paid to overcome this problem. We proposed a new method based on neutrosophic set (NS) theory to detect boundary and outlier points as challenging points in clustering methods. Generally, firstly, a certainty value is assigned to data points based on the proposed definition in NS. Then, certainty set is presented for the proposed cost function in NS domain by considering a set of main clusters and noise cluster. After that, the proposed cost function is minimized by gradient descent method. Data points are clustered based on their membership degrees. Outlier points are assigned to noise cluster and boundary points are assigned to main clusters with almost same membership degrees. To show the effectiveness of the proposed method, two types of datasets including 3 datasets in Scatter type and 4 datasets in UCI type are used. Results demonstrate that the proposed cost function handles boundary and outlier points with more accurate membership degrees and outperforms existing state of the art clustering methods.
Multimodal deep learning for short-term stock volatility prediction
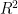


Maximum Likelihood Estimation and Graph Matching in Errorfully Observed Networks
Given a pair of graphs with the same number of vertices, the inexact graph matching problem consists in finding a correspondence between the vertices of these graphs that minimizes the total number of induced edge disagreements. We study this problem from a statistical framework in which one of the graphs is an errorfully observed copy of the other. We introduce a corrupting channel model, and show that in this model framework, the solution to the graph matching problem is a maximum likelihood estimator. Necessary and sufficient conditions for consistency of this MLE are presented, as well as a relaxed notion of consistency in which a negligible fraction of the vertices need not be matched correctly. The results are used to study matchability in several families of random graphs, including edge independent models, random regular graphs and small-world networks. We also use these results to introduce measures of matching feasibility, and experimentally validate the results on simulated and real-world networks.
Exploring the Challenges towards Lifelong Fact Learning
So far life-long learning (LLL) has been studied in relatively small-scale and relatively artificial setups. Here, we introduce a new large-scale alternative. What makes the proposed setup more natural and closer to human-like visual systems is threefold: First, we focus on concepts (or facts, as we call them) of varying complexity, ranging from single objects to more complex structures such as objects performing actions, and objects interacting with other objects. Second, as in real-world settings, our setup has a long-tail distribution, an aspect which has mostly been ignored in the LLL context. Third, facts across tasks may share structure (e.g., <person, riding, wave> and <dog, riding, wave>). Facts can also be semantically related (e.g., ‘liger’ relates to seen categories like ‘tiger’ and ‘lion’). Given the large number of possible facts, a LLL setup seems a natural choice. To avoid model size growing over time and to optimally exploit the semantic relations and structure, we combine it with a visual semantic embedding instead of discrete class labels. We adapt existing datasets with the properties mentioned above into new benchmarks, by dividing them semantically or randomly into disjoint tasks. This leads to two large-scale benchmarks with 906,232 images and 165,150 unique facts, on which we evaluate and analyze state-of-the-art LLL methods.
Adversarial Attack and Defense on Graph Data: A Survey
Deep neural networks (DNNs) have been widely applied in various applications involving image, text, audio, and graph data. However, recent studies have shown that DNNs are vulnerable to adversarial attack. Though there are several works studying adversarial attack and defense on domains such as images and text processing, it is difficult to directly transfer the learned knowledge to graph data due to its representation challenge. Given the importance of graph analysis, increasing number of works start to analyze the robustness of machine learning models on graph. Nevertheless, current studies considering adversarial behaviors on graph data usually focus on specific types of attacks with certain assumptions. In addition, each work proposes its own mathematical formulation which makes the comparison among different methods difficult. Therefore, in this paper, we aim to survey existing adversarial attack strategies on graph data and provide an unified problem formulation which can cover all current adversarial learning studies on graph. We also compare different attacks on graph data and discuss their corresponding contributions and limitations. Finally, we discuss several future research directions in this area.
Toward a self-learned Smart Contracts
In recent years, Blockchain technology has been highly valued and disruptive. Several researches have presented a merge between blockchain and current application i.e. medical, supply chain, and e-commerce. Although Blockchain architecture does not have a standard yet, IBM, MS, AWS offer BaaS (Blockchain as a Service). In addition to the current public chains i.e. Ethereum, NEO, and Cardeno; there are some differences between several public ledgers in terms of development and architecture. This paper introduces the main factors that affect integration of Artificial Intelligence with Blockchain. As well as, how it could be integrated for forecasting and automating; building self-regulated chain.
