By ActiveWizards

Speech processing is a very popular area of machine learning. There is a significant demand in transforming human speech into text and text into speech. It is especially important regarding the development of self-services in different places: shops, transport, hotels, etc. Machines replace more and more human labor force, and these machines should be able to communicate with us using our language. That’s why speech recognition is a perspective and significant area of artificial intelligence and machine learning.
Today, many large companies provide APIs for performing different machine learning tasks. Speech recognition is not an exception. You don’t have to be the expert in natural language processing to use these APIs. Usually, they provide a convenient interface. All you need to do is to send an HTTP request with required content to the API’s server. Then you will receive the response with completed tasks. This approach is useful when you don’t need something special. In other words, if your problem is standard and well-known. The one more advantage of this way is that you can save such valuable resources as time and money.
Nevertheless, there are many situations where you cannot use API and need to develop speech recognition system from scratch. This way is rather complex, it requires many efforts and resources, but as a result, you can create a system that will be ideally compatible with your needs. Also, it is possible to improve the quality of the results if you build the algorithms by yourself. Anyway, it is good to know about APIs. You can understand what each API can do, what pros and cons they have and so on. So, you will be able to detect, when you should use API (and what API) and when you should think about your own system. In this article, we want to compare the most popular APIs which can work with human speech.
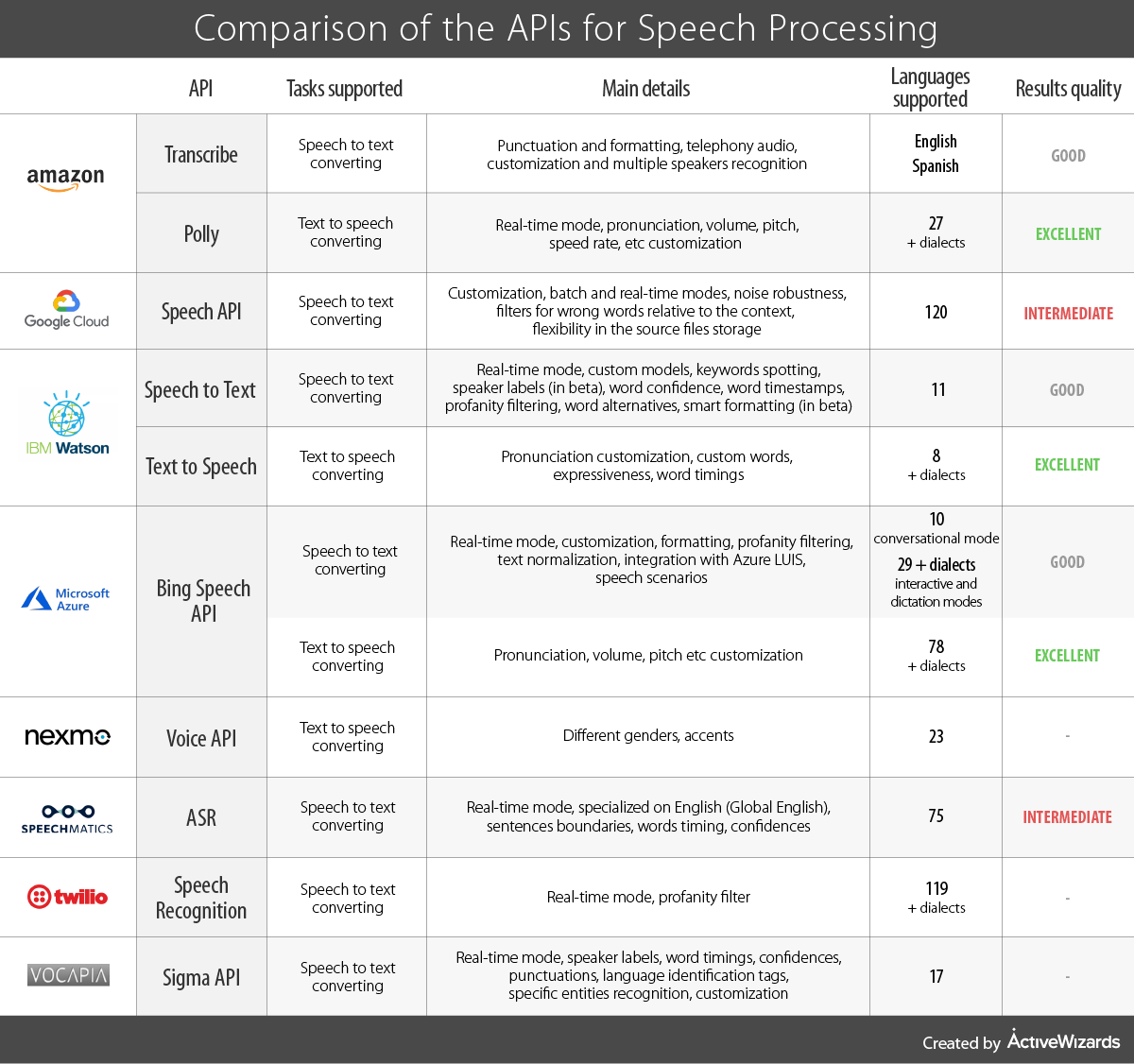
There are two main tasks in speech processing. First one is to transform speech to text. The second is to convert the text into human speech. Here is a list of some popular APIs for speech processing:
Google Cloud Speech API IBM Watson Speech to Text IBM Watson Text to Speech Microsoft Azure Bing Speech API Amazon Transcribe Amazon Polly
There are some other less-known products which can work with speech:
VoxSigma API Twilio Speech Recognition Speechmatics ASR Nexmo Voice API
We will describe the general aspects of each API and then compare their main features in the table.
