Graph Convolutional Neural Networks via Motif-based Attention
Many real-world problems can be represented as graph-based learning problems. In this paper, we propose a novel framework for learning spatial and attentional convolution neural networks on arbitrary graphs. Different from previous convolutional neural networks on graphs, we first design a motif-matching guided subgraph normalization method to capture neighborhood information. Then we implement self-attentional layers to learn different importances from different subgraphs to solve graph classification problems. Analogous to image-based attentional convolution networks that operate on locally connected and weighted regions of the input, we also extend graph normalization from one-dimensional node sequence to two-dimensional node grid by leveraging motif-matching, and design self-attentional layers without requiring any kinds of cost depending on prior knowledge of the graph structure. Our results on both bioinformatics and social network datasets show that we can significantly improve graph classification benchmarks over traditional graph kernel and existing deep models.
Assessing four Neural Networks on Handwritten Digit Recognition Dataset (MNIST)
Although the image recognition has been a research topic for many years, many researchers still have a keen interest in it. In some papers, however, there is a tendency to compare models only on one or two datasets, either because of time restraints or because the model is tailored to a specific task. Accordingly, it is hard to understand how well a certain model generalizes across image recognition field. In this paper, we compare four neural networks on MNIST dataset with different division. Among of them, three are Convolutional Neural Networks (CNN), Deep Residual Network (ResNet) and Dense Convolutional Network (DenseNet) respectively, and the other is our improvement on CNN baseline through introducing Capsule Network (CapsNet) to image recognition area. We show that the previous models despite do a quite good job in this area, our retrofitting can be applied to get a better performance. The result obtained by CapsNet is an accuracy rate of 99.75\%, and it is the best result published so far. Another inspiring result is that CapsNet only needs a small amount of data to get the excellent performance. Finally, we will apply CapsNet’s ability to generalize in other image recognition field in the future.
Autonomous Extraction of a Hierarchical Structure of Tasks in Reinforcement Learning, A Sequential Associate Rule Mining Approach
Reinforcement learning (RL) techniques, while often powerful, can suffer from slow learning speeds, particularly in high dimensional spaces. Decomposition of tasks into a hierarchical structure holds the potential to significantly speed up learning, generalization, and transfer learning. However, the current task decomposition techniques often rely on high-level knowledge provided by an expert (e.g. using dynamic Bayesian networks) to extract a hierarchical task structure; which is not necessarily available in autonomous systems. In this paper, we propose a novel method based on Sequential Association Rule Mining that can extract Hierarchical Structure of Tasks in Reinforcement Learning (SARM-HSTRL) in an autonomous manner for both Markov decision processes (MDPs) and factored MDPs. The proposed method leverages association rule mining to discover the causal and temporal relationships among states in different trajectories, and extracts a task hierarchy that captures these relationships among sub-goals as termination conditions of different sub-tasks. We prove that the extracted hierarchical policy offers a hierarchically optimal policy in MDPs and factored MDPs. It should be noted that SARM-HSTRL extracts this hierarchical optimal policy without having dynamic Bayesian networks in scenarios with a single task trajectory and also with multiple tasks’ trajectories. Furthermore, it has been theoretically and empirically shown that the extracted hierarchical task structure is consistent with trajectories and provides the most efficient, reliable, and compact structure under appropriate assumptions. The numerical results compare the performance of the proposed SARM-HSTRL method with conventional HRL algorithms in terms of the accuracy in detecting the sub-goals, the validity of the extracted hierarchies, and the speed of learning in several testbeds.
Self-Organizing Maps for Storage and Transfer of Knowledge in Reinforcement Learning
The idea of reusing or transferring information from previously learned tasks (source tasks) for the learning of new tasks (target tasks) has the potential to significantly improve the sample efficiency of a reinforcement learning agent. In this work, we describe a novel approach for reusing previously acquired knowledge by using it to guide the exploration of an agent while it learns new tasks. In order to do so, we employ a variant of the growing self-organizing map algorithm, which is trained using a measure of similarity that is defined directly in the space of the vectorized representations of the value functions. In addition to enabling transfer across tasks, the resulting map is simultaneously used to enable the efficient storage of previously acquired task knowledge in an adaptive and scalable manner. We empirically validate our approach in a simulated navigation environment, and also demonstrate its utility through simple experiments using a mobile micro-robotics platform. In addition, we demonstrate the scalability of this approach, and analytically examine its relation to the proposed network growth mechanism. Further, we briefly discuss some of the possible improvements and extensions to this approach, as well as its relevance to real world scenarios in the context of continual learning.
On Human Predictions with Explanations and Predictions of Machine Learning Models: A Case Study on Deception Detection
Humans are the final decision makers in critical tasks that involve ethical and legal concerns, ranging from recidivism prediction, to medical diagnosis, to fighting against fake news. Although machine learning models can sometimes achieve impressive performance in these tasks, these tasks are not amenable to full automation. To realize the potential of machine learning for improving human decisions, it is important to understand how assistance from machine learning models affect human performance and human agency. In this paper, we use deception detection as a testbed and investigate how we can harness explanations and predictions of machine learning models to improve human performance while retaining human agency. We propose a spectrum between full human agency and full automation, and develop varying levels of machine assistance along the spectrum that gradually increase the influence of machine predictions. We find that without showing predicted labels, explanations alone do not statistically significantly improve human performance in the end task. In comparison, human performance is greatly improved by showing predicted labels (>20% relative improvement) and can be further improved by explicitly suggesting strong machine performance. Interestingly, when predicted labels are shown, explanations of machine predictions induce a similar level of accuracy as an explicit statement of strong machine performance. Our results demonstrate a tradeoff between human performance and human agency and show that explanations of machine predictions can moderate this tradeoff.