Prediction of Industrial Process Parameters using Artificial Intelligence Algorithms
In the present paper, a method of defining the industrial process parameters for a new product using machine learning algorithms will be presented. The study will describe how to go from the product characteristics till the prediction of the suitable machine parameters to produce a good quality of this product, and this is based on an historical training dataset of similar products with their respective process parameters. In the first part of our study, we will focus on the ultrasonic welding process definition, welding parameters and on how it operate. While in second part, we present the design and implementation of the prediction models such multiple linear regression, support vector regression, and we compare them to an artificial neural networks algorithm. In the following part, we present a new application of Convolutional Neural Networks (CNN) to the industrial process parameters prediction. In addition, we will propose the generalization approach of our CNN to any prediction problem of industrial process parameters. Finally the results of the four methods will be interpreted and discussed.
Uncertainty Autoencoders: Learning Compressed Representations via Variational Information Maximization
The goal of statistical compressive sensing is to efficiently acquire and reconstruct high-dimensional signals with much fewer measurements than the data dimensionality, given access to a finite set of training signals. Current approaches do not learn the acquisition and recovery procedures end-to-end and are typically hand-crafted for sparsity based priors. We propose Uncertainty Autoencoders, a framework that jointly learns the acquisition (i.e., encoding) and recovery (i.e., decoding) procedures while implicitly modeling domain structure. Our learning objective optimizes for a variational lower bound to the mutual information between the signal and the measurements. We show how our framework provides a unified treatment to several lines of research in dimensionality reduction, compressive sensing, and generative modeling. Empirically, we demonstrate improvements of 32% on average over competing approaches for statistical compressive sensing of high-dimensional datasets.
Deep Item-based Collaborative Filtering for Sparse Implicit Feedback
Recommender systems are ubiquitous in the domain of e-commerce, used to improve the user experience and to market inventory, thereby increasing revenue for the site. Techniques such as item-based collaborative filtering are used to model users’ behavioral interactions with items and make recommendations from items that have similar behavioral patterns. However, there are challenges when applying these techniques on extremely sparse and volatile datasets. On some e-commerce sites, such as eBay, the volatile inventory and minimal structured information about items make it very difficult to aggregate user interactions with an item. In this work, we describe a novel deep learning-based method to address the challenges. We propose an objective function that optimizes a similarity measure between binary implicit feedback vectors between two items. We demonstrate formally and empirically that a model trained to optimize this function estimates the log of the cosine similarity between the feedback vectors. We also propose a neural network architecture optimized on this objective. We present the results of experiments comparing the output of the neural network with traditional item-based collaborative filtering models on an implicit-feedback dataset, as well as results of experiments comparing different neural network architectures on user purchase behavior on eBay. Finally, we discuss the results of an A/B test that show marked improvement of the proposed technique over eBay’s existing collaborative filtering recommender system.
Generalized Score Matching for Non-Negative Data


BlinkML: Efficient Maximum Likelihood Estimation with Probabilistic Guarantees
The rising volume of datasets has made training machine learning (ML) models a major computational cost in the enterprise. Given the iterative nature of model and parameter tuning, many analysts use a small sample of their entire data during their initial stage of analysis to make quick decisions (e.g., what features or hyperparameters to use) and use the entire dataset only in later stages (i.e., when they have converged to a specific model). This sampling, however, is performed in an ad-hoc fashion. Most practitioners cannot precisely capture the effect of sampling on the quality of their model, and eventually on their decision-making process during the tuning phase. Moreover, without systematic support for sampling operators, many optimizations and reuse opportunities are lost. In this paper, we introduce BlinkML, a system for fast, quality-guaranteed ML training. BlinkML allows users to make error-computation tradeoffs: instead of training a model on their full data (i.e., full model), BlinkML can quickly train an approximate model with quality guarantees using a sample. The quality guarantees ensure that, with high probability, the approximate model makes the same predictions as the full model. BlinkML currently supports any ML model that relies on maximum likelihood estimation (MLE), which includes Generalized Linear Models (e.g., linear regression, logistic regression, max entropy classifier, Poisson regression) as well as PPCA (Probabilistic Principal Component Analysis). Our experiments show that BlinkML can speed up the training of large-scale ML tasks by 6.26x-629x while guaranteeing the same predictions, with 95% probability, as the full model.
