Distill-Net: Application-Specific Distillation of Deep Convolutional Neural Networks for Resource-Constrained IoT Platforms
Many Internet-of-Things (IoT) applications demand fast and accurate understanding of a few key events in their surrounding environment. Deep Convolutional Neural Networks (CNNs) have emerged as an effective approach to understand speech, images, and similar high dimensional data types. Algorithmic performance of modern CNNs, however, fundamentally relies on learning class-agnostic hierarchical features that only exist in comprehensive training datasets with many classes. As a result, fast inference using CNNs trained on such datasets is prohibitive for most resource-constrained IoT platforms. To bridge this gap, we present a principled and practical methodology for distilling a complex modern CNN that is trained to effectively recognize many different classes of input data into an application-dependent essential core that not only recognizes the few classes of interest to the application accurately, but also runs efficiently on platforms with limited resources. Experimental results confirm that our approach strikes a favorable balance between classification accuracy (application constraint), inference efficiency (platform constraint), and productive development of new applications (business constraint).
Digital Neuron: A Hardware Inference Accelerator for Convolutional Deep Neural Networks
We propose a Digital Neuron, a hardware inference accelerator for convolutional deep neural networks with integer inputs and integer weights for embedded systems. The main idea to reduce circuit area and power consumption is manipulating dot products between input feature and weight vectors by Barrel shifters and parallel adders. The reduced area allows the more computational engines to be mounted on an inference accelerator, resulting in high throughput compared to prior HW accelerators. We verified that the multiplication of integer numbers with 3-partial sub-integers does not cause significant loss of inference accuracy compared to 32-bit floating point calculation. The proposed digital neuron can perform 800 MAC operations in one clock for computation for convolution as well as full-connection. This paper provides a scheme that reuses input, weight, and output of all layers to reduce DRAM access. In addition, this paper proposes a configurable architecture that can provide inference of adaptable feature of convolutional neural networks. The throughput in terms of Watt of the digital neuron is achieved 754.7 GMACs/W.
Analogy Search Engine: Finding Analogies in Cross-Domain Research Papers
In recent years, with the rapid proliferation of research publications in the field of Artificial Intelligence, it is becoming increasingly difficult for researchers to effectively keep up with all the latest research in one’s own domains. However, history has shown that scientific breakthroughs often come from collaborations of researchers from different domains. Traditional search algorithms like Lexical search, which look for literal matches or synonyms and variants of the query words, are not effective for discovering cross-domain research papers and meeting the needs of researchers in this age of information overflow. In this paper, we developed and tested an innovative semantic search engine, Analogy Search Engine (ASE), for 2000 AI research paper abstracts across domains like Language Technologies, Robotics, Machine Learning, Computational Biology, Human Computer Interactions, etc. ASE combines recent theories and methods from Computational Analogy and Natural Language Processing to go beyond keyword-based lexical search and discover the deeper analogical relationships among research paper abstracts. We experimentally show that ASE is capable of finding more interesting and useful research papers than baseline elasticsearch. Furthermore, we believe that the methods used in ASE go beyond academic paper and will benefit many other document search tasks.
Multi Instance Learning For Unbalanced Data
In the context of Multi Instance Learning, we analyze the Single Instance (SI) learning objective. We show that when the data is unbalanced and the family of classifiers is sufficiently rich, the SI method is a useful learning algorithm. In particular, we show that larger data imbalance, a quality that is typically perceived as negative, in fact implies a better resilience of the algorithm to the statistical dependencies of the objects in bags. In addition, our results shed new light on some known issues with the SI method in the setting of linear classifiers, and we show that these issues are significantly less likely to occur in the setting of neural networks. We demonstrate our results on a synthetic dataset, and on the COCO dataset for the problem of patch classification with weak image level labels derived from captions.
Malthusian Reinforcement Learning
Here we explore a new algorithmic framework for multi-agent reinforcement learning, called Malthusian reinforcement learning, which extends self-play to include fitness-linked population size dynamics that drive ongoing innovation. In Malthusian RL, increases in a subpopulation’s average return drive subsequent increases in its size, just as Thomas Malthus argued in 1798 was the relationship between preindustrial income levels and population growth. Malthusian reinforcement learning harnesses the competitive pressures arising from growing and shrinking population size to drive agents to explore regions of state and policy spaces that they could not otherwise reach. Furthermore, in environments where there are potential gains from specialization and division of labor, we show that Malthusian reinforcement learning is better positioned to take advantage of such synergies than algorithms based on self-play.