Google Cloud Speech API
Google Cloud Speech API is a part of Google Cloud infrastructure. It allows converting human speech into text. This API supports more than 110 languages. The system supports customization in the form of providing the list of possible words to be recognized (this thing is especially useful if you want to use speech recognition in some devices or other situations where the list of possible words is limited). API can work both in batch and real-time modes. It is stable against side noises in the audio. For some languages the filter for inappropriate words is available. The system is built using deep neural networks and can be improved over time. The files you want to process can be directly fed to the API or be stored on the Google Cloud Storage.
The price is flexible. Up to 60 minutes of the processed audio is free for each user. If you want to process more than 60 minutes, you should pay 0.006 USD per 15 seconds. It is interesting that the total monthly capacity is limited to 1 million minutes of audio.
IBM Watson Speech to Text
IBM Watson Speech to Text is a service provided by IBM Watson that can convert human speech into text. IBM Watson supports customization not only for specific words dictionary but also for the particular acoustic condition. So, you can adapt the system to the environment where you are planning to use it. The main flaw of the IBM Watson Speech to Text is the very small amount of supported languages. Furthermore, the custom models are available for even fewer number of languages. At the moment, such functions as keywords spotting and labeling of speakers are available in beta version. When they are merged with the master version, this allows identifying different speakers for English, Spanish and Japanese languages. Keywords spotting allows detecting the user-defined strings directly from the speech. Other useful functions available in the IBM Watson Speech to Text are word alternatives (in beta), word confidence, word timestamps, profanity filtering, smart formatting for phone numbers, dates, currency, etc. (in beta). You can become familiar with the supported audio file formats in the documentation.
There are three levels of access to the service. The standard level provides free access for the first 1000 minutes of processed audio per month. Then, the flexible per minute prices are used. They depend on the number of minutes you want to process (Graduated Tiered Pricing). If you’re going to use customization models, you will have to pay 0.03 USD in addition to the Standard level prices. To use Premium level, you should contact the IBM to agree on the details.
IBM Watson Text to Speech
Similarly to the speech-to-text task, IBM Watson provides a service for performing text-to-speech task. IBM Watson Text to Speech tool fits this task perfectly well.
The system produces high-quality audio files from the input texts. It can recognize some abbreviations and numbers. For example, it can pronounce “United States Dollars” when it meets “USD” abbreviation in the text. The API can detect the tone of the sentence (question, for example). You can choose the expressiveness of the voice (GoodNews, Apology, Uncertainty). Also, there are available such voices as Young, Soft, Male, Female. However, expressiveness and different types of voices are currently available only for English language. Word timing feature allows synchronizing the text streaming and the voice accompanying. The service can produce audio files with different formats. You can read more about supported formats in the documentation.
Pricing depends on the level of usage. If you want Premium level, you should contact IBM to agree on the details of the price and usage. If using Standard level is sufficient, the conditions are as follows. First 1 million characters of processed text per month are free. If you need to process more characters, you will need to pay 0.02 USD per 1000 characters. All languages and voices are available in the Standard level.
Microsoft Azure Bing Speech API
Microsoft Azure Bing Speech API is a component of the Microsoft Azure cloud services allowing to solve two tasks simultaneously: speech-to-text converting as well as text-to-speech converting.The speech-to-text task in Azure Bing Speech API allows real-time processing, customization, text formatting, profanity filtering, text normalization. It also supports different scenarios (conditions of speaking) like interactive, conversation or dictation. Integration with the Azure LUIS is available. Azure LUIS allows extracting intent from the text as well as main entities.
Text-to-speech feature allows tuning of different voice parameters: gender, volume, pitch, pronunciation, speaking rate, prosody contour. The system can detect and process some words in a specific manner. For example, it can recognize the money amount expressed in floating point number and convert this to the words where “cents” are present.
It is free to use this API if you want to perform up to 5000 transactions per month. If you need more, you should pay 4 USD for every 1000 transactions.