QuickSel: Quick Selectivity Learning with Mixture Models
Estimating the selectivity of a query is a key step in almost any cost-based query optimizer. Most of today’s databases rely on histograms or samples that are periodically refreshed by re-scanning the data as the underlying data changes. Since frequent scans are costly, these statistics are often stale and lead to poor selectivity estimates. As an alternative to scans, query-driven histograms have been proposed, which refine the histograms based on the actual selectivities of the observed queries. Unfortunately, these approaches are either too costly to use in practice—i.e., require an exponential number of buckets—or quickly lose their advantage as they observe more queries. For example, the state-of-the-art technique requires 318,936 buckets (and over 8 seconds of refinement overhead per query) after observing only 300 queries. In this paper, we propose a selectivity learning framework, called QuickSel, which falls into the query-driven paradigm but does not use histograms. Instead, it builds an internal model of the underlying data, which can be refined significantly faster (e.g., only 1.9 milliseconds for 300 queries). This fast refinement allows QuickSel to continuously learn from each query and yield increasingly more accurate selectivity estimates over time. Unlike query-driven histograms, QuickSel relies on a mixture model and a new optimization algorithm for training its model. Our extensive experiments on two real-world datasets confirm that, given the same target accuracy, QuickSel is on average 254.6x faster than state-of-the-art query-driven histograms, including ISOMER and STHoles. Further, given the same space budget, QuickSel is on average 57.3% and 91.1% more accurate than periodically-updated histograms and samples, respectively.
Secure Estimation under Causative Attacks
This paper considers the problem of secure parameter estimation when the estimation algorithm is prone to causative attacks. Causative attacks, in principle, target decision-making algorithms to alter their decisions by making them oblivious to specific attacks. Such attacks influence inference algorithms by tampering with the mechanism through which the algorithm is provided with the statistical model of the population about which an inferential decision is made. Causative attacks are viable, for instance, by contaminating the historical or training data, or by compromising an expert who provides the model. In the presence of causative attacks, the inference algorithms operate under a distorted statistical model for the population from which they collect data samples. This paper introduces specific notions of secure estimation and provides a framework under which secure estimation under causative attacks can be formulated. A central premise underlying the secure estimation framework is that forming secure estimates introduces a new dimension to the estimation objective, which pertains to detecting attacks and isolating the true model. Since detection and isolation decisions are imperfect, their inclusion induces an inherent coupling between the desired secure estimation objective and the auxiliary detection and isolation decisions that need to be formed in conjunction with the estimates. This paper establishes the fundamental interplay among the decisions involved and characterizes the general decision rules in closed-form for any desired estimation cost function. Furthermore, to circumvent the computational complexity associated with growing parameter dimension or attack complexity, a scalable estimation algorithm and its attendant optimality guarantees are provided. The theory developed is applied to secure parameter estimation in a sensor network.
Deconfounding Reinforcement Learning in Observational Settings
Linearized Gaussian Processes for Fast Data-driven Model Predictive Control
Data-driven Model Predictive Control (MPC), where the system model is learned from data with machine learning, has recently gained increasing interests in the control community. Gaussian Processes (GP), as a type of statistical models, are particularly attractive due to their modeling flexibility and their ability to provide probabilistic estimates of prediction uncertainty. GP-based MPC has been developed and applied, however the optimization problem is typically non-convex and highly demanding, and scales poorly with model size. This causes unsatisfactory solving performance, even with state-of-the-art solvers, and makes the approach less suitable for real-time control. We develop a method based on a new concept, called linearized Gaussian Process, and Sequential Convex Programming, that can significantly improve the solving performance of GP-based MPC. Our method is not only faster but also much more scalable and predictable than other commonly used methods, as it is much less influenced by the model size. The efficiency and advantages of the algorithm are demonstrated clearly in a numerical example.