Optimizing Organizations for Navigating Data Lakes
Navigation is known to be an effective complement to search. In addition to data discovery, navigation can help users develop a conceptual model of what types of data are available. In data lakes, there has been considerable research on dataset or table discovery using search. We consider the complementary problem of creating an effective navigation structure over a data lake. We define an organization as a navigation structure (graph) containing nodes representing sets of attributes (from tables or from semi-structured documents) within a data lake. An edge represents a subset relationship. We propose a novel problem, the data lake organization problem where the goal is to find an organization that allows a user to most efficiently find attributes or tables. We present a new probabilistic model of how users interact with an organization and define the likelihood of a user finding an attribute or a table using the organization. Our approach uses the attribute values and metadata (when available). For data lakes with little or no metadata, we propose a way of creating metadata using metadata available in other lakes. We propose an approximate algorithm for the organization problem and show its effectiveness on a synthetic benchmark. Finally, we construct an organization on tables of a real data lake containing data from federal Open Data portals and show that the organization dramatically improves the expected probability of discovering tables over a baseline. Using a second real data lake with no metadata, we show how metadata can be inferred that is effective in enabling organization creation.
Fuzzy Hashing as Perturbation-Consistent Adversarial Kernel Embedding
Measuring the similarity of two files is an important task in malware analysis, with fuzzy hash functions being a popular approach. Traditional fuzzy hash functions are data agnostic: they do not learn from a particular dataset how to determine similarity; their behavior is fixed across all datasets. In this paper, we demonstrate that fuzzy hash functions can be learned in a novel minimax training framework and that these learned fuzzy hash functions outperform traditional fuzzy hash functions at the file similarity task for Portable Executable files. In our approach, hash digests can be extracted from the kernel embeddings of two kernel networks, trained in a minimax framework, where the roles of players during training (i.e adversary versus generator) alternate along with the input data. We refer to this new minimax architecture as perturbation-consistent. The similarity score for a pair of files is the utility of the minimax game in equilibrium. Our experiments show that learned fuzzy hash functions generalize well, capable of determining that two files are similar even when one of those files was generated using insertion and deletion operations.
Learning Private Neural Language Modeling with Attentive Aggregation
Mobile keyboard suggestion is typically regarded as a word-level language modeling problem. Centralized machine learning technique requires massive user data collected to train on, which may impose privacy concerns for sensitive personal typing data of users. Federated learning (FL) provides a promising approach to learning private language modeling for intelligent personalized keyboard suggestion by training models in distributed clients rather than training in a central server. To obtain a global model for prediction, existing FL algorithms simply average the client models and ignore the importance of each client during model aggregation. Furthermore, there is no optimization for learning a well-generalized global model on the central server. To solve these problems, we propose a novel model aggregation with the attention mechanism considering the contribution of clients models to the global model, together with an optimization technique during server aggregation. Our proposed attentive aggregation method minimizes the weighted distance between the server model and client models through iterative parameters updating while attends the distance between the server model and client models. Through experiments on two popular language modeling datasets and a social media dataset, our proposed method outperforms its counterparts in terms of perplexity and communication cost in most settings of comparison.
Globalness Detection in Online Social Network
Classification problems have made significant progress due to the maturity of artificial intelligence (AI). However, differentiating items from categories without noticeable boundaries is still a huge challenge for machines — which is also crucial for machines to be intelligent. In order to study the fuzzy concept on classification, we define and propose a globalness detection with the four-stage operational flow. We then demonstrate our framework on Facebook public pages inter-like graph with their geo-location. Our prediction algorithm achieves high precision (89%) and recall (88%) of local pages. We evaluate the results on both states and countries level, finding that the global node ratios are relatively high in those states (NY, CA) having large and international cities. Several global nodes examples have also been shown and studied in this paper. It is our hope that our results unveil the perfect value from every classification problem and provide a better understanding of global and local nodes in Online Social Networks (OSNs).