Amazon Transcribe
Amazon Transcribe is a part of the Amazon Web Services infrastructure. You can analyze your audio documents stored in the Amazon S3 service and get the text made from the audio.
Amazon Transcribe can add punctuation and text-formatting. Another valuable function provided by this service is the support for telephony audio. It is because the audio from the phone conversations often has low quality. So, the developers of Amazon Transcribe considered, that they have to process this type of audio in a specific way. The system adds timestamps for each word in the text. So, you will be able to match each word in the text to the corresponding place in the audio file. It is expected that the API will be able to recognize multiple speakers and label their voices in the text soon. Creating custom words also should be available in a short time. Users will be able to explicitly add, for example, names of their products, or some other specific words.
There is a Free Tier in pricing: you can use the service for free during the first 12 months after registration (max 60 minutes of audio per month). After this period, you will need to pay 0.0004 USD per second of processed audio.
Amazon Polly
Amazon Polly is a service that allows text-to-speech conversion both in batch and real-time modes. It is also a part of the Amazon Web Services infrastructure.
Amazon Polly not only converts text to speech but also allows to tune some speech parameters. For example, you can set up different voices (gender), volume, pronunciation, the speed of the speech, pitch and some others properties.
Pricing is flexible. The Free Tier is available during the first 12 months, but you will be able to process not more than 5 million characters per month. The Pay-As-You-Go model is an alternative. You will have to pay 4 USD per 1 million characters processed.
VoxSigma API
VoxSigma API for speech to text converting is a product of Vocapia Research company. This company is specialized in the area of speech and language technology. VoxSigma API can not only convert the input speech into text but also perform language identification and speech-text alignment. Other interesting features of the API is that it can add punctuation to the output text, compute the confidence score for the output. Also, VoxSigma API can process numerical and some other entities (like, for example, currencies) in a unique way. It is possible to customize the available language model, but for this purpose you have to contact the company and talk with them directly.
The company proposes several usage plans. The most popular method is pay-as-you-go. According to this plan, you will have to pay 0.01 USD (or EUR) per minute. It is interesting that they take into account only the places on the input audio where some speech is present. In other words, if your input audio has some silent places, the duration of these places will be deducted while computing the total cost. The free trial period is also available, but for this purpose you need to contact the company directly.
Twilio Speech Recognition
Twilio Speech Recognition is available as a component of the Twilio Flex platform. This is an API for contact centers with full-stack programmability. Maybe due to the fact that this is not a standalone application Twilio Speech Recognition proposes not so many features as some others speech recognition APIs. It provides real-time mode and profanity filtering. Thus, for example, some words from the obscene language can be detected, and asterisks will replace all but the first character. It really can be useful when used by the contact centers.
The service can be used on pay-as-you-go conditions. You will need to pay 0.02 USD per 15 seconds of processed audio.
Speechmatics ASR
Speechmatics ASR is a set of several services providing both batch and real-time modes for converting speech to text. They are specialized in English enabling recognition of different dialects of English all over the world. Nevertheless, many other languages are also available. Other useful features available in Speechmatics ASR are confidences scores and timing information for each word in the transcription, as well as providing information about sentences boundaries.
The price for using cloud services is 0.06 GBP per 1 minute of processed audio. If you buy more than 1000 GBP, you can get the discount and pay 0.05 GBP per minute.
Nexmo Voice API
Nexmo Voice API is not a standalone API. You can use it for calling. For example, if you want to call someone, you can use Nexmo Voice API to convert text to speech. Nexmo is the company that provides services for programmable communication. The set of available features is not very rich. It includes only the possibility to change the gender of voice (male or female) as well as to change the accent of the speech.
The prices depend on the country to which you want to make a call, and also depends on whether is it the mobile or landline phone. Pricing is carried out on a per-minute basis.
Now, we will compare the main features of these APIs for each task, so you can choose something that is compatible with your needs.
Conclusion
In this article, we have analyzed the key characteristics of different APIs performing text-to-speech and speech-to-text tasks. Using these modern technologies communication becomes much more natural and productive.
To facilitate the process of selecting the API that would perfectly meet your needs we have completed a table highlighting the crucial features of such APIs. Based on our experience, all these APIs proved its efficiency under various conditions. Hopefully, the results of our field research will be helpful for you and will save your time.
ActiveWizards is a team of data scientists and engineers, focused exclusively on data projects (big data, data science, machine learning, data visualizations). Areas of core expertise include data science (research, machine learning algorithms, visualizations and engineering), data visualizations ( d3.js, Tableau and other), big data engineering (Hadoop, Spark, Kafka, Cassandra, HBase, MongoDB and other), and data intensive web applications development (RESTful APIs, Flask, Django, Meteor).
Original. Reposted with permission.
Related: