Data scientists and developers can now easily train machine learning models on datasets labeled by Amazon SageMaker Ground Truth. Amazon SageMaker Training now accepts the labeled datasets produced in augmented manifest format as input through both AWS Management Console and Amazon SageMaker Python SDK APIs.
Last month during AWS re:Invent, we launched Amazon SageMaker Ground Truth to build highly accurate training datasets with up to 70 percent savings in labeling costs by using machine learning to aid public as well as private workforces of human labelers. The labeled datasets are produced in augmented manifest file format that augments each input dataset object with additional metadata – such as labels – inline in the file. Earlier you could use only the low-level AWS SDK APIs to train models on augmented datasets. Starting today, you can now quickly and easily perform such training with few quick clicks in the Amazon SageMaker console or one-line API calls using the high-level Amazon SageMaker Python SDK.
Furthermore, the model will be trained using the Amazon SageMaker Pipe Mode, which significantly accelerates the speeds at which data is streamed from Amazon Simple Storage Service (S3) into Amazon SageMaker so that your training job starts sooner, finishes quicker, and needs less disk space, thus reducing your overall cost to train machine learning models on Amazon SageMaker.
Now let’s dive into an example. Our example uses the CBCL StreetScenes dataset consisting of 3548 street images. In an earlier blog post we had shown you an example of how you can use Amazon SageMaker Ground Truth to manage a workforce for drawing bounding boxes around all the cars in the images, thus creating a labeled dataset for training an Amazon SageMaker Object Detection model. Now we’ll show you how to train such a model on Amazon SageMaker.
Step 1: Explore the labeled dataset
The labeled dataset is produced in an augmented manifest file format. An augmented manifest file is a file in JSON Lines format. This means that each line in the file is a complete JSON object followed by a newline separator. Each JSON object contains the Amazon S3 URI of an image file along with its labels. The labels are the coordinates of the bounding boxes around each of the cars in the image. Here is a sample JSON object from the augmented manifest file for an image that was labeled with 4 cars.
 SSDB00004.JPG
SSDB00004.JPG
Here is the JSON object in the augmented manifest file. We have formatted the display for ease of visualization. In the augmented manifest file, this will appear as a JSON object in a single line.
1 | |
Here source-ref is the Amazon S3 URI of the image file. Note that sthakur-groundtruth-demo (named after the Amazon SageMaker Ground Truth labeling job that produced the manifest file in the first place) is the list of labels. The labels consist of the coordinates of the four cars labeled by human labeler.
Step 2: Create the Amazon SageMaker training job
We’ll now train an Amazon SageMaker Object Detection Model which takes the augmented manifest file from Step 1 as an input.
Using the Amazon SageMaker console
Choose Training jobs from the left navigation pane on the Amazon SageMaker console and then choose Create training job.After choosing the model training configurations, such as the learning algorithm, training cluster specs, and hyperparameters, scroll down to the section where you enter the input data channel for sourcing the training dataset.
Choose the S3 data type as AugmentedManifestFile. Provide the Amazon S3 location of the manifest file from Step 1. Also provide the names of the JSON attributes that you want the Object Detection Algorithm to use from the augmented manifest file. Here we need only two attributes for training the model: source-ref and sthakur-groundtruth-demo as described in Step 1.
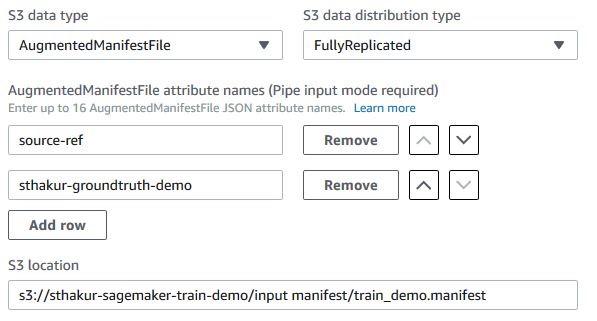
Since the JSON objects from the augmented manifest file are streamed in an ordered fashion using Amazon SageMaker Pipe mode, you need to carefully choose the sequence of attribute names that the algorithm should expect to find in the input data stream. Use the up and down arrow buttons next to each attribute name for choosing the sequence.
While we are showing here how to create an input data channel for sourcing training dataset, the Object Detection algorithm also requires an input data channel for validation dataset. One way to prepare the validation dataset would be to hold out a subset of your labeled images, and create another augmented manifest file for the validation set. You can then use the Amazon S3 URI of the new augmented manifest file as an input to your validation channel, and define the channel in exactly the same manner as described in this step.
Using the Amazon SageMaker Python SDK
We’ll use Amazon SageMaker Estimator to train the Object Detection Model.
1 | |
Note that we’ve chosen the input_mode as Pipe, s3_data_type as AugmentedManifestFile, and specified the attribute_names sequence before training the model using SageMaker estimator’s fit routine.
Additional benefits of using augmented manifest format
Amazon SageMaker has always supported traditional manifest files for training models on datasets stored in Amazon S3. A manifest file simply provides a list of Amazon S3 key name prefixes for the data objects that need to be downloaded to Amazon SageMaker for training the model.
For example, this is a manifest file:
1 | |
Will match the following Amazon S3 URIs:
1 | |
Using this traditional approach for specifying the input data channel for learning algorithms, such as visual recognition algorithms, requires you to specify two input data channels in Amazon SageMaker – one for the input data (images), and other for its labels. Using an augmented manifest, you can now put the data and its labels in one manifest file, thus reducing the need for two channels. It also eliminates any unnecessary complexity in algorithm code for matching data objects with labels across multiple channels.
For example, this manifest file can be easily expressed as an augmented manifest by restructuring the S3 URIs to JSON Lines format, and adding labels inline.
1 | |
Set attribute_names=[‘source-ref’,’label’] while training the model.
In addition, the augmented manifest file uses Amazon SageMaker Pipe mode, which means that your learning algorithm can benefit from the high throughput data streaming from Amazon S3 to your training instances in Amazon SageMaker. Here is a blog post that describes changes you can make to your learning algorithm to start consuming data using Pipe mode.
Get started with more examples and developer support
We’ve shown you examples of how to train models on Amazon SageMaker using labeled datasets in augmented manifest file format. You can also try out our sample notebook that provides the step-by-step AWS SDK experience. You can also see additional examples in our developer guide or post your questions on our developer forum.
About the Author
 Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.**
Sumit Thakur is a Senior Product Manager for AWS Machine Learning Platforms where he loves working on products that make it easy for customers to get started with machine learning on cloud. He is product manager for Amazon SageMaker and AWS Deep Learning AMI. In his spare time, he likes connecting with nature and watching sci-fi TV series.**