Anomaly Detection and Interpretation using Multimodal Autoencoder and Sparse Optimization
Automated anomaly detection is essential for managing information and communications technology (ICT) systems to maintain reliable services with minimum burden on operators. For detecting varying and continually emerging anomalies as differences from normal states, learning normal relationships inherent among cross-domain data monitored from ICT systems is essential. Deep-learning-based anomaly detection using an autoencoder (AE) is therefore promising for such complicated learning; however, its interpretation is still problematic. Since the dimensions of the input data contributing to the detected anomaly are not directly indicated in an AE, they are not suitable for localizing anomalies in large ICT systems composed of a huge amount of equipment. We propose an algorithm using sparse optimization for estimating contributing dimensions to anomalies detected with AEs. We also propose a multimodal AE (MAE) for effectively learning the relationships among cross-domain data, which can induce nonlinearity and differences in learnability among data types. We evaluated our algorithms with several datasets including real measured data in comparison with conventional algorithms and confirmed the superiority of our estimation algorithm in specifying contributing dimensions of anomalous data and our MAE in detecting anomalies in cross-domain data.
Interactive Naming for Explaining Deep Neural Networks: A Formative Study
We consider the problem of explaining the decisions of deep neural networks for image recognition in terms of human-recognizable visual concepts. In particular, given a test set of images, we aim to explain each classification in terms of a small number of image regions, or activation maps, which have been associated with semantic concepts by a human annotator. This allows for generating summary views of the typical reasons for classifications, which can help build trust in a classifier and/or identify example types for which the classifier may not be trusted. For this purpose, we developed a user interface for ‘interactive naming,’ which allows a human annotator to manually cluster significant activation maps in a test set into meaningful groups called ‘visual concepts’. The main contribution of this paper is a systematic study of the visual concepts produced by five human annotators using the interactive naming interface. In particular, we consider the adequacy of the concepts for explaining the classification of test-set images, correspondence of the concepts to activations of individual neurons, and the inter-annotator agreement of visual concepts. We find that a large fraction of the activation maps have recognizable visual concepts, and that there is significant agreement between the different annotators about their denotations. Our work is an exploratory study of the interplay between machine learning and human recognition mediated by visualizations of the results of learning.
MatRox: A Model-Based Algorithm with an Efficient Storage Format for Parallel HSS-Structured Matrix Approximations
We present MatRox, a novel model-based algorithm and implementation of Hierarchically Semi-Separable (HSS) matrix computations on parallel architectures. MatRox uses a novel storage format to improve data locality and scalability of HSS matrix-matrix multiplications on shared memory multicore processors. We build a performance model for HSS matrix-matrix multiplications. Based on the performance model, a mixed-rank heuristic is introduced to find an optimal HSS-tree depth for a faster HSS matrix evaluation. Uniform sampling is used to improve the performance of HSS compression. MatRox outperforms state-of-the-art HSS matrix multiplication codes, GOFMM and STRUMPACK, with average speedups of 2.8x and 6.1x respectively on target multicore processors.
Explaining Neural Networks Semantically and Quantitatively
This paper presents a method to explain the knowledge encoded in a convolutional neural network (CNN) quantitatively and semantically. The analysis of the specific rationale of each prediction made by the CNN presents a key issue of understanding neural networks, but it is also of significant practical values in certain applications. In this study, we propose to distill knowledge from the CNN into an explainable additive model, so that we can use the explainable model to provide a quantitative explanation for the CNN prediction. We analyze the typical bias-interpreting problem of the explainable model and develop prior losses to guide the learning of the explainable additive model. Experimental results have demonstrated the effectiveness of our method.
Toward Multimodal Model-Agnostic Meta-Learning
Gradient-based meta-learners such as MAML are able to learn a meta-prior from similar tasks to adapt to novel tasks from the same distribution with few gradient updates. One important limitation of such frameworks is that they seek a common initialization shared across the entire task distribution, substantially limiting the diversity of the task distributions that they are able to learn from. In this paper, we augment MAML with the capability to identify tasks sampled from a multimodal task distribution and adapt quickly through gradient updates. Specifically, we propose a multimodal MAML algorithm that is able to modulate its meta-learned prior according to the identified task, allowing faster adaptation. We evaluate the proposed model on a diverse set of problems including regression, few-shot image classification, and reinforcement learning. The results demonstrate the effectiveness of our model in modulating the meta-learned prior in response to the characteristics of tasks sampled from a multimodal distribution.