EFSIS: Ensemble Feature Selection Integrating Stability
Ensemble learning that can be used to combine the predictions from multiple learners has been widely applied in pattern recognition, and has been reported to be more robust and accurate than the individual learners. This ensemble logic has recently also been more applied in feature selection. There are basically two strategies for ensemble feature selection, namely data perturbation and function perturbation. Data perturbation performs feature selection on data subsets sampled from the original dataset and then selects the features consistently ranked highly across those data subsets. This has been found to improve both the stability of the selector and the prediction accuracy for a classifier. Function perturbation frees the user from having to decide on the most appropriate selector for any given situation and works by aggregating multiple selectors. This has been found to maintain or improve classification performance. Here we propose a framework, EFSIS, combining these two strategies. Empirical results indicate that EFSIS gives both high prediction accuracy and stability.
Optimal Transport Classifier: Defending Against Adversarial Attacks by Regularized Deep Embedding
Recent studies have demonstrated the vulnerability of deep convolutional neural networks against adversarial examples. Inspired by the observation that the intrinsic dimension of image data is much smaller than its pixel space dimension and the vulnerability of neural networks grows with the input dimension, we propose to embed high-dimensional input images into a low-dimensional space to perform classification. However, arbitrarily projecting the input images to a low-dimensional space without regularization will not improve the robustness of deep neural networks. Leveraging optimal transport theory, we propose a new framework, Optimal Transport Classifier (OT-Classifier), and derive an objective that minimizes the discrepancy between the distribution of the true label and the distribution of the OT-Classifier output. Experimental results on several benchmark datasets show that, our proposed framework achieves state-of-the-art performance against strong adversarial attack methods.
Model change detection with application to machine learning
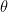

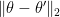
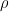
Statistics of Stochastics: A conditional space-time POD formalism for intermittent and rare events with application to jet noise
We present a conditional space-time POD formulation that is tailored to the eduction of the average, rare or intermittent event from an ensemble of realizations of a fluid process. By construction, the resulting spatio-temporal modes are coherent in space and over a pre-defined finite time horizon and optimally capture the variance, or energy of the ensemble. For the example of intermittent acoustic radiation from a turbulent jet, we introduce a conditional expectation operator that focuses on the loudest events, as measured by a pressure probe in the far-field and contained in the tail of the pressure signal’s probability distribution. Applied to high-fidelity simulation data, the method identifies a statistically significant `prototype’, or average acoustic burst event that is tracked over time. Most notably, the burst event can be traced back to its precursor, which opens up the possibility of prediction of an imminent burst. We furthermore investigate the mechanism underlying the prototypical burst event using linear stability theory and find that its structure and evolution is accurately predicted by optimal transient growth theory. The jet-noise problem demonstrates that the conditional space-time POD formulation applies even for systems with probability distributions that are not heavy-tailed, i.e. for systems in which events overlap and occur in rapid succession.
ShapeSearch: A Flexible and Efficient System for Shape-based Exploration of Trendlines
Identifying trendline visualizations with desired patterns is a common and fundamental data exploration task. Existing visual analytics tools offer limited flexibility and expressiveness for such tasks, especially when the pattern of interest is under-specified and approximate, and do not scale well when the pattern searching needs are ad-hoc, as is often the case. We propose ShapeSearch, an efficient and flexible pattern-searching tool, that enables the search for desired patterns via multiple mechanisms: sketch, natural-language, and visual regular expressions. We develop a novel shape querying algebra, with a minimal set of primitives and operators that can express a large number of ShapeSearch queries, and design a natural-language and regex-based parser to automatically parse and translate user queries to the algebra representation. To execute these queries within interactive response times, ShapeSearch uses a fast shape algebra-based execution engine with query-aware optimizations, and perceptually-aware scoring methodologies. We present a thorough evaluation of the system, including a general-purpose user study, a case study involving genomic data analysis, as well as performance experiments, comparing against state-of-the-art time series shape matching approaches—that together demonstrate the usability and scalability of ShapeSearch.
Fenchel Lifted Networks: A Lagrange Relaxation of Neural Network Training
Despite the recent successes of deep neural networks, the corresponding training problem remains highly non-convex and difficult to optimize. Classes of models have been proposed that introduce greater structure to the objective function at the cost of lifting the dimension of the problem. However, these lifted methods sometimes perform poorly compared to traditional neural networks. In this paper, we introduce a new class of lifted models, Fenchel lifted networks, that enjoy the same benefits as previous lifted models, without suffering a degradation in performance over classical networks. Our model represents activation functions as equivalent biconvex constraints and uses Lagrange Multipliers to arrive at a rigorous lower bound of the traditional neural network training problem. This model is efficiently trained using block-coordinate descent and is parallelizable across data points and/or layers. We compare our model against standard fully connected and convolutional networks and show that we are able to match or beat their performance.
A monotone data augmentation algorithm for multivariate nonnormal data: with applications to controlled imputations for longitudinal trials
An efficient monotone data augmentation (MDA) algorithm is proposed for missing data imputation for incomplete multivariate nonnormal data that may contain variables of different types, and are modeled by a sequence of regression models including the linear, binary logistic, multinomial logistic, proportional odds, Poisson, negative binomial, skew-normal, skew-t regressions or a mixture of these models. The MDA algorithm is applied to the sensitivity analyses of longitudinal trials with nonignorable dropout using the controlled pattern imputations that assume the treatment effect reduces or disappears after subjects in the experimental arm discontinue the treatment. We also describe a heuristic approach to implement the controlled imputation, in which the fully conditional specification method is used to impute the intermediate missing data to create a monotone missing pattern, and the missing data after dropout are then imputed according to the assumed nonignorable mechanisms. The proposed methods are illustrated by simulation and real data analyses.
