Uncertainty Quantification for Kernel Methods

Artificial neural networks condensation: A strategy to facilitate adaption of machine learning in medical settings by reducing computational burden
Machine Learning (ML) applications on healthcare can have a great impact on people’s lives helping deliver better and timely treatment to those in need. At the same time, medical data is usually big and sparse requiring important computational resources. Although it might not be a problem for wide-adoption of ML tools in developed nations, availability of computational resource can very well be limited in third-world nations. This can prevent the less favored people from benefiting of the advancement in ML applications for healthcare. In this project we explored methods to increase computational efficiency of ML algorithms, in particular Artificial Neural Nets (NN), while not compromising the accuracy of the predicted results. We used in-hospital mortality prediction as our case analysis based on the MIMIC III publicly available dataset. We explored three methods on two different NN architectures. We reduced the size of recurrent neural net (RNN) and dense neural net (DNN) by applying pruning of ‘unused’ neurons. Additionally, we modified the RNN structure by adding a hidden-layer to the LSTM cell allowing to use less recurrent layers for the model. Finally, we implemented quantization on DNN forcing the weights to be 8-bits instead of 32-bits. We found that all our methods increased computational efficiency without compromising accuracy and some of them even achieved higher accuracy than the pre-condensed baseline models.
The common patterns of abundance: the log series and Zipf’s law
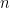




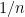
Multi-modal Learning with Prior Visual Relation Reasoning
Visual relation reasoning is a central component in recent cross-modal analysis tasks, which aims at reasoning about the visual relationships between objects and their properties. These relationships convey rich semantics and help to enhance the visual representation for improving cross-modal analysis. Previous works have succeeded in designing strategies for modeling latent relations or rigid-categorized relations and achieving the lift of performance. However, this kind of methods leave out the ambiguity inherent in the relations because of the diverse relational semantics of different visual appearances. In this work, we explore to model relations by contextual-sensitive embeddings based on human priori knowledge. We novelly propose a plug-and-play relation reasoning module injected with the relation embeddings to enhance image encoder. Specifically, we design upgraded Graph Convolutional Networks (GCN) to utilize the information of relation embeddings and relation directionality between objects for generating relation-aware image representations. We demonstrate the effectiveness of the relation reasoning module by applying it to both Visual Question Answering (VQA) and Cross-Modal Information Retrieval (CMIR) tasks. Extensive experiments are conducted on VQA 2.0 and CMPlaces datasets and superior performance is reported when comparing with state-of-the-art work.
Training Deep Capsule Networks
The capsules of Capsule Networks are collections of neurons that represent an object or part of an object in a parse tree. The output vector of a capsule encodes the so called instantiation parameters of this object (e.g. position, size, or orientation). The routing-by-agreement algorithm routes output vectors from lower level capsules to upper level capsules. This iterative algorithm selects the most appropriate parent capsule so that the active capsules in the network represent nodes in a parse tree. This parse tree represents the hierarchical composition of objects out of smaller and smaller components. In this paper, we will show experimentally that the routing-by-agreement algorithm does not ensure the emergence of a parse tree in the network. To ensure that all active capsules form a parse tree, we introduce a new routing algorithm called dynamic deep routing. We show that this routing algorithm allows the training of deeper capsule networks and is also more robust to white box adversarial attacks than the original routing algorithm.
Leveraging Class Similarity to Improve Deep Neural Network Robustness
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross-entropy between a provided groundtruth delta distribution (encoded as one-hot vector) and the ANN’s predictive softmax distribution. It seems, however, unacceptable to penalize networks equally for missclassification between classes. Confusing the class ‘Automobile’ with the class ‘Truck’ should be penalized less than confusing the class ‘Automobile’ with the class ‘Donkey’. To avoid such representation issues and learn cleaner classification boundaries in the network, this paper presents a variation of cross-entropy loss which depends not only on the sample class but also on a data-driven prior ‘class-similarity distribution’ across the classes encoded in a matrix form. We explore learning the class-similarity distribution using a datadriven method and then show that by training with our modified similarity-driven loss, we obtain slightly better generalization performance over multiple architectures and datasets as well as improved performance on noisy testing scenarios.
Let Me Not Lie: Learning MultiNomial Logit
Discrete choice models generally assume that model specification is known a priori. In practice, determining the utility specification for a particular application remains a difficult task and model misspecification may lead to biased parameter estimates. In this paper, we propose a new mathematical framework for estimating choice models in which the systematic part of the utility specification is divided into an interpretable part and a learning representation part that aims at automatically discovering a good utility specification from available data. We show the effectiveness of our framework by augmenting the utility specification of the Multinomial Logit Model (MNL) with a new non-linear representation arising from a Neural Network (NN). This leads to a new choice model referred to as the Learning Multinomial Logit (L-MNL) model. Our experiments show that our L-MNL model outperformed the traditional MNL models and existing hybrid neural network models both in terms of predictive performance and accuracy in parameter estimation.
Neural Persistence: A Complexity Measure for Deep Neural Networks Using Algebraic Topology
While many approaches to make neural networks more fathomable have been proposed, they are restricted to interrogating the network with input data. Measures for characterizing and monitoring structural properties, however, have not been developed. In this work, we propose neural persistence, a complexity measure for neural network architectures based on topological data analysis on weighted stratified graphs. To demonstrate the usefulness of our approach, we show that neural persistence reflects best practices developed in the deep learning community such as dropout and batch normalization. Moreover, we derive a neural persistence-based stopping criterion that shortens the training process while achieving comparable accuracies as early stopping based on validation loss.
A determinantal point process for column subset selection