Robust functional ANOVA model with t-process
Robust estimation approaches are of fundamental importance for statistical modelling. To reduce susceptibility to outliers, we propose a robust estimation procedure with t-process under functional ANOVA model. Besides common mean structure of the studied subjects, their personal characters are also informative, especially for prediction. We develop a prediction method to predict the individual effect. Statistical properties, such as robustness and information consistency, are studied. Numerical studies including simulation and real data examples show that the proposed method performs well.
Optimizing Data Intensive Flows for Networks on Chips
Data flow analysis and optimization is considered for homogeneous rectangular mesh networks. We propose a flow matrix equation which allows a closed-form characterization of the nature of the minimal time solution, speedup and a simple method to determine when and how much load to distribute to processors. We also propose a rigorous mathematical proof about the flow matrix optimal solution existence and that the solution is unique. The methodology introduced here is applicable to many interconnection networks and switching protocols (as an example we examine toroidal networks and hypercube networks in this paper). An important application is improving chip area and chip scalability for networks on chips processing divisible style loads.
Interpretable Optimal Stopping
Optimal stopping is the problem of deciding when to stop a stochastic system to obtain the greatest reward, arising in numerous application areas such as finance, healthcare and marketing. State-of-the-art methods for high-dimensional optimal stopping involve approximating the value function or the continuation value, and then using that approximation within a greedy policy. Although such policies can perform very well, they are generally not guaranteed to be interpretable; that is, a decision maker may not be able to easily see the link between the current system state and the policy’s action. In this paper, we propose a new approach to optimal stopping, wherein the policy is represented as a binary tree, in the spirit of naturally interpretable tree models commonly used in machine learning. We formulate the problem of learning such policies from observed trajectories of the stochastic system as a sample average approximation (SAA) problem. We prove that the SAA problem converges under mild conditions as the sample size increases, but that computationally even immediate simplifications of the SAA problem are theoretically intractable. We thus propose a tractable heuristic for approximately solving the SAA problem, by greedily constructing the tree from the top down. We demonstrate the value of our approach by applying it to the canonical problem of option pricing, using both synthetic instances and instances calibrated with real S&P 500 data. Our method obtains policies that (1) outperform state-of-the-art non-interpretable methods, based on simulation-regression and martingale duality, and (2) possess a remarkably simple and intuitive structure.
Efficient Global Optimal Resource Allocation in Non-Orthogonal Interference Networks
Many resource allocation tasks are challenging global (i.e., non-convex) optimization problems. The main issue is that the computational complexity of these problems grows exponentially in the number of variables instead of polynomially as for convex optimization problems. However, often the non-convexity stems only from a subset of variables. Conventional global optimization frameworks like monotonic optimization or DC programming treat all variables as global variables and require complicated, problem specific decomposition approaches to exploit the convexity in some variables. To overcome this challenge, we develop an easy-to-use algorithm that inherently differentiates between convex and non-convex variables, preserving the polynomial complexity in the number of convex variables. Another issue with these widely used frameworks is that they may suffer from severe numerical problems. We discuss this issue in detail and provide a clear motivating example.The solution to this problem is to replace the traditional approach of finding an {\epsilon}-approximate solution by the novel concept of {\epsilon}-essential feasibility. The underlying algorithmic approach is called successive incumbent transcending (SIT) algorithm and builds the foundation of our developed algorithm. A further highlight of our algorithm is that it inherently treats fractional objectives making the use of Dinkelbach’s iterative algorithm obsolete. Numerical experiments show a speed-up of five orders of magnitude over state-of-the-art algorithms and almost four orders of magnitude of additional speed-up over Dinkelbach’s algorithm for fractional programs.
A new time-varying model for forecasting long-memory series
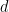
A residual for outlier identification in zero adjusted regression models
Zero adjusted regression models are used to fit variables that are discrete at zero and continuous at some interval of the positive real numbers. Diagnostic analysis in these models is usually performed using the randomized quantile residual, which is useful for checking the overall adequacy of a zero adjusted regression model. However, it may fail to identify some outliers. In this work, we introduce a residual for outlier identification in zero adjusted regression models. Monte Carlo simulation studies and an application suggest that the residual introduced here has good properties and detects outliers that are not identified by the randomized quantile residual.
