In a 2017 business research article IBM predicted that the need for Data Scientists will increase by 28% by 2020, with nearly 3 million job openings for Data Science professionals. According to a Forbes report, Data Science is the best job in America for three consecutive years, with a median base salary of $110,000 and over 4,524 job openings.
According to Glassdoor’s 50 Best Jobs In America For 2018 research, Data Scientist jobs are among the 50 best jobs based on each job’s overall Glassdoor Job Score. We calculate the Glassdoor Job Score by weighing three key factors equally: earning potential based on the median annual base salary, job satisfaction rating, and the number of job openings. Hence, the need for sharpening Data Scientist skills are at an all-time high.
In this blog, we will be looking at all the technical and non-technical skills that are absolute in mastering the domain of data science.
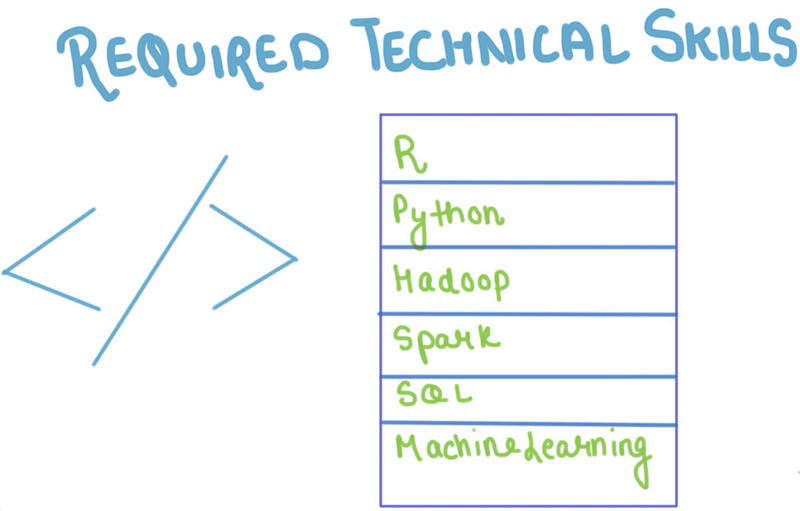
R &Python
R is a language for statistical computations, data analysis and graphical representation of data. It is a very popular language in academia. Many researchers and scholars use it for experimenting with data science. Many popular books and learning resources on data science use R for statistical analysis as well. Also, it has an extensive library of tools for database manipulation and wrangling. Data visualization is the visual representation of data in graphical form. This allows analyzing data from angles which are not clear in unorganized or tabulated data. R has many tools that can help in data visualization, analysis, and representation. The packages ggplot2 and ggedit for have become the standard plotting packages. Also, It allows practising a wide variety of statistical and graphical techniques like time-series analysis, classification, classical statistical tests, clustering, etc.
###
When it comes to data science, Python is a very powerful tool, which is also open sourced and flexible, adding more to its popularity. It has massive libraries for manipulation of data and is extremely easy to learn and use for all data analysts. Anyone who is familiar with programming languages such as, Java, Visual Basic, C++ or C, will find this tool to be very accessible and easy to work with. Apart from being an independent platform, this tool has the ability to easily integrate with the existing Infrastructure and can also solve the most difficult of problems. This tool is powerful, friendly, easy and plays well with others, apart from running everywhere. A lot of banks use this tool for the purpose of crunching data, some institutions use it for analyzing and visualization. This tool offers the great benefit of using one programming language, across multiple application platforms.
Python has already been proven to be as good as R Programming is, in terms of all the process under data analytics. Any novice, entering the field of data analytics can use this programming language to start in the data science industry. As a result of its multipurpose uses, there are a lot of institutes, which offer courses in Python.
Hadoop
Hadoop is an open-source software framework that provides for processing of large data sets across clusters of computers using simple programming models. It can scale up from single servers to thousands of machines.