Recurrent Iterative Gating Networks for Semantic Segmentation
In this paper, we present an approach for Recurrent Iterative Gating called RIGNet. The core elements of RIGNet involve recurrent connections that control the flow of information in neural networks in a top-down manner, and different variants on the core structure are considered. The iterative nature of this mechanism allows for gating to spread in both spatial extent and feature space. This is revealed to be a powerful mechanism with broad compatibility with common existing networks. Analysis shows how gating interacts with different network characteristics, and we also show that more shallow networks with gating may be made to perform better than much deeper networks that do not include RIGNet modules.
Learning without Memorizing
Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called ‘Learning without Memorizing (LwM)’, to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers’ attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.
A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data
Nowadays, multivariate time series data are increasingly collected in various real world systems, e.g., power plants, wearable devices, etc. Anomaly detection and diagnosis in multivariate time series refer to identifying abnormal status in certain time steps and pinpointing the root causes. Building such a system, however, is challenging since it not only requires to capture the temporal dependency in each time series, but also need encode the inter-correlations between different pairs of time series. In addition, the system should be robust to noise and provide operators with different levels of anomaly scores based upon the severity of different incidents. Despite the fact that a number of unsupervised anomaly detection algorithms have been developed, few of them can jointly address these challenges. In this paper, we propose a Multi-Scale Convolutional Recurrent Encoder-Decoder (MSCRED), to perform anomaly detection and diagnosis in multivariate time series data. Specifically, MSCRED first constructs multi-scale (resolution) signature matrices to characterize multiple levels of the system statuses in different time steps. Subsequently, given the signature matrices, a convolutional encoder is employed to encode the inter-sensor (time series) correlations and an attention based Convolutional Long-Short Term Memory (ConvLSTM) network is developed to capture the temporal patterns. Finally, based upon the feature maps which encode the inter-sensor correlations and temporal information, a convolutional decoder is used to reconstruct the input signature matrices and the residual signature matrices are further utilized to detect and diagnose anomalies. Extensive empirical studies based on a synthetic dataset and a real power plant dataset demonstrate that MSCRED can outperform state-of-the-art baseline methods.
Gradient-Coherent Strong Regularization for Deep Neural Networks
Deep neural networks are often prone to over-fitting with their numerous parameters, so regularization plays an important role in generalization. L1 and L2 regularizers are common regularization tools in machine learning with their simplicity and effectiveness. However, we observe that imposing strong L1 or L2 regularization on deep neural networks with stochastic gradient descent easily fails, which limits the generalization ability of the underlying neural networks. To understand this phenomenon, we first investigate how and why learning fails when strong regularization is imposed on deep neural networks. We then propose a novel method, gradient-coherent strong regularization, which imposes regularization only when the gradients are kept coherent in the presence of strong regularization. Experiments are performed with multiple deep architectures on three benchmark data sets for image recognition. Experimental results show that our proposed approach indeed endures strong regularization and significantly improves both accuracy and compression, which could not be achieved otherwise.
Parallel Matrix Condensation for Calculating Log-Determinant of Large Matrix
Multiple-Instance Learning by Boosting Infinitely Many Shapelet-based Classifiers
We propose a new formulation of Multiple-Instance Learning (MIL). In typical MIL settings, a unit of data is given as a set of instances called a bag and the goal is to find a good classifier of bags based on similarity from a single or finitely many ‘shapelets’ (or patterns), where the similarity of the bag from a shapelet is the maximum similarity of instances in the bag. Classifiers based on a single shapelet are not sufficiently strong for certain applications. Additionally, previous work with multiple shapelets has heuristically chosen some of the instances as shapelets with no theoretical guarantee of its generalization ability. Our formulation provides a richer class of the final classifiers based on infinitely many shapelets. We provide an efficient algorithm for the new formulation, in addition to generalization bound. Our empirical study demonstrates that our approach is effective not only for MIL tasks but also for Shapelet Learning for time-series classification.
Limited Gradient Descent: Learning With Noisy Labels
Label noise may handicap the generalization of classifiers, and it is an important issue how to effectively learn main pattern from samples with noisy labels. Recent studies have witnessed that deep neural networks tend to prioritize learning simple patterns and then memorize noise patterns. This suggests a method to search the best generalization, which learns the main pattern until the noise begins to be memorized. A natural idea is to use a supervised approach to find the stop timing of learning, for example resorting clean verification set. In practice, however, a clean verification set is sometimes not easy to obtain. To solve this problem, we propose an unsupervised method called limited gradient descent to estimate the best stop timing. We modified the labels of few samples in noisy dataset to be almost false labels as reverse pattern. By monitoring the learning progresses of the noisy samples and the reverse samples, we can determine the stop timing of learning. In this paper, we also provide some sufficient conditions on learning with noisy labels. Experimental results on CIFAR-10 demonstrate that our approach has similar generalization performance to those supervised methods. For uncomplicated datasets, such as MNIST, we add relabeling strategy to further improve generalization and achieve state-of-the-art performance.
Learning to Detect Instantaneous Changes with Retrospective Convolution and Static Sample Synthesis
Change detection has been a challenging visual task due to the dynamic nature of real-world scenes. Good performance of existing methods depends largely on prior background images or a long-term observation. These methods, however, suffer severe degradation when they are applied to detection of instantaneously occurred changes with only a few preceding frames provided. In this paper, we exploit spatio-temporal convolutional networks to address this challenge, and propose a novel retrospective convolution, which features efficient change information extraction between the current frame and frames from historical observation. To address the problem of foreground-specific over-fitting in learning-based methods, we further propose a data augmentation method, named static sample synthesis, to guide the network to focus on learning change-cued information rather than specific spatial features of foreground. Trained end-to-end with complex scenarios, our framework proves to be accurate in detecting instantaneous changes and robust in combating diverse noises. Extensive experiments demonstrate that our proposed method significantly outperforms existing methods.