Hierarchical Clustering for Euclidean Data
Recent works on Hierarchical Clustering (HC), a well-studied problem in exploratory data analysis, have focused on optimizing various objective functions for this problem under arbitrary similarity measures. In this paper we take the first step and give novel scalable algorithms for this problem tailored to Euclidean data in R^d and under vector-based similarity measures, a prevalent model in several typical machine learning applications. We focus primarily on the popular Gaussian kernel and other related measures, presenting our results through the lens of the objective introduced recently by Moseley and Wang [2017]. We show that the approximation factor in Moseley and Wang [2017] can be improved for Euclidean data. We further demonstrate both theoretically and experimentally that our algorithms scale to very high dimension d, while outperforming average-linkage and showing competitive results against other less scalable approaches.
Bayesian Fusion Estimation via t-Shrinkage
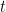
Neural Model-Based Reinforcement Learning for Recommendation
There are great interests as well as many challenges in applying reinforcement learning (RL) to recommendation systems. In this setting, an online user is the environment; neither the reward function nor the environment dynamics are clearly defined, making the application of RL challenging. In this paper, we propose a novel model-based reinforcement learning framework for recommendation systems, where we develop a generative adversarial network to imitate user behavior dynamics and learn her reward function. Using this user model as the simulation environment, we develop a novel DQN algorithm to obtain a combinatorial recommendation policy which can handle a large number of candidate items efficiently. In our experiments with real data, we show this generative adversarial user model can better explain user behavior than alternatives, and the RL policy based on this model can lead to a better long-term reward for the user and higher click rate for the system.
Stanza: Distributed Deep Learning with Small Communication Footprint
The parameter server architecture is prevalently used for distributed deep learning. Each worker machine in a parameter server system trains the complete model, which leads to a hefty amount of network data transfer between workers and servers. We empirically observe that the data transfer has a non-negligible impact on training time. To tackle the problem, we design a new distributed training system called Stanza. Stanza exploits the fact that in many models such as convolution neural networks, most data exchange is attributed to the fully connected layers, while most computation is carried out in convolutional layers. Thus, we propose layer separation in distributed training: the majority of the nodes just train the convolutional layers, and the rest train the fully connected layers only. Gradients and parameters of the fully connected layers no longer need to be exchanged across the cluster, thereby substantially reducing the data transfer volume. We implement Stanza on PyTorch and evaluate its performance on Azure and EC2. Results show that Stanza accelerates training significantly over current parameter server systems: on EC2 instances with Tesla V100 GPU and 10Gb bandwidth for example, Stanza is 1.34x–13.9x faster for common deep learning models.
Power Comparison between High Dimensional t-Test, Sign, and Signed Rank Tests
In this paper, we propose a power comparison between high dimensional t-test, sign and signed rank test for the one sample mean test. We show that the high dimensional signed rank test is superior to a high dimensional t test, but inferior to a high dimensional sign test.
Intent Detection and Slots Prompt in a Closed-Domain Chatbot
In this paper, we introduce a methodology for predicting intent and slots of a query for a chatbot that answers career-related queries. We take a multi-staged approach where both the processes (intent-classification and slot-tagging) inform each other’s decision-making in different stages. The model breaks down the problem into stages, solving one problem at a time and passing on relevant results of the current stage to the next, thereby reducing search space for subsequent stages, and eventually making classification and tagging more viable after each stage. We also observe that relaxing rules for a fuzzy entity-matching in slot-tagging after each stage (by maintaining a separate Named Entity Tagger per stage) helps us improve performance, although at a slight cost of false-positives. Our model has achieved state-of-the-art performance with F1-score of 77.63% for intent-classification and 82.24% for slot-tagging on our dataset that we would publicly release along with the paper.
Low Latency Privacy Preserving Inference

Neural Architecture Search Over a Graph Search Space
Neural architecture search (NAS) enabled the discovery of state-of-the-art architectures in many domains. However, the success of NAS depends on the definition of the search space, i.e. the set of the possible to generate neural architectures. State-of-the-art search spaces are defined as a static sequence of decisions and a set of available actions for each decision, where each possible sequence of actions defines an architecture. We propose a more expressive formulation of NAS, using a graph search space. Our search space is defined as a graph where each decision is a vertex and each action is an edge. Thus the sequence of decisions defining an architecture is not fixed but is determined dynamically by the actions selected. The proposed approach allows to model iterative and branching aspects of the architecture design process. In this form, stronger priors about the search can be induced. We demonstrate in simulation basic iterative and branching search structures and show that using the graph representation improves sample efficiency.