Hadoop grew out of an open-source search engine called Nutch, developed by Doug Cutting and Mike Cafarella. Back in the early days of the Internet, the pair were looking forward to inventing a way to return web search results faster by distributing data and calculations across different computers so multiple tasks could execute at the same time.
It has a lot to offer. Benefits are :
-
Computing power:Hadoop’s distributed computing model allows it to process huge amounts of data. The more nodes you use, the more processing power you have.
-
Flexibility:Hadoop stores data without requiring any preprocessing. Store data — even unstructured data such as text, images, and video — now; decide what to do with it later.
-
Fault tolerance:Hadoop automatically stores multiple copies of all data, and if one node fails during data processing, jobs are redirected to other nodes and distributed computing continues.
-
Low cost:The open-source framework is free, and data is stored on commodity hardware.
-
Scalability:You can easily grow your Hadoop system, simply by adding more nodes.
Although the development of Hadoop came from the need to search millions of web pages and return relevant results, it today serves a variety of purposes. Hadoop’s low-cost storage makes it an appealing option for storing information that is not currently critical but that might be analyzed later.
Spark
Hadoop continues to garner the most name-recognition in big data processing, but Spark is, appropriately, beginning to ignite it’s utility as a vehicle for data analysis and processing, versus simply data storage.
It consists of four core components:
-
Hadoop Common— Essential utilities and tools referenced by the other modules
-
Distributed File System— The high-throughput file storage system (HDFS)
-
Hadoop YARN— The job-scheduling framework for distributed process allocation
-
MapReduce— The parallel processing module based on YARN
Spark replaces only two of those, YARN and MapReduce. According to a February 2016 article in Information Week, many Spark implementations chug happily away on top of Hadoop Common code and the HDFS. Thanks to the integration, many major companies that have implemented Hadoop clusters to deal with insane amounts of data — the likes of Amazon and Facebook — have kept the data storage elements and simply swapped in Spark as a high-performance alternative to MapReduce.
SQL
SQL, or Structured Query Language, is a special-purpose programming language for managing data held in relational database management systems. Almost all structured data resides in such databases, so, if you want to play with data, chances are you’ll want to know some SQL.
Here are some awesome things you can do with SQL
-
Generate queries from a query: Basic string concatenation makes it easy to generate en masse queries that use data in a database to fetch data found in another system.
-
Handle dates: “Fantastic date functions” exist to meet all your formatting and type conversion needs.
-
Text mining: Yhat recommends going as far as you can with SQL’s built-in string functions before turning to a scripting language.
-
Find the median: Since there’s no built-in aggregate function for median, Yhat provides the code.
-
Load data into your database with the \COPY command.
-
Generate sequences: Use the generate_series function to create ranges of dates and times and to handle time series and funnels.
Machine Learning
Simply put, Machine Learning is the core subarea of artificial intelligence. It makes computers get into a self-learning mode without explicit programming. When fed new data, these computers learn, grow, change, and develop by themselves.
The machine learning field is constantly evolving. And along with evolution comes a rise in the demand and importance. There is one crucial reason why data scientists need machine learning, and that is: ‘High-value predictions that can guide better decisions and smart actions in real time without human intervention’.
Machine learning as a technology helps analyze large chunks of data, easing the tasks of data scientists in an automated process and is gaining a lot of prominence and recognition. Machine learning has changed the way data extraction and interpretation works by involving automatic sets of generic methods that have replaced the traditional statistical techniques.
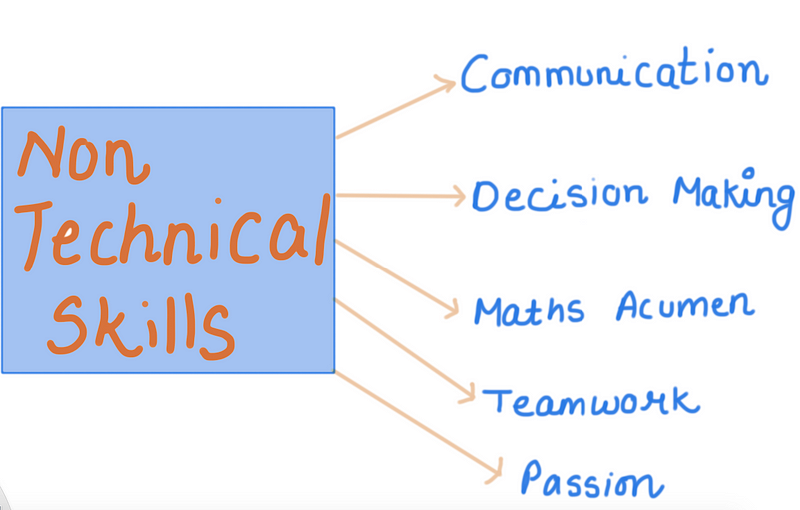
Now, the skill set of a successful data scientist will comprise both technical and non-technical skills. While technical skills like programming and quantitative analysis are important, it is easy to undervalue the impact of non-technical skills. So, before we go on to the technical stuff, here is a list of 5 non-technical skills that you must possess:
Communication
Effective business communication is one of the most important abilities. Whether it’s understanding the business requirements or the problem at hand, seeking more data from stakeholders or communicating insights, a data scientist needs to be convincing. ” Storytelling, ” as data scientists call it, means that analytical solutions are communicated in a clear, concise and timely manner in order to benefit both technical and non-technical people. Data visualization and presentation tools are widely employed by data scientists for their graphic appeal and easy absorption by all teams in the organization. Often underestimated, this is one of the most important skills for the simple reason that all statistical computation is useless if the teams can’t act upon it.
Data-Driven Decision Making
A data scientist will not conclude, judge, or decide without adequate data. Scientists need to decide their approach to a business problem in addition to deciding several other things like where to look, what tools and techniques to use, and how to visualize and communicate it in the most effective possible way. The most important thing for them is to ask relevant questions, even if they seem far-fetched. Think of it as a child exploring all his surroundings to draw conclusions. A data scientist is pretty much the same.
Mathematical and Statistical Acumen
A data scientist will never thrive if he/she doesn’t understand what test to run when and how to interpret their findings. They need a solid understanding of algebra and calculus. In good old days, Math was a subject based on common sense and the need to resolve basic problems based on logic. This hasn’t changed much, though the scale has blown up exponentially. A statistical sensibility provides a solid foundation for several analysis tools and techniques, which are used by a data scientist to build their models and analytic routines.
Teamwork
Teamwork is another feather in the cap that data scientists can not do without. Although they may appear to be able to work in isolation, they are closely involved in the organization at various levels. On the one hand, they will have to work with the teams to understand their requirements, collect feedback to achieve beneficial solutions, and on the other hand work with data scientists, data architects and data engineers to perform their tasks well. The culture in a data-driven organization will never be that of the data science team working in isolation; instead, the team will have to use the same characteristics across the organization to make the best use of the insights they draw from various departments.
Intellectual Curiosity and Passion
This is a tad-bit cliched but true. Data scientists are passionate about their work and have an inconsolable itch to use data to find patterns and provide solutions to business problems. They often have to work with unstructured data and rarely know the exact steps they need to take to find valuable insights that lead to business growth. Sometimes, they don’t even have a clear problem to work with, just signs that there is something wrong. That’s where their intellectual curiosity guides them to look in areas no one else has looked in. You don’t need to read “How to think like Sherlock,” just ask a data scientist!
The next question I always get is, “What can I do to develop these skills?” There are many resources around the web, but I don’t want to give anyone the mistaken impression that the path to data science is as simple as taking a few MOOCs. Unless you already have a strong quantitative background, the road to becoming a data scientist will be challenging but not impossible.
However, if it’s something you sincerely want to pursue and have a passion for data and lifelong learning, don’t let your background discourage you from pursuing data science as a career.
Please follow and like us:
![]()