StarStar Models: Process Analysis on top of Databases
Much time in process mining projects is spent on finding and understanding data sources and extracting the event data needed. As a result, only a fraction of time is spent actually applying techniques to discover, control and predict the business process. Moreover, there is a lack of techniques to display relationships on top of databases without the need to express a complex query to get the required information. In this paper, a novel modeling technique that works on top of databases is presented. This technique is able to show a multigraph representing activities inferred from database events, connected with edges that are annotated with frequency and performance information. The representation may be the entry point to apply advanced process mining techniques that work on classic event logs, as the model provides a simple way to retrieve a classic event log from a specified piece of model. Comparison with similar techniques and an empirical evaluation are provided.
Effect of Depth and Width on Local Minima in Deep Learning
In this paper, we analyze the effects of depth and width on the quality of local minima, without strong over-parameterization and simplification assumptions in the literature. Without any simplification assumption, for deep nonlinear neural networks with the squared loss, we theoretically show that the quality of local minima tends to improve towards the global minimum value as depth and width increase. Furthermore, with a locally-induced structure on deep nonlinear neural networks, the values of local minima of neural networks are theoretically proven to be no worse than the globally optimal values of corresponding classical machine learning models. We empirically support our theoretical observation with a synthetic dataset as well as MNIST, CIFAR-10 and SVHN datasets. When compared to previous studies with strong over-parameterization assumptions, the results in this paper do not require over-parameterization, and instead show the gradual effects of over-parameterization as consequences of general results.
How You See Me
Convolution Neural Networks is one of the most powerful tools in the present era of science. There has been a lot of research done to improve their performance and robustness while their internal working was left unexplored to much extent. They are often defined as black boxes that can map non-linear data very effectively. This paper tries to show how CNN has learned to look at an image. The proposed algorithm exploits the basic math of CNN to backtrack the important pixels it is considering to predict. This is a simple algorithm which does not involve any training of its own over a pre-trained CNN which can classify.
Variance Suppression: Balanced Training Process in Deep Learning
Stochastic gradient descent updates parameters with summation gradient computed from a random data batch. This summation will lead to unbalanced training process if the data we obtained is unbalanced. To address this issue, this paper takes the error variance and error mean both into consideration. The adaptively adjusting approach of two terms trading off is also given in our algorithm. Due to this algorithm can suppress error variance, we named it Variance Suppression Gradient Descent (VSSGD). Experimental results have demonstrated that VSSGD can accelerate the training process, effectively prevent overfitting, improve the networks learning capacity from small samples.
Analysing Results from AI Benchmarks: Key Indicators and How to Obtain Them
Item response theory (IRT) can be applied to the analysis of the evaluation of results from AI benchmarks. The two-parameter IRT model provides two indicators (difficulty and discrimination) on the side of the item (or AI problem) while only one indicator (ability) on the side of the respondent (or AI agent). In this paper we analyse how to make this set of indicators dual, by adding a fourth indicator, generality, on the side of the respondent. Generality is meant to be dual to discrimination, and it is based on difficulty. Namely, generality is defined as a new metric that evaluates whether an agent is consistently good at easy problems and bad at difficult ones. With the addition of generality, we see that this set of four key indicators can give us more insight on the results of AI benchmarks. In particular, we explore two popular benchmarks in AI, the Arcade Learning Environment (Atari 2600 games) and the General Video Game AI competition. We provide some guidelines to estimate and interpret these indicators for other AI benchmarks and competitions.
CGNet: A Light-weight Context Guided Network for Semantic Segmentation

Brain-Inspired Stigmergy Learning
Stigmergy has proved its great superiority in terms of distributed control, robustness and adaptability, thus being regarded as an ideal solution for large-scale swarm control problems. Based on new discoveries on astrocytes in regulating synaptic transmission in the brain, this paper has mapped stigmergy mechanism into the interaction between synapses and investigated its characteristics and advantages. Particularly, we have divided the interaction between synapses which are not directly connected into three phases and proposed a stigmergic learning model. In this model, the state change of a stigmergy agent will expand its influence to affect the states of others. The strength of the interaction is determined by the level of neural activity as well as the distance between stigmergy agents. Inspired by the morphological and functional changes in astrocytes during environmental enrichment, it is likely that the regulation of distance between stigmergy agents plays a critical role in the stigmergy learning process. Simulation results have verified its importance and indicated that the well-regulated distance between stigmergy agents can help to obtain stigmergy learning gain.
Computer-Assisted Fraud Detection, From Active Learning to Reward Maximization
The automatic detection of frauds in banking transactions has been recently studied as a way to help the analysts finding fraudulent operations. Due to the availability of a human feedback, this task has been studied in the framework of active learning: the fraud predictor is allowed to sequentially call on an oracle. This human intervention is used to label new examples and improve the classification accuracy of the latter. Such a setting is not adapted in the case of fraud detection with financial data in European countries. Actually, as a human verification is mandatory to consider a fraud as really detected, it is not necessary to focus on improving the classifier. We introduce the setting of ‘Computer-assisted fraud detection’ where the goal is to minimize the number of non fraudulent operations submitted to an oracle. The existing methods are applied to this task and we show that a simple meta-algorithm provides competitive results in this scenario on benchmark datasets.
