Automatic Differentiation in Mixture Models
In this article, we discuss two specific classes of models – Gaussian Mixture Copula models and Mixture of Factor Analyzers – and the advantages of doing inference with gradient descent using automatic differentiation. Gaussian mixture models are a popular class of clustering methods, that offers a principled statistical approach to clustering. However, the underlying assumption, that every mixing component is normally distributed, can often be too rigid for several real life datasets. In order to to relax the assumption about the normality of mixing components, a new class of parametric mixture models that are based on Copula functions – Gaussian Mixuture Copula Models were introduced. Estimating the parameters of the proposed Gaussian Mixture Copula Model (GMCM) through maximum likelihood has been intractable due to the positive semi-positive-definite constraints on the variance-covariance matrices. Previous attempts were limited to maximizing a proxy-likelihood which can be maximized using EM algorithm. These existing methods, even though easier to implement, does not guarantee any convergence nor monotonic increase of the GMCM Likelihood. In this paper, we use automatic differentiation tools to maximize the exact likelihood of GMCM, at the same time avoiding any constraint equations or Lagrange multipliers. We show how our method leads a monotonic increase in likelihood and converges to a (local) optimum value of likelihood. In this paper, we also show how Automatic Differentiation can be used for inference with Mixture of Factor Analyzers and advantages of doing so. We also discuss how this method also has all the properties such as monotonic increase in likelihood and convergence to a local optimum. Note that our work is also applicable to special cases of these two models – for e.g. Simple Copula models, Factor Analyzer model, etc.
Helix: Holistic Optimization for Accelerating Iterative Machine Learning
Machine learning workflow development is a process of trial-and-error: developers iterate on workflows by testing out small modifications until the desired accuracy is achieved. Unfortunately, existing machine learning systems focus narrowly on model training—a small fraction of the overall development time—and neglect to address iterative development. We propose Helix, a machine learning system that optimizes the execution across iterations—intelligently caching and reusing, or recomputing intermediates as appropriate. Helix captures a wide variety of application needs within its Scala DSL, with succinct syntax defining unified processes for data preprocessing, model specification, and learning. We demonstrate that the reuse problem can be cast as a Max-Flow problem, while the caching problem is NP-Hard. We develop effective lightweight heuristics for the latter. Empirical evaluation shows that Helix is not only able to handle a wide variety of use cases in one unified workflow but also much faster, providing run time reductions of up to 19x over state-of-the-art systems, such as DeepDive or KeystoneML, on four real-world applications in natural language processing, computer vision, social and natural sciences.
Making Sense of Random Forest Probabilities: a Kernel Perspective
A random forest is a popular tool for estimating probabilities in machine learning classification tasks. However, the means by which this is accomplished is unprincipled: one simply counts the fraction of trees in a forest that vote for a certain class. In this paper, we forge a connection between random forests and kernel regression. This places random forest probability estimation on more sound statistical footing. As part of our investigation, we develop a model for the proximity kernel and relate it to the geometry and sparsity of the estimation problem. We also provide intuition and recommendations for tuning a random forest to improve its probability estimates.
The Entropy of Artificial Intelligence and a Case Study of AlphaZero from Shannon’s Perspective
The recently released AlphaZero algorithm achieves superhuman performance in the games of chess, shogi and Go, which raises two open questions. Firstly, as there is a finite number of possibilities in the game, is there a quantifiable intelligence measurement for evaluating intelligent systems like AlphaZero? Secondly, AlphaZero introduces sophisticated reinforcement learning and self-play to efficiently encode the possible states, is there a simple information-theoretic model to represent the learning process and offer more insights? This paper explores the above two questions by proposing a simple variance of Shannon’s communication model, the concept of intelligence entropy and the Unified Intelligence-Communication Model is proposed, which provide an information-theoretic metric for investigating the intelligence level and also provide an bound for intelligent agents in the form of Shannon’s capacity, namely, the intelligence capacity. This paper then applies the concept and model to AlphaZero as a case study and explains the learning process of intelligent agent as turbo-like iterative decoding, so that the learning performance of AlphaZero may be quantitatively evaluated. Finally, conclusions are provided along with theoretical and practical remarks.
AdaFlow: Domain-Adaptive Density Estimator with Application to Anomaly Detection and Unpaired Cross-Domain Translation
We tackle unsupervised anomaly detection (UAD), a problem of detecting data that significantly differ from normal data. UAD is typically solved by using density estimation. Recently, deep neural network (DNN)-based density estimators, such as Normalizing Flows, have been attracting attention. However, one of their drawbacks is the difficulty in adapting them to the change in the normal data’s distribution. To address this difficulty, we propose AdaFlow, a new DNN-based density estimator that can be easily adapted to the change of the distribution. AdaFlow is a unified model of a Normalizing Flow and Adaptive Batch-Normalizations, a module that enables DNNs to adapt to new distributions. AdaFlow can be adapted to a new distribution by just conducting forward propagation once per sample; hence, it can be used on devices that have limited computational resources. We have confirmed the effectiveness of the proposed model through an anomaly detection in a sound task. We also propose a method of applying AdaFlow to the unpaired cross-domain translation problem, in which one has to train a cross-domain translation model with only unpaired samples. We have confirmed that our model can be used for the cross-domain translation problem through experiments on image datasets.
