
It gives you a U-shaped distribution, which is probably not what you want as a correlation prior.
A simple uniform(-1, 1) would be close, but uniform. We tend to prefer distributions concentrated around 0 to regularize correlation estimates. You can do that by cutting down on the scale of the normal, say normal(0, 0.5) instead of normal(0, 1).
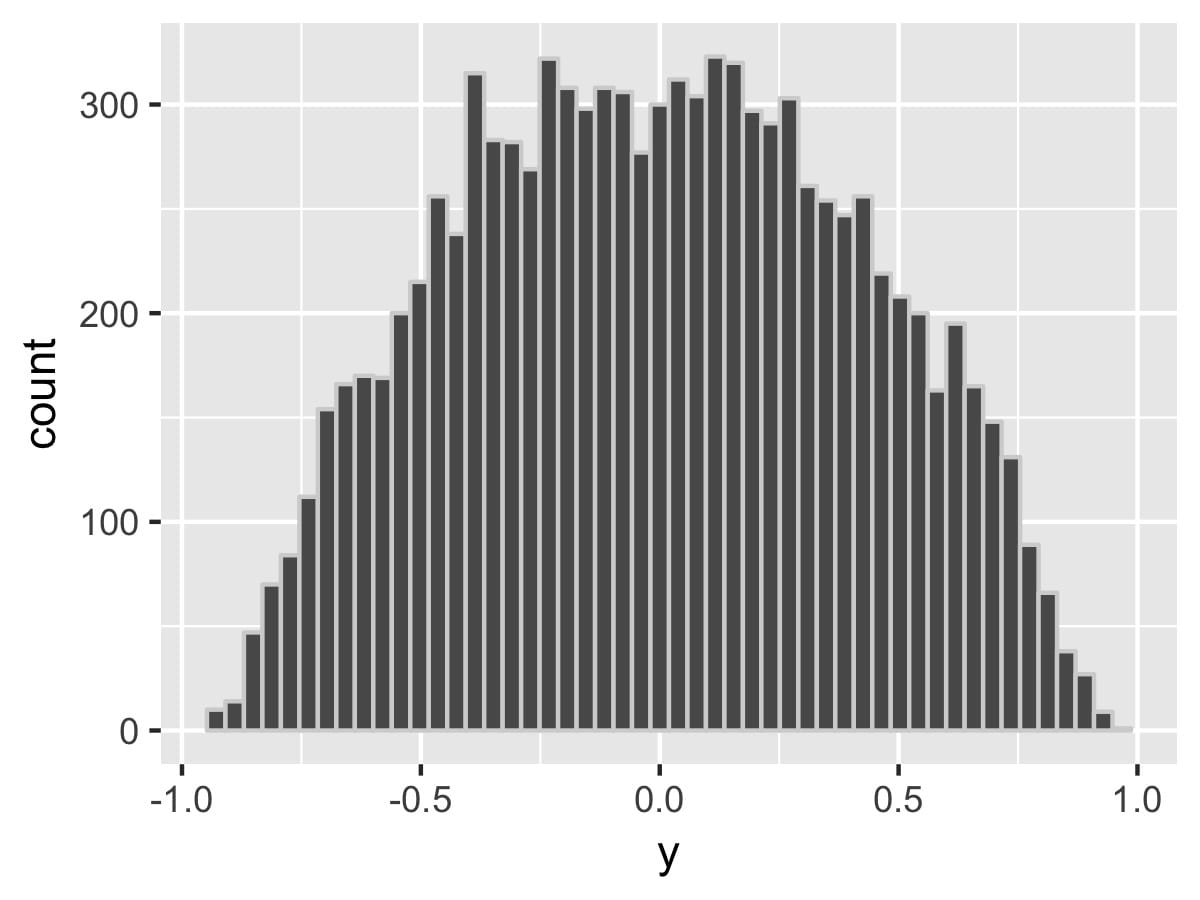
With Stan, you could just truncate a normal(0, whatever) to [-1, 1] rather than transforming using tanh(). That would still allow the boundaries to have non-zero density.
Using uniform(-1, 1) is what you get in 2 dimensions setting the LKJ parameter to 1. As dimensionality increases, LKJ(1) is still uniform on correlation matrices, but each marginal correlation becomes more peaked around 0 because of the positive-definiteness constraint.