Multi-objective Evolutionary Federated Learning
Federated learning is an emerging technique used to prevent the leakage of private information. Unlike centralized learning that needs to collect data from users and store them collectively on a cloud server, federated learning makes it possible to learn a global model while the data are distributed on the users’ devices. However, compared with the traditional centralized approach, the federated setting consumes considerable communication resources of the clients, which is indispensable for updating global models and prevents this technique from being widely used. In this paper, we aim to optimize the structure of the neural network models in federated learning using a multi-objective evolutionary algorithm to simultaneously minimize the communication costs and the global model test errors. A scalable method for encoding network connectivity is adapted to federated learning to enhance the efficiency in evolving deep neural networks. Experimental results on both multilayer perceptrons and convolutional neural networks indicate that the proposed optimization method is able to find optimized neural network models that can not only significantly reduce communication costs but also improve the learning performance of federated learning compared with the standard fully connected neural networks.
NIPS – Not Even Wrong? A Systematic Review of Empirically Complete Demonstrations of Algorithmic Effectiveness in the Machine Learning and Artificial Intelligence Literature
Objective: To determine the completeness of argumentative steps necessary to conclude effectiveness of an algorithm in a sample of current ML/AI supervised learning literature. Data Sources: Papers published in the Neural Information Processing Systems (NeurIPS, n\’ee NIPS) journal where the official record showed a 2017 year of publication. Eligibility Criteria: Studies reporting a (semi-)supervised model, or pre-processing fused with (semi-)supervised models for tabular data. Study Appraisal: Three reviewers applied the assessment criteria to determine argumentative completeness. The criteria were split into three groups, including: experiments (e.g real and/or synthetic data), baselines (e.g uninformed and/or state-of-art) and quantitative comparison (e.g. performance quantifiers with confidence intervals and formal comparison of the algorithm against baselines). Results: Of the 121 eligible manuscripts (from the sample of 679 abstracts), 99\% used real-world data and 29\% used synthetic data. 91\% of manuscripts did not report an uninformed baseline and 55\% reported a state-of-art baseline. 32\% reported confidence intervals for performance but none provided references or exposition for how these were calculated. 3\% reported formal comparisons. Limitations: The use of one journal as the primary information source may not be representative of all ML/AI literature. However, the NeurIPS conference is recognised to be amongst the top tier concerning ML/AI studies, so it is reasonable to consider its corpus to be representative of high-quality research. Conclusion: Using the 2017 sample of the NeurIPS supervised learning corpus as an indicator for the quality and trustworthiness of current ML/AI research, it appears that complete argumentative chains in demonstrations of algorithmic effectiveness are rare.
LSM-based Storage Techniques: A Survey
In recent years, Log-Structured Merge-trees (LSM-trees) have been widely adopted for use in the storage layer of modern NoSQL systems. Because of this, there have been a large number of research efforts, from both the database community and the systems community, that try to improve various aspects of LSM-trees. In this paper, we provide a survey of recent LSM efforts so that readers can learn the state of the art in LSM-based storage techniques. We provide a general taxonomy to classify the literature of LSM improvements, survey the efforts in detail, and discuss their strengths and trade-offs. We further survey several representative LSM-based open-source NoSQL systems and we discuss some potential future research directions resulting from the survey.
Information-Directed Exploration for Deep Reinforcement Learning
Efficient exploration remains a major challenge for reinforcement learning. One reason is that the variability of the returns often depends on the current state and action, and is therefore heteroscedastic. Classical exploration strategies such as upper confidence bound algorithms and Thompson sampling fail to appropriately account for heteroscedasticity, even in the bandit setting. Motivated by recent findings that address this issue in bandits, we propose to use Information-Directed Sampling (IDS) for exploration in reinforcement learning. As our main contribution, we build on recent advances in distributional reinforcement learning and propose a novel, tractable approximation of IDS for deep Q-learning. The resulting exploration strategy explicitly accounts for both parametric uncertainty and heteroscedastic observation noise. We evaluate our method on Atari games and demonstrate a significant improvement over alternative approaches.
Like this:
Like Loading…
Related