Towards ontology based BPMN Implementation
Natural language is understandable by human and not machine. None technical persons can only use natural language to specify their business requirements. However, the current version of Business process management and notation (BPMN) tools do not allow business analysts to implement their business processes without having technical skills. BPMN tool is a tool that allows users to design and implement the business processes by connecting different business tasks and rules together. The tools do not provide automatic implementation of business tasks from users’ specifications in natural language (NL). Therefore, this research aims to propose a framework to automatically implement the business processes that are expressed in NL requirements. Ontology is used as a mechanism to solve this problem by comparing between users’ requirements and web services’ descriptions. Web service is a software module that performs a specific task and ontology is a concept that defines the relationships between different terms.
Addressing the Invisible: Street Address Generation for Developing Countries with Deep Learning
More than half of the world’s roads lack adequate street addressing systems. Lack of addresses is even more visible in daily lives of people in developing countries. We would like to object to the assumption that having an address is a luxury, by proposing a generative address design that maps the world in accordance with streets. The addressing scheme is designed considering several traditional street addressing methodologies employed in the urban development scenarios around the world. Our algorithm applies deep learning to extract roads from satellite images, converts the road pixel confidences into a road network, partitions the road network to find neighborhoods, and labels the regions, roads, and address units using graph- and proximity-based algorithms. We present our results on a sample US city, and several developing cities, compare travel times of users using current ad hoc and new complete addresses, and contrast our addressing solution to current industrial and open geocoding alternatives.
On Training Recurrent Neural Networks for Lifelong Learning
Capacity saturation and catastrophic forgetting are the central challenges of any parametric lifelong learning system. In this work, we study these challenges in the context of sequential supervised learning with emphasis on recurrent neural networks. To evaluate the models in life-long learning setting, we propose a curriculum-based, simple, and intuitive benchmark where the models are trained on a task with increasing levels of difficulty. As a step towards developing true lifelong learning systems, we unify Gradient Episodic Memory (a catastrophic forgetting alleviation approach) and Net2Net (a capacity expansion approach). Evaluation on the proposed benchmark shows that the unified model is more suitable than the constituent models for lifelong learning setting.
Analyzing Compositionality-Sensitivity of NLI Models
Success in natural language inference (NLI) should require a model to understand both lexical and compositional semantics. However, through adversarial evaluation, we find that several state-of-the-art models with diverse architectures are over-relying on the former and fail to use the latter. Further, this compositionality unawareness is not reflected via standard evaluation on current datasets. We show that removing RNNs in existing models or shuffling input words during training does not induce large performance loss despite the explicit removal of compositional information. Therefore, we propose a compositionality-sensitivity testing setup that analyzes models on natural examples from existing datasets that cannot be solved via lexical features alone (i.e., on which a bag-of-words model gives a high probability to one wrong label), hence revealing the models’ actual compositionality awareness. We show that this setup not only highlights the limited compositional ability of current NLI models, but also differentiates model performance based on design, e.g., separating shallow bag-of-words models from deeper, linguistically-grounded tree-based models. Our evaluation setup is an important analysis tool: complementing currently existing adversarial and linguistically driven diagnostic evaluations, and exposing opportunities for future work on evaluating models’ compositional understanding.
Dynamic Type Matching
We consider an intermediary’s problem of dynamically matching demand and supply of heterogeneous types in a periodic-review fashion. More specifically, there are two disjoint sets of demand and supply types, and a reward associated with each possible matching of a demand type and a supply type. In each period, demand and supply of various types arrive in random quantities. The platform’s problem is to decide on the optimal matching policy to maximize the total discounted rewards minus costs, given that unmatched demand and supply will incur waiting or holding costs, and will be carried over to the next period (with abandonment). For this dynamic matching problem, we provide sufficient conditions on matching rewards such that the optimal matching policy follows a priority hierarchy among possible matching pairs. We show those conditions are satisfied by vertically and unidirectionally horizontally differentiated types, for which quality and distance determine priority, respectively. As a result of the priority property, the optimal matching policy boils down to a match-down-to threshold structure when considering a specific pair of demand and supply types in the priority hierarchy.
