ggeffects (CRAN, website) is a package that computes marginal effects at the mean (MEMs) or representative values (MERs) for many different models, including mixed effects or Bayesian models. One of the advantages of the package is its easy-to-use interface: No matter if you fit a simple or complex model, with interactions or splines, the function call is always the same. This also holds true for the returned output, which is always a data frame with the same, consistent column names.
The past package-update introduced some new features I wanted to describe here: a revised print()-method as well as a new opportunity to plot marginal effects at different levels of random effects in mixed models…
The new print()-method
The former print()-method simply showed the first predicted values, including confidence intervals. For numeric predictor variables with many values, you could, for instance, only see the first 10 of more than 100 predicted values. While it makes sense to shorten the (console-)output, there was no information about the predictions for the last or other „representative“ values of the term in question. Now, the print()-method automatically prints a selection of representative values, so you get a quick and clean impression of the range of predicted values for continuous variables:
1 | |
If you print predicted values of a term, grouped by the levels of another term (which makes sense in the above example due to the present interaction), the print()-method automatically adjusts the range of printed values to keep the console-output short. In the following example, only 6 instead of 8 values per „block“ are shown:
1 | |
Marginal effects at specific levels of random effects
Marginal effects can also be calculated for each group level in mixed models. Simply add the name of the related random effects term to the terms-argument, and set type = "re". In the following example, we fit a linear mixed model and first simply plot the marginal effetcs, not conditioned on random effects.
1 | |

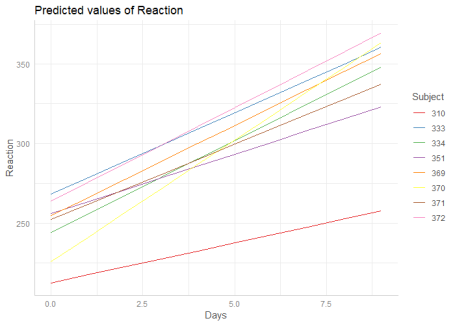
To compute marginal effects for each grouping level, add the related random term to the terms-argument. In this case, confidence intervals are not calculated, but marginal effects are conditioned on each group level of the random effects.
1 | |

Marginal effects, conditioned on random effects, can also be calculated for specific levels only. Add the related values into brackets after the variable name in the terms-argument.
1 | |

If the group factor has too many levels, you can also take a random sample of all possible levels and plot the marginal effects for this subsample of group levels. To do this, use term = "groupfactor [sample=n]".
1 | |
Related