Contingency Training
When applied to high-dimensional datasets, feature selection algorithms might still leave dozens of irrelevant variables in the dataset. Therefore, even after feature selection has been applied, classifiers must be prepared to the presence of irrelevant variables. This paper investigates a new training method called Contingency Training which increases the accuracy as well as the robustness against irrelevant attributes. Contingency training is classifier independent. By subsampling and removing information from each sample, it creates a set of constraints. These constraints aid the method to automatically find proper importance weights of the dataset’s features. Experiments are conducted with the contingency training applied to neural networks over traditional datasets as well as datasets with additional irrelevant variables. For all of the tests, contingency training surpassed the unmodified training on datasets with irrelevant variables and even outperformed slightly when only a few or no irrelevant variables were present.
Analytic Network Learning
Based on the property that solving the system of linear matrix equations via the column space and the row space projections boils down to an approximation in the least squares error sense, a formulation for learning the weight matrices of the multilayer network can be derived. By exploiting into the vast number of feasible solutions of these interdependent weight matrices, the learning can be performed analytically layer by layer without needing of gradient computation after an initialization. Possible initialization schemes include utilizing the data matrix as initial weights and random initialization. The study is followed by an investigation into the representation capability and the output variance of the learning scheme. An extensive experimentation on synthetic and real-world data sets validates its numerical feasibility.
T-CGAN: Conditional Generative Adversarial Network for Data Augmentation in Noisy Time Series with Irregular Sampling
In this paper we propose a data augmentation method for time series with irregular sampling, Time-Conditional Generative Adversarial Network (T-CGAN). Our approach is based on Conditional Generative Adversarial Networks (CGAN), where the generative step is implemented by a deconvolutional NN and the discriminative step by a convolutional NN. Both the generator and the discriminator are conditioned on the sampling timestamps, to learn the hidden relationship between data and timestamps, and consequently to generate new time series. We evaluate our model with synthetic and real-world datasets. For the synthetic data, we compare the performance of a classifier trained with T-CGAN-generated data, against the performance of the same classifier trained on the original data. Results show that classifiers trained on T-CGAN-generated data perform the same as classifiers trained on real data, even with very short time series and small training sets. For the real world datasets, we compare our method with other techniques of data augmentation for time series, such as time slicing and time warping, over a classification problem with unbalanced datasets. Results show that our method always outperforms the other approaches, both in case of regularly sampled and irregularly sampled time series. We achieve particularly good performance in case with a small training set and short, noisy, irregularly-sampled time series.
Black-Box Autoregressive Density Estimation for State-Space Models
State-space models (SSMs) provide a flexible framework for modelling time-series data. Consequently, SSMs are ubiquitously applied in areas such as engineering, econometrics and epidemiology. In this paper we provide a fast approach for approximate Bayesian inference in SSMs using the tools of deep learning and variational inference.
Causal Inference by String Diagram Surgery
Extracting causal relationships from observed correlations is a growing area in probabilistic reasoning, originating with the seminal work of Pearl and others from the early 1990s. This paper develops a new, categorically oriented view based on a clear distinction between syntax (string diagrams) and semantics (stochastic matrices), connected via interpretations as structure-preserving functors. A key notion in the identification of causal effects is that of an intervention, whereby a variable is forcefully set to a particular value independent of any prior propensities. We represent the effect of such an intervention as an endofunctor which performs `string diagram surgery’ within the syntactic category of string diagrams. This diagram surgery in turn yields a new, interventional distribution via the interpretation functor. While in general there is no way to compute interventional distributions purely from observed data, we show that this is possible in certain special cases using a calculational tool called comb disintegration. We demonstrate the use of this technique on a well-known toy example, where we predict the causal effect of smoking on cancer in the presence of a confounding common cause. After developing this specific example, we show this technique provides simple sufficient conditions for computing interventions which apply to a wide variety of situations considered in the causal inference literature.
Strong mixed-integer programming formulations for trained neural networks
We present an ideal mixed-integer programming (MIP) formulation for a rectified linear unit (ReLU) appearing in a trained neural network. Our formulation requires a single binary variable and no additional continuous variables beyond the input and output variables of the ReLU. We contrast it with an ideal ‘extended’ formulation with a linear number of additional continuous variables, derived through standard techniques. An apparent drawback of our formulation is that it requires an exponential number of inequality constraints, but we provide a routine to separate the inequalities in linear time. We also prove that these exponentially-many constraints are facet-defining under mild conditions. Finally, we present computational results showing that dynamically separating from the exponential inequalities 1) is much more computationally efficient and scalable than the extended formulation, 2) decreases the solve time of a state-of-the-art MIP solver by a factor of 7 on smaller instances, and 3) nearly matches the dual bounds of a state-of-the-art MIP solver on harder instances, after just a few rounds of separation and in orders of magnitude less time.
On a hypergraph probabilistic graphical model
We propose a directed acyclic hypergraph framework for a probabilistic graphical model that we call Bayesian hypergraphs. The space of directed acyclic hypergraphs is much larger than the space of chain graphs. Hence Bayesian hypergraphs can model much finer factorizations than Bayesian networks or LWF chain graphs and provide simpler and more computationally efficient procedures for factorizations and interventions. Bayesian hypergraphs also allow a modeler to represent causal patterns of interaction such as Noisy-OR graphically (without additional annotations). We introduce global, local and pairwise Markov properties of Bayesian hypergraphs and prove under which conditions they are equivalent. We define a projection operator, called shadow, that maps Bayesian hypergraphs to chain graphs, and show that the Markov properties of a Bayesian hypergraph are equivalent to those of its corresponding chain graph. We extend the causal interpretation of LWF chain graphs to Bayesian hypergraphs and provide corresponding formulas and a graphical criterion for intervention.
A Gray Box Interpretable Visual Debugging Approach for Deep Sequence Learning Model
Deep Learning algorithms are often used as black box type learning and they are too complex to understand. The widespread usability of Deep Learning algorithms to solve various machine learning problems demands deep and transparent understanding of the internal representation as well as decision making. Moreover, the learning models, trained on sequential data, such as audio and video data, have intricate internal reasoning process due to their complex distribution of features. Thus, a visual simulator might be helpful to trace the internal decision making mechanisms in response to adversarial input data, and it would help to debug and design appropriate deep learning models. However, interpreting the internal reasoning of deep learning model is not well studied in the literature. In this work, we have developed a visual interactive web application, namely d-DeVIS, which helps to visualize the internal reasoning of the learning model which is trained on the audio data. The proposed system allows to perceive the behavior as well as to debug the model by interactively generating adversarial audio data point. The web application of d-DeVIS is available at ddevis.herokuapp.com.
Structured Pruning for Efficient ConvNets via Incremental Regularization
Parameter pruning is a promising approach for CNN compression and acceleration by eliminating redundant model parameters with tolerable performance loss. Despite its effectiveness, existing regularization-based parameter pruning methods usually drive weights towards zero with large and constant regularization factors, which neglects the fact that the expressiveness of CNNs is fragile and needs a more gentle way of regularization for the networks to adapt during pruning. To solve this problem, we propose a new regularization-based pruning method (named IncReg) to incrementally assign different regularization factors to different weight groups based on their relative importance, whose effectiveness is proved on popular CNNs compared with state-of-the-art methods.
Gen-Oja: A Simple and Efficient Algorithm for Streaming Generalized Eigenvector Computation
In this paper, we study the problems of principal Generalized Eigenvector computation and Canonical Correlation Analysis in the stochastic setting. We propose a simple and efficient algorithm, Gen-Oja, for these problems. We prove the global convergence of our algorithm, borrowing ideas from the theory of fast-mixing Markov chains and two-time-scale stochastic approximation, showing that it achieves the optimal rate of convergence. In the process, we develop tools for understanding stochastic processes with Markovian noise which might be of independent interest.
Single-Label Multi-Class Image Classification by Deep Logistic Regression
The objective learning formulation is essential for the success of convolutional neural networks. In this work, we analyse thoroughly the standard learning objective functions for multi-class classification CNNs: softmax regression (SR) for single-label scenario and logistic regression (LR) for multi-label scenario. Our analyses lead to an inspiration of exploiting LR for single-label classification learning, and then the disclosing of the negative class distraction problem in LR. To address this problem, we develop two novel LR based objective functions that not only generalise the conventional LR but importantly turn out to be competitive alternatives to SR in single label classification. Extensive comparative evaluations demonstrate the model learning advantages of the proposed LR functions over the commonly adopted SR in single-label coarse-grained object categorisation and cross-class fine-grained person instance identification tasks. We also show the performance superiority of our method on clothing attribute classification in comparison to the vanilla LR function.
A Baseline for Multi-Label Image Classification Using Ensemble Deep CNN
Recent studies on multi-label image classification have been focusing on designing more complex architectures of deep neural networks such as the use of attention mechanism and region proposal networks. Although performance gains have been reported in literature, the backbone deep models of the proposed approaches and the evaluation metrics employed in different works vary, making it difficult to compare with each other fairly. Moreover, due to the lack of properly investigated baselines, the advantage introduced by the proposed techniques in literature are vague. To address these issues, we make a thorough investigation of the mainstream deep convolutional neural network architectures for multi-label image classification and present a strong baseline. With only data augmentation and model ensemble, we achieve better performance than those previously reported on three benchmark datasets. We hope the work presented in this paper will provide insights to the future studies on multi-label image classification.
Sampling Can Be Faster Than Optimization
Optimization algorithms and Monte Carlo sampling algorithms have provided the computational foundations for the rapid growth in applications of statistical machine learning in recent years. There is, however, limited theoretical understanding of the relationships between these two kinds of methodology, and limited understanding of relative strengths and weaknesses. Moreover, existing results have been obtained primarily in the setting of convex functions (for optimization) and log-concave functions (for sampling). In this setting, where local properties determine global properties, optimization algorithms are unsurprisingly more efficient computationally than sampling algorithms. We instead examine a class of nonconvex objective functions that arise in mixture modeling and multi-stable systems. In this nonconvex setting, we find that the computational complexity of sampling algorithms scales linearly with the model dimension while that of optimization algorithms scales exponentially.
WEST: Word Encoded Sequence Transducers
Most of the parameters in large vocabulary models are used in embedding layer to map categorical features to vectors and in softmax layer for classification weights. This is a bottle-neck in memory constraint on-device training applications like federated learning and on-device inference applications like automatic speech recognition (ASR). One way of compressing the embedding and softmax layers is to substitute larger units such as words with smaller sub-units such as characters. However, often the sub-unit models perform poorly compared to the larger unit models. We propose WEST, an algorithm for encoding categorical features and output classes with a sequence of random or domain dependent sub-units and demonstrate that this transduction can lead to significant compression without compromising performance. WEST bridges the gap between larger unit and sub-unit models and can be interpreted as a MaxEnt model over sub-unit features, which can be of independent interest.