Symmetry constrained machine learning
Symmetry, a central concept in understanding the laws of nature, has been used for centuries in physics, mathematics, and chemistry, to help make mathematical models tractable. Yet, despite its power, symmetry has not been used extensively in machine learning, until rather recently. In this article we show a general way to incorporate symmetries into machine learning models. We demonstrate this with a detailed analysis on a rather simple real world machine learning system – a neural network for classifying handwritten digits, lacking bias terms for every neuron. We demonstrate that ignoring symmetries can have dire over-fitting consequences, and that incorporating symmetry into the model reduces over-fitting, while at the same time reducing complexity, ultimately requiring less training data, and taking less time and resources to train.
Towards Scalable Subscription Aggregation and Real Time Event Matching in a Large-Scale Content-Based Network
Although many scalable event matching algorithms have been proposed to achieve scalability for large-scale content-based networks, content-based publish/subscribe networks (especially for large-scale real time systems) still suffer performance deterioration when subscription scale increases. While subscription aggregation techniques can be useful to reduce the amount of subscription dissemination traffic and the subscription table size by exploiting the similarity among subscriptions, efficient subscription aggregation is not a trivial task to accomplish. Previous research works have proved that it is either a NP-Complete or a co-NP complete problem. In this paper, we propose DLS (Discrete Label Set), a novel subscription representation model, and design algorithms to achieve the mapping from traditional Boolean predicate model to the DLS model. Based on the DLS model, we propose a subscription aggregation algorithm with O(1) time complexity in most cases, and an event matching algorithm with O(1) time complexity. The significant performance improvement is at the cost of memory consumption and controllable false positive rate. Our theoretical analysis shows that these algorithms are inherently scalable and can achieve real time event matching in a large-scale content-based publish/subscribe network. We discuss the tradeoff between memory, false positive rate and partition granules of content space. Experimental results show that proposed algorithms achieve expected performance. With the increasing of computer memory capacity and the dropping of memory price, more and more large-scale real time applications can benefit from our proposed DLS model, such as stock quote distribution, earthquake monitoring, and severe weather alert.
Deep Comparison: Relation Columns for Few-Shot Learning
Few-shot deep learning is a topical challenge area for scaling visual recognition to open-ended growth in the space of categories to recognise. A promising line work towards realising this vision is deep networks that learn to match queries with stored training images. However, methods in this paradigm usually train a deep embedding followed by a single linear classifier. Our insight is that effective general-purpose matching requires discrimination with regards to features at multiple abstraction levels. We therefore propose a new framework termed Deep Comparison Network (DCN) that decomposes embedding learning into a sequence of modules, and pairs each with a relation module. The relation modules compute a non-linear metric to score the match using the corresponding embedding module’s representation. To ensure that all embedding module’s features are used, the relation modules are deeply supervised. Finally generalisation is further improved by a learned noise regulariser. The resulting network achieves state of the art performance on both miniImageNet and tieredImageNet, while retaining the appealing simplicity and efficiency of deep metric learning approaches.
Integrating domain knowledge: using hierarchies to improve deep classifiers
One of the most prominent problems in machine learning in the age of deep learning is the availability of sufficiently large annotated datasets. While for standard problem domains (ImageNet classification), appropriate datasets exist, for specific domains, \eg classification of animal species, a long-tail distribution means that some classes are observed and annotated insufficiently. Challenges like iNaturalist show that there is a strong interest in species recognition. Acquiring additional labels can be prohibitively expensive. First, since domain experts need to be involved, and second, because acquisition of new data might be costly. Although there exist methods for data augmentation, which not always lead to better performance of the classifier, there is more additional information available that is to the best of our knowledge not exploited accordingly. In this paper, we propose to make use of existing class hierarchies like WordNet to integrate additional domain knowledge into classification. We encode the properties of such a class hierarchy into a probabilistic model. From there, we derive a special label encoding together with a corresponding loss function. Using a convolutional neural network, on the ImageNet and NABirds datasets our method offers a relative improvement of 10.4% and 9.6% in accuracy over the baseline respectively. After less than a third of training time, it is already able to match the baseline’s fine-grained recognition performance. Both results show that our suggested method is efficient and effective.