Linear programming based approximation for unweighted induced matchings — breaking the $Δ$ barrier
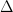

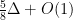
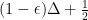
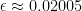
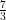
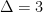
Context-encoding Variational Autoencoder for Unsupervised Anomaly Detection
Unsupervised learning can leverage large-scale data sources without the need for annotations. In this context, deep learning-based auto encoders have shown great potential in detecting anomalies in medical images. However, state-of-the-art anomaly scores are still based on the reconstruction error, which lacks in two essential parts: it ignores the model-internal representation employed for reconstruction, and it lacks formal assertions and comparability between samples. We address these shortcomings by proposing the Context-encoding Variational Autoencoder (ceVAE) which combines reconstruction- with density-based anomaly scoring. This improves the sample- as well as pixel-wise results. In our experiments on the BraTS-2017 and ISLES-2015 segmentation benchmarks, the ceVAE achieves unsupervised ROC-AUCs of 0.95 and 0.89, respectively, thus outperforming state-of-the-art methods by a considerable margin.
A Tutorial on Distance Metric Learning: Mathematical Foundations, Algorithms and Software
This paper describes the discipline of distance metric learning, a branch of machine learning that aims to learn distances from the data. Distance metric learning can be useful to improve similarity learning algorithms, and also has applications in dimensionality reduction. We describe the distance metric learning problem and analyze its main mathematical foundations. We discuss some of the most popular distance metric learning techniques used in classification, showing their goals and the required information to understand and use them. Furthermore, we present a Python package that collects a set of 17 distance metric learning techniques explained in this paper, with some experiments to evaluate the performance of the different algorithms. Finally, we discuss several possibilities of future work in this topic.
Probabilistic Class-Specific Discriminant Analysis
In this paper we formulate a probabilistic model for class-specific discriminant subspace learning. The proposed model can naturally incorporate the multi-modal structure of the negative class, which is neglected by existing methods. Moreover, it can be directly used to define a probabilistic classification rule in the discriminant subspace. We show that existing class-specific discriminant analysis methods are special cases of the proposed probabilistic model and, by casting them as probabilistic models, they can be extended to class-specific classifiers. We illustrate the performance of the proposed model, in comparison with that of related methods, in both verification and classification problems.
Measuring Similarity: Computationally Reproducing the Scholar’s Interests
Computerized document classification already orders the news articles that Apple’s ‘News’ app or Google’s ‘personalized search’ feature groups together to match a reader’s interests. The invisible and therefore illegible decisions that go into these tailored searches have been the subject of a critique by scholars who emphasize that our intelligence about documents is only as good as our ability to understand the criteria of search. This article will attempt to unpack the procedures used in computational classification of texts, translating them into term legible to humanists, and examining opportunities to render the computational text classification process subject to expert critique and improvement.
More Effective Ontology Authoring with Test-Driven Development
Ontology authoring is a complex process, where commonly the automated reasoner is invoked for verification of newly introduced changes, therewith amounting to a time-consuming test-last approach. Test-Driven Development (TDD) for ontology authoring is a recent {\em test-first} approach that aims to reduce authoring time and increase authoring efficiency. Current TDD testing falls short on coverage of OWL features and possible test outcomes, the rigorous foundation thereof, and evaluations to ascertain its effectiveness. We aim to address these issues in one instantiation of TDD for ontology authoring. We first propose a succinct, logic-based model of TDD testing and present novel TDD algorithms so as to cover also any OWL 2 class expression for the TBox and for the principal ABox assertions, and prove their correctness. The algorithms use methods from the OWL API directly such that reclassification is not necessary for test execution, therewith reducing ontology authoring time. The algorithms were implemented in TDDonto2, a Prot\’eg\’e plugin. TDDonto2 was evaluated on editing efficiency and by users. The editing efficiency study demonstrated that it is faster than a typical ontology authoring interface, especially for medium size and large ontologies. The user evaluation demonstrated that modellers make significantly less errors with TDDonto2 compared to the standard Prot\’eg\’e interface and complete their tasks better using less time. Thus, the results indicate that Test-Driven Development is a promising approach in an ontology development methodology.
Factorization of Dempster-Shafer Belief Functions Based on Data
One important obstacle in applying Dempster-Shafer Theory (DST) is its relationship to frequencies. In particular, there exist serious difficulties in finding factorizations of belief functions from data. In probability theory factorizations are usually related to notion of (conditional) independence and their possibility tested accordingly. However, in DST conditional belief distributions prove to be non-proper belief functions (that is ones connected with negative ‘frequencies’). This makes statistical testing of potential conditional independencies practically impossible, as no coherent interpretation could be found so far for negative belief function values. In this paper a novel attempt is made to overcome this difficulty. In the proposal no conditional beliefs are calculated, but instead a new measure F is introduced within the framework of DST, closely related to conditional independence, allowing to apply conventional statistical tests for detection of dependence/independence.
Like this:
Like Loading…
Related