Combining Non-probability and Probability Survey Samples Through Mass Imputation
This paper presents theoretical results on combining non-probability and probability survey samples through mass imputation, an approach originally proposed by Rivers (2007) as sample matching without rigorous theoretical justification. Under suitable regularity conditions, we establish the consistency of the mass imputation estimator and derive its asymptotic variance formula. Variance estimators are developed using either linearization or bootstrap. Finite sample performances of the mass imputation estimator are investigated through simulation studies and an application to analyzing a non-probability sample collected by the Pew Research Centre.
QRFA: A Data-Driven Model of Information-Seeking Dialogues
Understanding the structure of interaction processes helps us to improve information-seeking dialogue systems. Analyzing an interaction process boils down to discovering patterns in sequences of alternating utterances exchanged between a user and an agent. Process mining techniques have been successfully applied to analyze structured event logs, discovering the underlying process models or evaluating whether the observed behavior is in conformance with the known process. In this paper, we apply process mining techniques to discover patterns in conversational transcripts and extract a new model of information-seeking dialogues, QRFA, for Query, Request, Feedback, Answer. Our results are grounded in an empirical evaluation across multiple conversational datasets from different domains, which was never attempted before. We show that the QRFA model better reflects conversation flows observed in real information-seeking conversations than models proposed previously. Moreover, QRFA allows us to identify malfunctioning in dialogue system transcripts as deviations from the expected conversation flow described by the model via conformance analysis.
Facetize: An Interactive Tool for Cleaning and Transforming Datasets for Facilitating Exploratory Search
There is a plethora of datasets in various formats which are usually stored in files, hosted in catalogs, or accessed through SPARQL endpoints. In most cases, these datasets cannot be straightforwardly explored by end users, for satisfying recall-oriented information needs. To fill this gap, in this paper we present the design and implementation of Facetize, an editor that allows users to transform (in an interactive manner) datasets, either static (i.e. stored in files), or dynamic (i.e. being the results of SPARQL queries), to datasets that can be directly explored effectively by themselves or other users. The latter (exploration) is achieved through the familiar interaction paradigm of Faceted Search (and Preference-enriched Faceted Search). Specifically in this paper we describe the requirements, we introduce the required set of transformations, and then we detail the functionality and the implementation of the editor Facetize that realizes these transformations. The supported operations cover a wide range of tasks (selection, visibility, deletions, edits, definition of hierarchies, intervals, derived attributes, and others) and Facetize enables the user to carry them out in a user-friendly and guided manner, without presupposing any technical background (regarding data representation or query languages). Finally we present the results of an evaluation with users. To the best of your knowledge, this is the first editor for this kind of tasks.
CAN: Constrained Attention Networks for Multi-Aspect Sentiment Analysis
Aspect level sentiment classification is a fine-grained sentiment analysis task, compared to the sentence level classification. A sentence usually contains one or more aspects. To detect the sentiment towards a particular aspect in a sentence, previous studies have developed various methods for generating aspect-specific sentence representations. However, these studies handle each aspect of a sentence separately. In this paper, we argue that multiple aspects of a sentence are usually orthogonal based on the observation that different aspects concentrate on different parts of the sentence. To force the orthogonality among aspects, we propose constrained attention networks (CAN) for multi-aspect sentiment analysis, which handles multiple aspects of a sentence simultaneously. Experimental results on two public datasets demonstrate the effectiveness of our approach. We also extend our approach to multi-task settings, outperforming the state-of-the-arts significantly.
Off-the-grid model based deep learning (O-MODL)
We introduce a model based off-the-grid image reconstruction algorithm using deep learned priors. The main difference of the proposed scheme with current deep learning strategies is the learning of non-linear annihilation relations in Fourier space. We rely on a model based framework, which allows us to use a significantly smaller deep network, compared to direct approaches that also learn how to invert the forward model. Preliminary comparisons against image domain MoDL approach demonstrates the potential of the off-the-grid formulation. The main benefit of the proposed scheme compared to structured low-rank methods is the quite significant reduction in computational complexity.