R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy
Deep Discriminative Learning for Unsupervised Domain Adaptation
The primary objective of domain adaptation methods is to transfer knowledge from a source domain to a target domain that has similar but different data distributions. Thus, in order to correctly classify the unlabeled target domain samples, the standard approach is to learn a common representation for both source and target domain, thereby indirectly addressing the problem of learning a classifier in the target domain. However, such an approach does not address the task of classification in the target domain directly. In contrast, we propose an approach that directly addresses the problem of learning a classifier in the unlabeled target domain. In particular, we train a classifier to correctly classify the training samples while simultaneously classifying the samples in the target domain in an unsupervised manner. The corresponding model is referred to as Discriminative Encoding for Domain Adaptation (DEDA). We show that this simple approach for performing unsupervised domain adaptation is indeed quite powerful. Our method achieves state of the art results in unsupervised adaptation tasks on various image classification benchmarks. We also obtained state of the art performance on domain adaptation in Amazon reviews sentiment classification dataset. We perform additional experiments when the source data has less labeled examples and also on zero-shot domain adaptation task where no target domain samples are used for training.
Monotonic classification: an overview on algorithms, performance measures and data sets
Currently, knowledge discovery in databases is an essential step to identify valid, novel and useful patterns for decision making. There are many real-world scenarios, such as bankruptcy prediction, option pricing or medical diagnosis, where the classification models to be learned need to fulfil restrictions of monotonicity (i.e. the target class label should not decrease when input attributes values increase). For instance, it is rational to assume that a higher debt ratio of a company should never result in a lower level of bankruptcy risk. Consequently, there is a growing interest from the data mining research community concerning monotonic predictive models. This paper aims to present an overview about the literature in the field, analyzing existing techniques and proposing a taxonomy of the algorithms based on the type of model generated. For each method, we review the quality metrics considered in the evaluation and the different data sets and monotonic problems used in the analysis. In this way, this paper serves as an overview of the research about monotonic classification in specialized literature and can be used as a functional guide of the field.
Recurrence to the Rescue: Towards Causal Spatiotemporal Representations

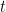

Bayesian Networks, Total Variation and Robustness
Now that Bayesian Networks (BNs) have become widely used, an appreciation is developing of just how critical an awareness of the sensitivity and robustness of certain target variables are to changes in the model. When time resources are limited, such issues impact directly on the chosen level of complexity of the BN as well as the quantity of missing probabilities we are able to elicit. Currently most such analyses are performed once the whole BN has been elicited and are based on Kullback-Leibler information measures. In this paper we argue that robustness methods based instead on the familiar total variation distance provide simple and more useful bounds on robustness to misspecification which are both formally justifiable and transparent. We demonstrate how such formal robustness considerations can be embedded within the process of building a BN. Here we focus on two particular choices a modeller needs to make: the choice of the parents of each node and the number of levels to choose for each variable within the system. Our analyses are illustrated throughout using two BNs drawn from the recent literature.
Stacking-Based Deep Neural Network: Deep Analytic Network for Pattern Classification
Stacking-based deep neural network (S-DNN) is aggregated with pluralities of basic learning modules, one after another, to synthesize a deep neural network (DNN) alternative for pattern classification. Contrary to the DNNs trained end to end by backpropagation (BP), each S-DNN layer, i.e., a self-learnable module, is to be trained decisively and independently without BP intervention. In this paper, a ridge regression-based S-DNN, dubbed deep analytic network (DAN), along with its kernelization (K-DAN), are devised for multilayer feature re-learning from the pre-extracted baseline features and the structured features. Our theoretical formulation demonstrates that DAN/K-DAN re-learn by perturbing the intra/inter-class variations, apart from diminishing the prediction errors. We scrutinize the DAN/K-DAN performance for pattern classification on datasets of varying domains – faces, handwritten digits, generic objects, to name a few. Unlike the typical BP-optimized DNNs to be trained from gigantic datasets by GPU, we disclose that DAN/K-DAN are trainable using only CPU even for small-scale training sets. Our experimental results disclose that DAN/K-DAN outperform the present S-DNNs and also the BP-trained DNNs, including multiplayer perceptron, deep belief network, etc., without data augmentation applied.
The Theory and Algorithm of Ergodic Inference
Approximate inference algorithm is one of the fundamental research fields in machine learning. The two dominant theoretical inference frameworks in machine learning are variational inference (VI) and Markov chain Monte Carlo (MCMC). However, because of the fundamental limitation in the theory, it is very challenging to improve existing VI and MCMC methods on both the computational scalability and statistical efficiency. To overcome this obstacle, we propose a new theoretical inference framework called ergodic Inference based on the fundamental property of ergodic transformations. The key contribution of this work is to establish the theoretical foundation of ergodic inference for the development of practical algorithms in future work.
Statistical Verification of Neural Networks
We present a new approach to neural network verification based on estimating the proportion of inputs for which a property is violated. Specifically, we estimate the probability of the event that the property is violated under an input model. This permits classic verification as a special case, for which one considers only the question of whether this expectation is exactly zero or not. When the property can be violated, our approach provides an informative notion of how robust the network is, rather than just the conventional assertion that the network is not verifiable. Furthermore, it provides an ability to scale to larger networks than classical formal verification approaches. Key to achieving this is an adaptation of multi-level splitting, a Monte Carlo approach for estimating the probability of rare events, to our statistical verification framework. We demonstrate that our approach is able to emulate existing verification procedures on benchmark problems, while scaling to larger networks and providing reliable additional information in the form of accurate estimates of the violation probability.
Deep Dive into Anonymity: A Large Scale Analysis of Quora Questions
Anonymity forms an integral and important part of our digital life. It enables us to express our true selves without the fear of judgment. In this paper, we investigate the different aspects of anonymity in the social Q&A site Quora. The choice of Quora is motivated by the fact that this is one of the rare social Q&A sites that allow users to explicitly post anonymous questions and such activity in this forum has become normative rather than a taboo. Through an analysis of 5.1 million questions, we observe that at a global scale almost no difference manifests between the linguistic structure of the anonymous and the non-anonymous questions. We find that topical mixing at the global scale to be the primary reason for the absence. However, the differences start to feature once we ‘deep dive’ and (topically) cluster the questions and compare the clusters that have high volumes of anonymous questions with those that have low volumes of anonymous questions. In particular, we observe that the choice to post the question as anonymous is dependent on the user’s perception of anonymity and they often choose to speak about depression, anxiety, social ties and personal issues under the guise of anonymity. We further perform personality trait analysis and observe that the anonymous group of users has positive correlation with extraversion, agreeableness, and negative correlation with openness. Subsequently, to gain further insights, we build an anonymity grid to identify the differences in the perception on anonymity of the user posting the question and the community of users answering it. We also look into the first response time of the questions and observe that it is lowest for topics which talk about personal and sensitive issues, which hints toward a higher degree of community support and user engagement.
Reproducing scientists’ mobility: A data-driven model
This paper makes two important contributions to understand the mobility patters of scientists. First, by combining two large-scale data sets covering the publications of 3.5 mio scientists over 60 years, we are able to reveal the geographical ‘career paths’ of scientists. Each path contains, on the individual level, information about the cities (resolved on real geographical space) and the time (in years) spent there. A statistical analysis gives empirical insights into the geographical distance scientists move for a new affiliation and their age when moving. From the individual career paths, we further reconstruct the world network of movements of scientists, where the nodes represent cities and the links in- and out-flow of scientists between cities. We analyze the topological properties of this network with respect to degree distribution, local clustering coefficients, path lengths and assortativity. The second important contribution is an agent-based model that allows to reproduce the empirical findings, both on the level of scientists and of the network. The model considers that agents have a fitness and consider potential new locations if they allow to increase this fitness. Locations on the other hand rank agents against their fitness and consider them only if they still have a capacity for them. This leads to a matching problem which is solved algorithmically. Using empirical data to calibrate our model and to determine its initial conditions, we are able to validate the model against the measured distributions. This allows to interpret the model assumptions as microbased decision rules that explain the observed mobility patterns of scientists.
