Since publishing the monotonic binning function based upon the isotonic regression (https://statcompute.wordpress.com/2017/06/15/finer-monotonic-binning-based-on-isotonic-regression), I’ve received some feedback from peers. A potential concern is that, albeit improving the granularity and predictability, the binning is too fine and might not generalize well in the new data.
In light of the concern, I revised the function by imposing two thresholds, including a minimum sample size and a minimum number of bads for each bin. Both thresholds can be adjusted based on the specific use case. For instance, I set the minimum sample size equal to 50 and the minimum number of bads (and goods) equal to 10 in the example below. (Since the R code can’t be displayed properly in the wordpress, I have to save it as an image. Please feel free to email me if you want the code.)
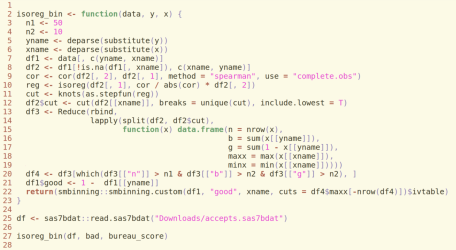
As shown in the output, the number of generated bins and the information value happened to be between the result in (https://statcompute.wordpress.com/2017/06/15/finer-monotonic-binning-based-on-isotonic-regression) and the result in (https://statcompute.wordpress.com/2017/01/22/monotonic-binning-with-smbinning-package). More importantly, given a larger sample size for each bin, the binning algorithm is more robust and generalizable.
Related