Overview
NIMBLE is a hierarchical modeling package that uses nearly the same language for model specification as the popular MCMC packages WinBUGS, OpenBUGS and JAGS, while making the modeling language extensible — you can add distributions and functions — and also allowing customization of the algorithms used to estimate the parameters of the model.
Recently, we added support for Markov chain Monte Carlo (MCMC) inference for Bayesian nonparametric (BNP) mixture models to NIMBLE. In particular, starting with version 0.6-11, NIMBLE provides functionality for fitting models involving Dirichlet process priors using either the Chinese Restaurant Process (CRP) or a truncated stick-breaking (SB) representation of the Dirichlet process prior.
In this post we illustrate NIMBLE’s BNP capabilities by showing how to use nonparametric mixture models with different kernels for density estimation. In a later post, we will take a parametric generalized linear mixed model and show how to switch to a nonparametric representation of the random effects that avoids the assumption of normally-distributed random effects.
For more detailed information on NIMBLE and Bayesian nonparametrics in NIMBLE, see the NIMBLE User Manual.
Basic density estimation using Dirichlet Process Mixture models
NIMBLE provides the machinery for nonparametric density estimation by means of Dirichlet process mixture (DPM) models (Ferguson, 1974; Lo, 1984; Escobar, 1994; Escobar and West, 1995). For an independent and identically distributed sample 
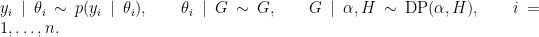
The NIMBLE implementation of this model is flexible and allows for mixtures of arbitrary kernels, 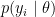

To illustrate these capabilities, we consider the estimation of the probability density function of the waiting time between eruptions of the Old Faithful volcano data set available in R.
The observations 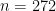
Fitting a location-scale mixture of Gaussian distributions using the CRP representation
Model specification
We first consider a location-scale Dirichlet process mixture of normal distributionss fitted to the transformed data 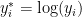
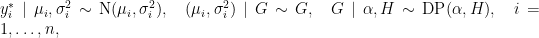
where 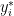
Introducing auxiliary variables 
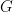
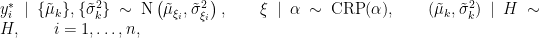
where

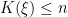


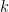
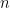
NIMBLE’s specification of this model is given by
Note that in the model code the length of the parameter vectors muTilde and s2Tilde has been set to
Note also that the value of 
Running the MCMC algorithm
The following code sets up the data and constants, initializes the parameters, defines the model object, and builds and runs the MCMC algorithm. Because the specification is in terms of a Chinese restaurant process, the default sampler selected by NIMBLE is a collapsed Gibbs sampler (Neal, 2000).
We can extract the samples from the posterior distributions of the parameters and create trace plots, histograms, and any other summary of interest. For example, for the concentration parameter


Under this model, the posterior predictive distribution for a new observation 

Recall, however, that this is the density estimate for the logarithm of the waiting time. To obtain the density on the original scale we need to apply the appropriate transformation to the kernel.

In either case, there is clear evidence that the data has two components for the waiting times.
Generating samples from the mixing distribution
While samples from the posterior distribution of linear functionals of the mixing distribution
The following code generates posterior samples from the random measure 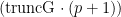
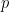

The following code computes posterior samples of

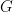
. Note that these samples are computed based on the transformed model and a value larger than 70 corresponds to a value larger than 0.03557236 on the above defined grid.](http://s0.wp.com/latex.php?latex=P%28%5Ctilde%7By%7D+%3E+70%29&bg=ffffff&%23038;fg=000000&%23038;s=0)

Fitting a mixture of gamma distributions using the CRP representation
NIMBLE is not restricted to using Gaussian kernels in DPM models. In the case of the Old Faithful data, an alternative to the mixture of Gaussian kernels on the logarithmic scale that we presented in the previous section is a (scale-and-shape) mixture of Gamma distributions on the original scale of the data.
Model specification
In this case, the model takes the form

where
Note that in this case the vectors betaTilde and lambdaTilde have length 
Running the MCMC algorithm
The following code sets up the model data and constants, initializes the parameters, defines the model object, and builds and runs the MCMC algorithm for the mixture of Gamma distributions. Note that, when building the MCMC, a warning message about the number of cluster parameters is generated. This is because the lengths of betaTilde and lambdaTilde are smaller than
In this case we use the posterior samples of the parameters to construct a trace plot and estimate the posterior distribution of


Generating samples from the mixing distribution
As before, we obtain samples from the posterior distribution of
We use these samples to create an estimate of the density of the data along with a pointwise 95% credible band:

Again, we see that the density of the data is bimodal, and looks very similar to the one we obtained before.
Fitting a DP mixture of Gammas using a stick-breaking representation
Model specification
An alternative representation of the Dirichlet process mixture uses the stick-breaking representation of the random distribution 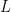
Introducing auxiliary variables, 
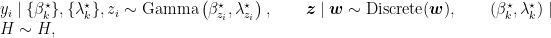
where
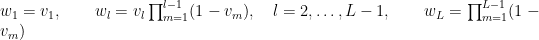
with 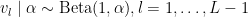
Note that the truncation level
Running the MCMC algorithm
The following code sets up the model data and constants, initializes the parameters, defines the model object, and builds and runs the MCMC algorithm for the mixture of Gamma distributions. When a stick-breaking representation is used, a blocked Gibbs sampler is assigned (Ishwaran, 2001; Ishwaran and James, 2002).
Using the stick-breaking approximation automatically provides an approximation, 

As expected, this estimate looks identical to the one we obtained through the CRP representation of the process.
More information and future development
Please see our User Manual for more details.
We’re in the midst of improvements to the existing BNP functionality as well as adding additional Bayesian nonparametric models, such as hierarchical Dirichlet processes and Pitman-Yor processes, so please add yourself to our announcement or user support/discussion Google groups.
References
Blackwell, D. and MacQueen, J. 1973. Ferguson distributions via Polya urn schemes. The Annals of Statistics 1:353-355.
Ferguson, T.S. 1974. Prior distribution on the spaces of probability measures. Annals of Statistics 2:615-629.
Lo, A.Y. 1984. On a class of Bayesian nonparametric estimates I: Density estimates. The Annals of Statistics 12:351-357.
Escobar, M.D. 1994. Estimating normal means with a Dirichlet process prior. Journal of the American Statistical Association 89:268-277.
Escobar, M.D. and West, M. 1995. Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association 90:577-588.
Ishwaran, H. and James, L.F. 2001. Gibbs sampling methods for stick-breaking priors. Journal of the American Statistical Association 96: 161-173.
Ishwaran, H. and James, L.F. 2002. Approximate Dirichlet process computing in finite normal mixtures: smoothing and prior information. Journal of Computational and Graphical Statistics 11:508-532.
Neal, R. 2000. Markov chain sampling methods for Dirichlet process mixture models. Journal of Computational and Graphical Statistics 9:249-265.
Sethuraman, J. 1994. A constructive definition of Dirichlet prior. Statistica Sinica 2: 639-650.
Related