By Suvro Banerjee, Machine Learning Engineer @ Juniper Networks

Introduction
In this article we will learn what is Named Entity Recognition also known as NER. We will discuss some of its use-cases and then evaluate few standard Python libraries using which we can quickly get started and solve problems at hand.
In the next series of articles we will get under the hood of this class of algorithms, get more sophisticated and will create our own NER from scratch.
So, let’s begin this journey.
What is Named Entity Recognition?
Named Entity Recognition, also known as entity extraction classifies named entities that are present in a text into pre-defined categories like “individuals”, “companies”, “places”, “organization”, “cities”, “dates”, “product terminologies” etc. It adds a wealth of semantic knowledge to your content and helps you to promptly understand the subject of any given text.
Few Use-Cases of Named Entity Recognition
Classifying content for news providers
 Classifying content for news providers
Classifying content for news providers
Named Entity Recognition can automatically scan entire articles and reveal which are the major people, organizations, and places discussed in them. Knowing the relevant tags for each article help in automatically categorizing the articles in defined hierarchies and enable smooth content discovery.
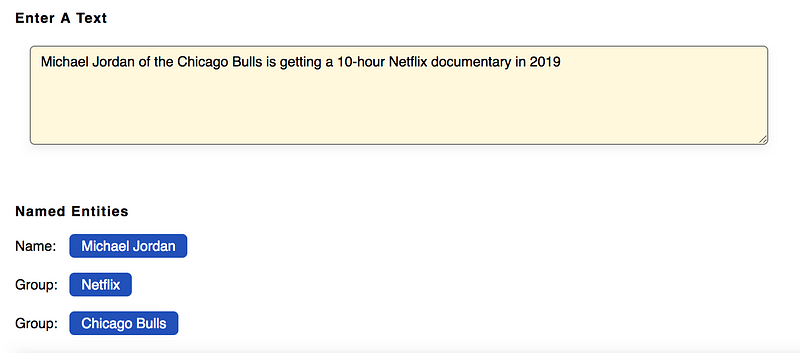 https://www.paralleldots.com/named-entity-recognition
https://www.paralleldots.com/named-entity-recognition
Efficient Search Algorithms
 Efficient search across the brands
Efficient search across the brands
Let’s suppose you are designing an internal search algorithm for an online publisher that has millions of articles. If for every search query the algorithm ends up searching all the words in millions of articles, the process will take a lot of time. Instead, if Named Entity Recognition can be run once on all the articles and the relevant entities (tags) associated with each of those articles are stored separately, this could speed up the search process considerably. With this approach, a search term will be matched with only the small list of entities discussed in each article leading to faster search execution.
Customer Support
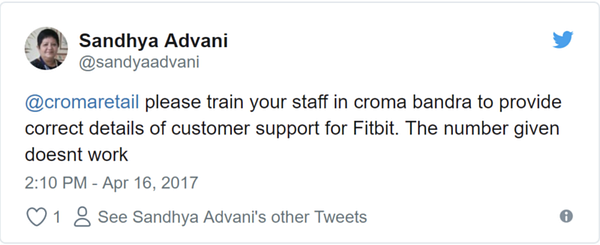 Customer support on Twitter
Customer support on Twitter
Say you are handling the customer support department of an electronic store with multiple branches worldwide, you go through a number mentions in your customers’ feedback. Like this for instance.
Now, if you pass it through the Named Entity Recognition API, it pulls out the entities Bandra (location) and Fitbit (Product). This can be then used to categorize the complaint and assign it to the relevant department within the organization that should be handling this.
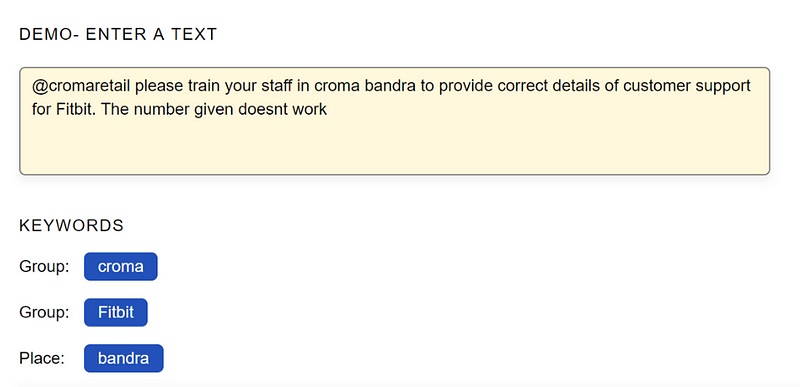 https://www.paralleldots.com/named-entity-recognition
https://www.paralleldots.com/named-entity-recognition
Standard Libraries to use Named Entity Recognition
I will discuss three standard libraries which are used a lot in Python to perform NER. I am sure there are many more and would encourage readers to add them in the comment section.
Stanford NER spaCy NLTK
Stanford NER
 Stanford NER
Stanford NER
Stanford NER is a Java implementation of a Named Entity Recognizer. Stanford NER is also known as CRFClassifier. The software provides a general implementation of (arbitrary order) linear chain Conditional Random Field (CRF) sequence models. That is, by training your own models on labeled data, you can actually use this code to build sequence models for NER or any other task.
Now NLTK (Natural Language Toolkit) is a great Python package that provides a set of natural languages corpora and APIs of wide varieties of NLP algorithms. NLTK comes along with the efficient Stanford NER implementation.
Now with this background, let’s use Stanford NER.
Install NLTK library
Download Stanford NER library
Go to https://nlp.stanford.edu/software/CRF-NER.html#Download and download the latest version, I am using Stanford Named Entity Recognizer version 3.9.2.
I get a zip file which is called “stanford-ner-2018–10–16.zip” which needs to be unzipped and I renamed it to stanford_ner and placed it in the home folder.

Now the following Python code is written to perform the NER on some given text. The code is placed in the “bsuvro” folder, so that I can use the relative path to access the NER tagger engine (stanford-ner-3.9.2.jar) and NER model trained on the English corpus (classifiers/english.muc.7class.distsim.crf.ser.gz). You can see I am using 7class model which will give seven different output named entities like Location, Person, Organization, Money, Percent, Date, Time.
You can also use —
english.all.3class.distsim.crf.ser.gz: Location, Person and Organization english.conll.4class.distsim.crf.ser.gz: Location, Person, Organization and Misc
Stanford Named Entity Recognition
The output of the above code is below and you can see how the words are tagged as named entities. Note “O” is something which is not tagged or can be called as “Others”.
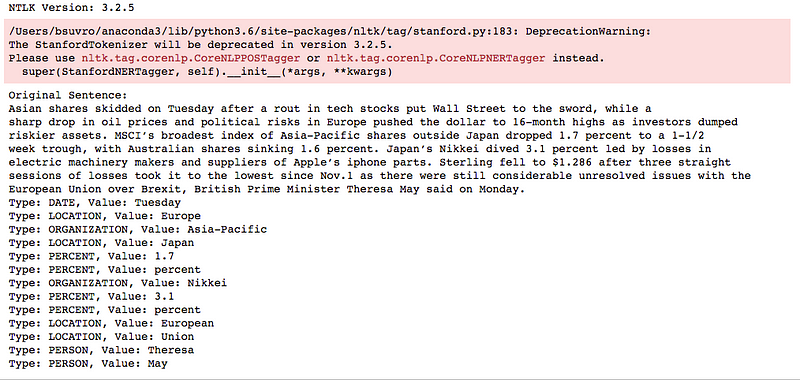 Output of the Stanford NER tagger
Output of the Stanford NER tagger
Now, let’s move to the next library called spaCy.
spaCy
 spaCy NER
spaCy NER
spaCy is known for industrial-strength natural language processing library in Python. It has been written in Cython which is a superset of Python programming language with C-like performance.
Although I wish to go in details about spaCy as it has lot of interesting NLP modules, but I will focus here on the NER tagging. I will definitely have a separate series on exploring spaCy.
Install spaCy library and download the “en” (English) model
spaCy NER
The output of the above code -
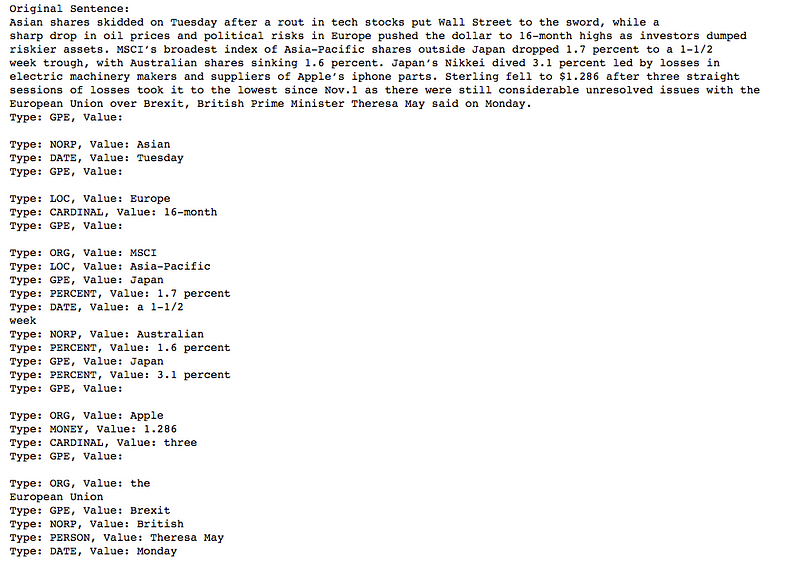 Output from spaCy NER
Output from spaCy NER
Now this supports following Entity types-
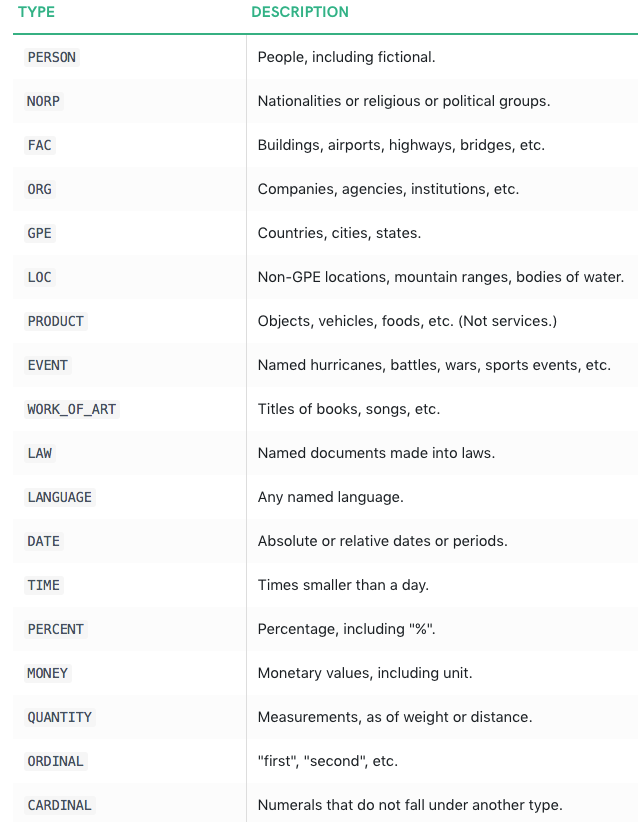 https://spacy.io/api/annotation#pos-tagging
https://spacy.io/api/annotation#pos-tagging