Validity and Robustness of Tests in Survival Analysis under Covariate-Adaptive Randomization
Covariate-adaptive randomization is popular in clinical trials with sequentially arrived patients for balancing treatment assignments across prognostic factors which may have influence on the response. However, there exists no theoretical work about testing hypotheses under covariate-adaptive randomization in survival analysis, although covariate-adaptive randomization has been used in survival analysis for a long time and its main application is in survival analysis. Often times, practitioners would simply adopt a conventional test such as the log-rank test or score test to compare two treatments, which is controversial since tests derived under simple randomization may not be valid under other randomization schemes. In this article, we prove that the log-rank test valid under simple randomization is conservative in terms of type I error under covariate-adaptive randomization, and the robust score test developed under simple randomization is no longer robust under covariate-adaptive randomization. We then propose a calibration type log-rank or score test that is valid and robust under covariate-adaptive randomization. Furthermore, we obtain Pitman’s efficacy of log-rank and score tests to compare their asymptotic relative efficiency. Simulation studies about the type I error and power of various tests are presented under several popular randomization schemes.
Improving Automatic Source Code Summarization via Deep Reinforcement Learning
Code summarization provides a high level natural language description of the function performed by code, as it can benefit the software maintenance, code categorization and retrieval. To the best of our knowledge, most state-of-the-art approaches follow an encoder-decoder framework which encodes the code into a hidden space and then decode it into natural language space, suffering from two major drawbacks: a) Their encoders only consider the sequential content of code, ignoring the tree structure which is also critical for the task of code summarization, b) Their decoders are typically trained to predict the next word by maximizing the likelihood of next ground-truth word with previous ground-truth word given. However, it is expected to generate the entire sequence from scratch at test time. This discrepancy can cause an \textit{exposure bias} issue, making the learnt decoder suboptimal. In this paper, we incorporate an abstract syntax tree structure as well as sequential content of code snippets into a deep reinforcement learning framework (i.e., actor-critic network). The actor network provides the confidence of predicting the next word according to current state. On the other hand, the critic network evaluates the reward value of all possible extensions of the current state and can provide global guidance for explorations. We employ an advantage reward composed of BLEU metric to train both networks. Comprehensive experiments on a real-world dataset show the effectiveness of our proposed model when compared with some state-of-the-art methods.
Deep Determinantal Point Processes
Determinantal point processes (DPPs) have attracted significant attention as an elegant model that is able to capture the balance between quality and diversity within sets. DPPs are parameterized by a positive semi-definite kernel matrix. While DPPs have substantial expressive power, they are fundamentally limited by the parameterization of the kernel matrix and their inability to capture nonlinear interactions between items within sets. We present the deep DPP model as way to address these limitations, by using a deep feed-forward neural network to learn the kernel matrix. In addition to allowing us to capture nonlinear item interactions, the deep DPP also allows easy incorporation of item metadata into DPP learning. We show experimentally that the deep DPP can provide a considerable improvement in the predictive performance of DPPs.
Quantifying Uncertainties in Natural Language Processing Tasks
Reliable uncertainty quantification is a first step towards building explainable, transparent, and accountable artificial intelligent systems. Recent progress in Bayesian deep learning has made such quantification realizable. In this paper, we propose novel methods to study the benefits of characterizing model and data uncertainties for natural language processing (NLP) tasks. With empirical experiments on sentiment analysis, named entity recognition, and language modeling using convolutional and recurrent neural network models, we show that explicitly modeling uncertainties is not only necessary to measure output confidence levels, but also useful at enhancing model performances in various NLP tasks.
RePr: Improved Training of Convolutional Filters
A well-trained Convolutional Neural Network can easily be pruned without significant loss of performance. This is because of unnecessary overlap in the features captured by the network’s filters. Innovations in network architecture such as skip/dense connections and Inception units have mitigated this problem to some extent, but these improvements come with increased computation and memory requirements at run-time. We attempt to address this problem from another angle – not by changing the network structure but by altering the training method. We show that by temporarily pruning and then restoring a subset of the model’s filters, and repeating this process cyclically, overlap in the learned features is reduced, producing improved generalization. We show that the existing model-pruning criteria are not optimal for selecting filters to prune in this context and introduce inter-filter orthogonality as the ranking criteria to determine under-expressive filters. Our method is applicable both to vanilla convolutional networks and more complex modern architectures, and improves the performance across a variety of tasks, especially when applied to smaller networks.