• Photorealistic Facial Synthesis in the Dimensional Affect Space• A Smart System for Selection of Optimal Product Images in E-Commerce• Non-invasive thermal comfort perception based on subtleness magnification and deep learning for energy efficiency• Deep Learning for Automated Classification of Tuberculosis-Related Chest X-Ray: Dataset Specificity Limits Diagnostic Performance Generalizability• Automated Pain Detection from Facial Expressions using FACS: A Review• Almost Zero-Resource ASR-free Keyword Spotting using Multilingual Bottleneck Features and Correspondence Autoencoders• Generating a Training Dataset for Land Cover Classification to Advance Global Development• CheMixNet: Mixed DNN Architectures for Predicting Chemical Properties using Multiple Molecular Representations• Applying the swept rule for explicit partial differential equation solutions on heterogeneous computing systems• Generative Model for Material Experiments Based on Prior Knowledge and Attention Mechanism• Use of Enumerative Combinatorics for proving the applicability of an asymptotic stability result on discrete-time SIS epidemics in complex networks• Saliency Supervision: An Intuitive and Effective Approach for Pain Intensity Regression• Finite Mixture Model of Nonparametric Density Estimation using Sampling Importance Resampling for Persistence Landscape• Chemical Structure Elucidation from Mass Spectrometry by Matching Substructures• Accelerating the Evolution of Convolutional Neural Networks with Node-Level Mutations and Epigenetic Weight Initialization• A Two Phase Investment Game for Competitive Opinion Dynamics in Social Networks• An Efficient Optical Flow Based Motion Detection Method for Non-stationary Scenes• Effect of Passive Reflectors for Enhancing Coverage of 28 GHz mmWave Systems in an Outdoor Setting• Study of Multi-Step Knowledge-Aided Iterative Nested MUSIC for Direction Finding• The generalized distance matrix of digraphs• Automatic Three-Dimensional Cephalometric Annotation System Using Three-Dimensional Convolutional Neural Networks• Weierstrass semigroups at every point of the Suzuki curve• IVD-Net: Intervertebral disc localization and segmentation in MRI with a multi-modal UNet• Slum Segmentation and Change Detection : A Deep Learning Approach• ACTT: Automotive CAN Tokenization and Translation• Exact localized and ballistic eigenstates in disordered chaotic spin ladders and the Fermi-Hubbard model• The Navier-Stokes-Vlasov-Fokker-Planck system as a scaling limit of particles in a fluid• Learning to synthesize: splitting and recombining low and high spatial frequencies for image recovery• On the maximal multiplicity of block sizes in a random set partition• Tukey-Inspired Video Object Segmentation• Infinite cographs and chain complete N-free posets• Mitigating Architectural Mismatch During the Evolutionary Synthesis of Deep Neural Networks• Informed MCMC with Bayesian Neural Networks for Facial Image Analysis• Private Selection from Private Candidates• On polycyclic codes over a finite chain ring• Age evolution in the mean field forest fire model via multitype branching processes• Electric vehicle charging during the day or at night: a perspective on carbon emissions• A note on long rainbow arithmetic progressions• Free-Space Optical Communications with Detector Arrays• Generalized Zero-Shot Recognition based on Visually Semantic Embedding• Synthetic Lung Nodule 3D Image Generation Using Autoencoders• End-to-End Retrieval in Continuous Space• Scalable Logo Recognition using Proxies• Stackelberg GAN: Towards Provable Minimax Equilibrium via Multi-Generator Architectures• Explain to Fix: A Framework to Interpret and Correct DNN Object Detector Predictions• A Comparative Study of Computational Aesthetics• Models and Representations of Gaussian Reciprocal and Conditionally Markov Sequences• Visual Font Pairing• Role action embeddings: scalable representation of network positions• Destination-Directed Trajectory Modeling and Prediction Using Conditionally Markov Sequences• Neural Lander: Stable Drone Landing Control using Learned Dynamics• See far with TPNET: a Tile Processor and a CNN Symbiosis• Tracking Control by the Newton-Raphson Flow: Applications to Autonomous Vehicles• Simultaneous 12-Lead Electrocardiogram Synthesis using a Single-Lead ECG Signal: Application to Handheld ECG Devices• Unsupervised Pseudo-Labeling for Extractive Summarization on Electronic Health Records• Coupled Recurrent Models for Polyphonic Music Composition• Optimizing System Quality of Service through Rejuvenation for Long-Running Applications with Real-Time Constraints• QuaRel: A Dataset and Models for Answering Questions about Qualitative Relationships• Variance Reduction in Stochastic Particle-Optimization Sampling• The branching-ruin number as critical parameter of random processes on trees• Model and Integrate Medical Resource Available Times and Relationships in Verifiably Correct Executable Medical Best Practice Guideline Models (Extended Version)• Practical Visual Localization for Autonomous Driving: Why Not Filter?• Model and Integrate Medical Resource Availability into Verifiably Correct Executable Medical Guidelines – Technical Report• Utterance-Based Audio Sentiment Analysis Learned by a Parallel Combination of CNN and LSTM• Reinforcement Learning of Active Vision forManipulating Objects under Occlusions• Representation Learning of Pedestrian Trajectories Using Actor-Critic Sequence-to-Sequence Autoencoder• Midrange crossing constants for graphs classes• Factorized Distillation: Training Holistic Person Re-identification Model by Distilling an Ensemble of Partial ReID Models• Scene Graph Generation via Conditional Random Fields• An empirical evaluation of AMR parsing for legal documents• Lightweight Lipschitz Margin Training for Certified Defense against Adversarial Examples• ChainGAN: A sequential approach to GANs• Optimal Estimation with Complete Subsets of Instruments• Model Learning for Look-ahead Exploration in Continuous Control• A Categorification of the Vandermonde Determinant• Improved Quantum Multicollision-Finding Algorithm• Another Diversity-Promoting Objective Function for Neural Dialogue Generation• Global