How to avoid the zero-power trap in testing for correlation
In testing for correlation of the errors in regression models the power of tests can be very low for strongly correlated errors. This counterintuitive phenomenon has become known as the ‘zero-power trap’. Despite a considerable amount of literature devoted to this problem, mainly focusing on its detection, a convincing solution has not yet been found. In this article we first discuss theoretical results concerning the occurrence of the zero-power trap phenomenon. Then, we suggest and compare three ways to avoid it. Given an initial test that suffers from the zero-power trap, the method we recommend for practice leads to a modified test whose power converges to one as the correlation gets very strong. Furthermore, the modified test has approximately the same power function as the initial test, and thus approximately preserves all of its optimality properties. We also provide some numerical illustrations in the context of testing for network generated correlation.
Advancing the State of the Art in Open Domain Dialog Systems through the Alexa Prize
Building open domain conversational systems that allow users to have engaging conversations on topics of their choice is a challenging task. Alexa Prize was launched in 2016 to tackle the problem of achieving natural, sustained, coherent and engaging open-domain dialogs. In the second iteration of the competition in 2018, university teams advanced the state of the art by using context in dialog models, leveraging knowledge graphs for language understanding, handling complex utterances, building statistical and hierarchical dialog managers, and leveraging model-driven signals from user responses. The 2018 competition also included the provision of a suite of tools and models to the competitors including the CoBot (conversational bot) toolkit, topic and dialog act detection models, conversation evaluators, and a sensitive content detection model so that the competing teams could focus on building knowledge-rich, coherent and engaging multi-turn dialog systems. This paper outlines the advances developed by the university teams as well as the Alexa Prize team to achieve the common goal of advancing the science of Conversational AI. We address several key open-ended problems such as conversational speech recognition, open domain natural language understanding, commonsense reasoning, statistical dialog management, and dialog evaluation. These collaborative efforts have driven improved experiences by Alexa users to an average rating of 3.61, the median duration of 2 mins 18 seconds, and average turns to 14.6, increases of 14%, 92%, 54% respectively since the launch of the 2018 competition. For conversational speech recognition, we have improved our relative Word Error Rate by 55% and our relative Entity Error Rate by 34% since the launch of the Alexa Prize. Socialbots improved in quality significantly more rapidly in 2018, in part due to the release of the CoBot toolkit.
Semiparametric Estimation for the Transformation Model with Length-Biased Data and Covariate Measurement Error
Analysis of survival data with biased samples caused by left-truncation or length-biased sampling has received extensive interest. Many inference methods have been developed for various survival models. These methods, however, break down when survival data are typically error-contaminated. Although error-prone survival data commonly arise in practice, little work has been available in the literature for handling length-biased data with measurement error. In survival analysis, the transformation model is one of the frequently used models. However, methods of analyzing the transformation model with those complex features have not been fully explored. In this paper, we study this important problem and develop a valid inference method under the transformation model. We establish asymptotic results for the proposed estimators. The proposed method enjoys appealing features in that there is no need to specify the distribution of the covariates and the increasing function in the transformation model. Numerical studies are reported to assess the performance of the proposed method.
Optimal Margin Distribution Network
Recent research about margin theory has proved that maximizing the minimum margin like support vector machines does not necessarily lead to better performance, and instead, it is crucial to optimize the margin distribution. In the meantime, margin theory has been used to explain the empirical success of deep network in recent studies. In this paper, we present mdNet (the Optimal Margin Distribution Network), a network which embeds a loss function in regard to the optimal margin distribution. We give a theoretical analysis of our method using the PAC-Bayesian framework, which confirms the significance of the margin distribution for classification within the framework of deep networks. In addition, empirical results show that the mdNet model always outperforms the baseline cross-entropy loss model consistently across different regularization situations. And our mdNet model also outperforms the cross-entropy loss (Xent), hinge loss and soft hinge loss model in generalization task through limited training data.
Like this:
Like Loading…
Related