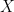

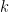
The Online Event-Detection Problem
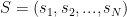
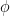
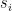

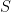
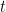
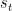
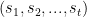
Bayesian Causal Inference


Domain-Aware Generalized Zero-Shot Learning
Generalized zero-shot learning (GZSL) is the problem of learning a classifier where some classes have samples, and others are learned from side information, like semantic attributes or text description, in a zero-shot learning fashion (ZSL). A major challenge in GZSL is to learn consistently for those two different domains. Here we describe a probabilistic approach that breaks the model into three modular components, and then combines them in a consistent way. Specifically, our model consists of three classifiers: A ‘gating’ model that softly decides if a sample is from a ‘seen’ class and two experts: a ZSL expert, and an expert model for seen classes. We address two main difficulties in this approach: How to provide an accurate estimate of the gating probability without any training samples for unseen classes; and how to use an expert predictions when it observes samples outside of its domain. The key insight in our approach is to pass information between the three models to improve each others accuracy, while keeping the modular structure. We test our approach, Domain-Aware GZSL (DAZL) on three standard GZSL benchmark datasets (AWA, CUB, SUN), and find that it largely outperforms state-of-the-art GZSL models. DAZL is also the first model that closes the gap and surpasses the performance of generative models for GZSL, even-though it is a light-weight model that is much easier to train and tune.
Group Preserving Label Embedding for Multi-Label Classification
Multi-label learning is concerned with the classification of data with multiple class labels. This is in contrast to the traditional classification problem where every data instance has a single label. Due to the exponential size of output space, exploiting intrinsic information in feature and label spaces has been the major thrust of research in recent years and use of parametrization and embedding have been the prime focus. Researchers have studied several aspects of embedding which include label embedding, input embedding, dimensionality reduction and feature selection. These approaches differ from one another in their capability to capture other intrinsic properties such as label correlation, local invariance etc. We assume here that the input data form groups and as a result, the label matrix exhibits a sparsity pattern and hence the labels corresponding to objects in the same group have similar sparsity. In this paper, we study the embedding of labels together with the group information with an objective to build an efficient multi-label classification. We assume the existence of a low-dimensional space onto which the feature vectors and label vectors can be embedded. In order to achieve this, we address three sub-problems namely; (1) Identification of groups of labels; (2) Embedding of label vectors to a low rank-space so that the sparsity characteristic of individual groups remains invariant; and (3) Determining a linear mapping that embeds the feature vectors onto the same set of points, as in stage 2, in the low-dimensional space. We compare our method with seven well-known algorithms on twelve benchmark data sets. Our experimental analysis manifests the superiority of our proposed method over state-of-art algorithms for multi-label learning.
Dynamic Runtime Feature Map Pruning
High bandwidth requirements are an obstacle for accelerating the training and inference of deep neural networks. Most previous research focuses on reducing the size of kernel maps for inference. We analyze parameter sparsity of six popular convolutional neural networks – AlexNet, MobileNet, ResNet-50, SqueezeNet, TinyNet, and VGG16. Of the networks considered, those using ReLU (AlexNet, SqueezeNet, VGG16) contain a high percentage of 0-valued parameters and can be statically pruned. Networks with Non-ReLU activation functions in some cases may not contain any 0-valued parameters (ResNet-50, TinyNet). We also investigate runtime feature map usage and find that input feature maps comprise the majority of bandwidth requirements when depth-wise convolution and point-wise convolutions used. We introduce dynamic runtime pruning of feature maps and show that 10% of dynamic feature map execution can be removed without loss of accuracy. We then extend dynamic pruning to allow for values within an epsilon of zero and show a further 5% reduction of feature map loading with a 1% loss of accuracy in top-1.
Dual Principal Component Pursuit: Probability Analysis and Efficient Algorithms

SNAS: Stochastic Neural Architecture Search
We propose Stochastic Neural Architecture Search (SNAS), an economical end-to-end solution to Neural Architecture Search (NAS) that trains neural operation parameters and architecture distribution parameters in same round of back-propagation, while maintaining the completeness and differentiability of the NAS pipeline. In this work, NAS is reformulated as an optimization problem on parameters of a joint distribution for the search space in a cell. To leverage the gradient information in generic differentiable loss for architecture search, a novel search gradient is proposed. We prove that this search gradient optimizes the same objective as reinforcement-learning-based NAS, but assigns credits to structural decisions more efficiently. This credit assignment is further augmented with locally decomposable reward to enforce a resource-efficient constraint. In experiments on CIFAR-10, SNAS takes less epochs to find a cell architecture with state-of-the-art accuracy than non-differentiable evolution-based and reinforcement-learning-based NAS, which is also transferable to ImageNet. It is also shown that child networks of SNAS can maintain the validation accuracy in searching, with which attention-based NAS requires parameter retraining to compete, exhibiting potentials to stride towards efficient NAS on big datasets.
Like this:
Like Loading…
Related