Understanding Learned Models by Identifying Important Features at the Right Resolution
In many application domains, it is important to characterize how complex learned models make their decisions across the distribution of instances. One way to do this is to identify the features and interactions among them that contribute to a model’s predictive accuracy. We present a model-agnostic approach to this task that makes the following specific contributions. Our approach (i) tests feature groups, in addition to base features, and tries to determine the level of resolution at which important features can be determined, (ii) uses hypothesis testing to rigorously assess the effect of each feature on the model’s loss, (iii) employs a hierarchical approach to control the false discovery rate when testing feature groups and individual base features for importance, and (iv) uses hypothesis testing to identify important interactions among features and feature groups. We evaluate our approach by analyzing random forest and LSTM neural network models learned in two challenging biomedical applications.
Regularized adversarial examples for model interpretability

Stark: Fast and Scalable Strassen’s Matrix Multiplication using Apache Spark
This paper presents a new fast, highly scalable distributed matrix multiplication algorithm on Apache Spark, called Stark, based on Strassen’s matrix multiplication algorithm. Stark preserves Strassen’s 7 multiplications scheme in a distributed environment and thus achieves faster execution. It is based on two new ideas; it creates a recursion tree of computation where each level of such tree corresponds to division and combination of distributed matrix blocks in the form of Resilient Distributed Datasets(RDDs); It processes each divide and combine step in parallel and memorize the sub-matrices by intelligently tagging matrix blocks in it. To the best of our knowledge, Stark is the first Strassen’s implementation in Spark platform. We show experimentally that Stark has a strong scalability with increasing matrix size enabling us to multiply two (16384 x 16384) matrices with 28% and 36% less wall clock time than Marlin and MLLib respectively, state-of-the-art matrix multiplication approaches based on Spark.
Transform-Based Multilinear Dynamical System for Tensor Time Series Analysis
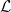
Policy Optimization with Model-based Explorations
Model-free reinforcement learning methods such as the Proximal Policy Optimization algorithm (PPO) have successfully applied in complex decision-making problems such as Atari games. However, these methods suffer from high variances and high sample complexity. On the other hand, model-based reinforcement learning methods that learn the transition dynamics are more sample efficient, but they often suffer from the bias of the transition estimation. How to make use of both model-based and model-free learning is a central problem in reinforcement learning. In this paper, we present a new technique to address the trade-off between exploration and exploitation, which regards the difference between model-free and model-based estimations as a measure of exploration value. We apply this new technique to the PPO algorithm and arrive at a new policy optimization method, named Policy Optimization with Model-based Explorations (POME). POME uses two components to predict the actions’ target values: a model-free one estimated by Monte-Carlo sampling and a model-based one which learns a transition model and predicts the value of the next state. POME adds the error of these two target estimations as the additional exploration value for each state-action pair, i.e, encourages the algorithm to explore the states with larger target errors which are hard to estimate. We compare POME with PPO on Atari 2600 games, and it shows that POME outperforms PPO on 33 games out of 49 games.
Privacy Preserving Utility Mining: A Survey
In big data era, the collected data usually contains rich information and hidden knowledge. Utility-oriented pattern mining and analytics have shown a powerful ability to explore these ubiquitous data, which may be collected from various fields and applications, such as market basket analysis, retail, click-stream analysis, medical analysis, and bioinformatics. However, analysis of these data with sensitive private information raises privacy concerns. To achieve better trade-off between utility maximizing and privacy preserving, Privacy-Preserving Utility Mining (PPUM) has become a critical issue in recent years. In this paper, we provide a comprehensive overview of PPUM. We first present the background of utility mining, privacy-preserving data mining and PPUM, then introduce the related preliminaries and problem formulation of PPUM, as well as some key evaluation criteria for PPUM. In particular, we present and discuss the current state-of-the-art PPUM algorithms, as well as their advantages and deficiencies in detail. Finally, we highlight and discuss some technical challenges and open directions for future research on PPUM.
Temporal Recurrent Networks for Online Action Detection
Most work on temporal action detection is formulated in an offline manner, in which the start and end times of actions are determined after the entire video is fully observed. However, real-time applications including surveillance and driver assistance systems require identifying actions as soon as each video frame arrives, based only on current and historical observations. In this paper, we propose a novel framework, Temporal Recurrent Networks (TRNs), to model greater temporal context of a video frame by simultaneously performing online action detection and anticipation of the immediate future. At each moment in time, our approach makes use of both accumulated historical evidence and predicted future information to better recognize the action that is currently occurring, and integrates both of these into a unified end-to-end architecture. We evaluate our approach on two popular online action detection datasets, HDD and TVSeries, as well as another widely used dataset, THUMOS’14. The results show that TRN significantly outperforms the state-of-the-art.