sensitivity analysis for models described by stochastic differential equations• An interpretable multiple kernel learning approach for the discovery of integrative cancer subtypes• Bi-Adversarial Auto-Encoder for Zero-Shot Learning• Pyramid Embedded Generative Adversarial Network for Automated Font Generation• Faster First-Order Methods for Stochastic Non-Convex Optimization on Riemannian Manifolds• Sequence-based Person Attribute Recognition with Joint CTC-Attention Model• Wireless Communications with Programmable Metasurface: Transceiver Design and Experimental Results• Explaining Latent Factor Models for Recommendation with Influence Functions• Compact Disjunctive Approximations to Nonconvex Quadratically Constrained Programs• Adversarial Feedback Loop• Deep Auto-Set: A Deep Auto-Encoder-Set Network for Activity Recognition Using Wearables• Formal FocusST Specification of CAN• Alignment Analysis of Sequential Segmentation of Lexicons to Improve Automatic Cognate Detection• A Construction of Zero-Difference Functions• Martingale approach to Sobolev embedding theorems• Adversarial point set registration• Stratified pooling games: an extension with optimized stock levels• Reputation System for Online Communities• Machine Learning Distinguishes Neurosurgical Skill Levels in a Virtual Reality Tumor Resection Task• DeepZip: Lossless Data Compression using Recurrent Neural Networks• Weakly Supervised Estimation of Shadow Confidence Maps in Ultrasound Imaging• Unsupervised Learning of Shape Concepts – From Real-World Objects to Mental Simulation• Bayesian Inference for Structural Vector Autoregressions Identified by Markov-Switching Heteroskedasticity• A covariance formula for topological events of smooth Gaussian fields• Sketch-R2CNN: An Attentive Network for Vector Sketch Recognition• Ergodic Poisson Splittings• Attributing Fake Images to GANs: Analyzing Fingerprints in Generated Images• HyperBench: A Benchmark and Tool for Hypergraphs and Empirical Findings• A combinatorial formula for the coefficient of $q$ in Kazhdan-Lusztig polynomials• Approximation Algorithm for the Partial Set Multi-Cover Problem• Orthographic Feature Transform for Monocular 3D Object Detection• Effect of correlation on the traffic capacity of Time Varying Communication Network• SpherePHD: Applying CNNs on a Spherical PolyHeDron Representation of 360 degree Images• Identifiers in Registers – Describing Network Algorithms with Logic• Attentive Neural Architecture Incorporating Song Features For Music Recommendation• Simulating Random Walks on Graphs in the Streaming Model• Rota-Baxter operators on a sum of fields• A Semi-supervised Spatial Spectral Regularized Manifold Local Scaling Cut With HGF for Dimensionality Reduction of Hyperspectral Images• Self Organizing Classifiers: First Steps in Structured Evolutionary Machine Learning• Self Organizing Classifiers and Niched Fitness• Modeling and Optimal Control of an Octopus Tentacle• Event-based High Dynamic Range Image and Very High Frame Rate Video Generation using Conditional Generative Adversarial Networks• Avoiding conjugacy classes on the 5-letter alphabet• A Fast Randomized Geometric Algorithm for Computing Riemann-Roch Spaces• A general framework for handling commitment in online throughput maximization• Geometry of Friston’s active inference• Deep Unfolded Robust PCA with Application to Clutter Suppression in Ultrasound• On double sum generating functions in connection with some classical partition theorems• Transferable Interactiveness Prior for Human-Object Interaction Detection• Average optimal cost for the Euclidean TSP in one dimension• A novel derivation of the Marchenko-Pastur law through analog bipartite spin-glasses• Selective chaos of travelling waves in feedforward chains of bistable maps• Absence of temperature chaos for the 2D discrete Gaussian free field: an overlap distribution different from the random energy model• Counting Words Avoiding a Short Increasing Pattern and the Pattern 1k…2• Stability Based Filter Pruning for Accelerating Deep CNNs• Sensor Adaptation for Improved Semantic Segmentation of Overhead Imagery• Automatic Test Improvement with DSpot: a Study with Ten Mature Open-Source Projects• The asymptotic resolution of a problem of Plesník• On the eigenvalues of truncations of random unitary matrices• Multi-layer Pruning Framework for Compressing Single Shot MultiBox Detector• LGLG-WPCA: An Effective Texture-based Method for Face Recognition• Comprehensive passenger demand-dependent traffic control on a metro line with a junction and a derivation of the traffic phases• Convergence rate of optimal quantization grids and application to empirical measure• Parametrized Nash Equilibria in Atomic Splittable Congestion Games via Weighted Block Laplacians• Design and Analysis of Distributed State Estimation Algorithms Based on Belief Propagation and Applications in Smart Grids• Nonlinear diffusion equations with nonlinear gradient noise• Learning deep kernels for exponential family densities• DNN Transfer Learning from Diversified Micro-Doppler for Motion Classification• Reversing Two-Stream Networks with Decoding Discrepancy Penalty for Robust Action Recognition• An equivalent formulation of the Fan-Raspaud Conjecture and related problems• An analysis of cryptocurrencies conditional cross correlations• Temporal Graph Offset Reconstruction: Towards Temporally Robust Graph Representation Learning• On the Impulsive Formation Control of Spacecraft Under Path Constraints• The critical surface in ballistic annihilation• The Effect of Explicit Structure Encoding of Deep Neural Networks for Symbolic Music Generation• Locally Private Gaussian Estimation• Temporal Shift Module for Efficient Video Understanding• Shape-only Features for Plant Leaf Identification• Shellability of generalized Dowling posets• Deep Convolutional Neural Network for Plant Seedlings Classification• A remark on the characterization of triangulated graphs• Visual SLAM-based Localization and Navigation for Service Robots: The Pepper Case• Homogenisation for anisotropic kinetic random motions• Disorder driven non-Markovianity trends in transverse field Heisenberg chain
Like this:
Like Loading…
Related