• An Infinite Parade of Giraffes: Expressive Augmentation and Complexity Layers for Cartoon Drawing• Handwriting Recognition of Historical Documents with few labeled data• Aff-Wild2: Extending the Aff-Wild Database for Affect Recognition• Improving speech emotion recognition via Transformer-based Predictive Coding through transfer learning• A Multi-Task Learning & Generation Framework: Valence-Arousal, Action Units & Primary Expressions• Modelling the Dynamic Joint Policy of Teammates with Attention Multi-agent DDPG• Pareto Optimization for Subset Selection with Dynamic Cost Constraints• Towards Large-Scale Exploratory Search over Heterogeneous Source• Histogram-Free Multicanonical Monte Carlo Sampling to Calculate the Density of States• Optimizing Photonic Nanostructures via Multi-fidelity Gaussian Processes• Stable Gaussian Process based Tracking Control of Lagrangian Systems• Beam Search Decoding using Manner of Articulation Detection Knowledge Derived from Connectionist Temporal Classification• Average Point Pursuit using the Greedy Algorithm: Theory and Applications• On the degree of incompleteness of an incomplete financial market• Sensorless Control of the Levitated Ball• Learned Video Compression• Image Classification at Supercomputer Scale• Data-Efficient Graph Embedding Learning for PCB Component Detection• On the Absence of Replica Symmetry Breaking and Decay of Correlations in the Random Field Ising Model• The Barbados 2018 List of Open Issues in Continual Learning• DifFuzz: Differential Fuzzing for Side-Channel Analysis• Latent Projection BNNs: Avoiding weight-space pathologies by learning latent representations of neural network weights• Robust Control of the Sit-to-Stand Movement for a Powered Lower Limb Orthosis• Coupling weak and strong supervision for classification of prostate cancer histopathology images• Topology-Aware Non-Rigid Point Cloud Registration• Brain Connectivity Impairments and Categorization Disabilities in Autism: A Theoretical Approach via Artificial Neural Networks• Investigating the Effects of Word Substitution Errors on Sentence Embeddings• A multilayer exponential random graph modelling approach for weighted networks• First order k variable logic of sparse random graphs• Improving Rotated Text Detection with Rotation Region Proposal Networks• Mining Entity Synonyms with Efficient Neural Set Generation• The smallest singular value of heavy-tailed not necessarily i.i.d. random matrices via random rounding• Combining Fact Extraction and Verification with Neural Semantic Matching Networks• BLeSS: Bio-inspired Low-level Spatiochromatic Similarity Assisted Image Quality Assessment• RMPflow: A Computational Graph for Automatic Motion Policy Generation• Efficient Neutrino Oscillation Parameter Inference with Gaussian Process• Synergistic Drug Combination Prediction by Integrating Multi-omics Data in Deep Learning Models• Minimum norm solutions do not always generalize well for over-parameterized problems• Domain Adaptive Transfer Learning with Specialist Models• Universal regularization methods – varying the power, the smoothness and the accuracy• Statistical Impact of New York Health Legislation• Relational Long Short-Term Memory for Video Action Recognition• Using Sentiment Induction to Understand Variation in Gendered Online Communities• The Full Spectrum of Deep Net Hessians At Scale: Dynamics with Sample Size• On Nonintersecting $(d,2k)$-conditionally Intersecting Families• Multipath-enabled private audio with noise• Detecting Incongruity Between News Headline and Body Text via a Deep Hierarchical Encoder• DSCnet: Replicating Lidar Point Clouds with Deep Sensor Cloning• Weakly Supervised Semantic Image Segmentation with Self-correcting Networks• An Affect-Rich Neural Conversational Model with Biased Attention and Weighted Cross-Entropy Loss• Bilingual Dictionary Induction for Bantu Languages• Skeleton-based Gesture Recognition Using Several Fully Connected Layers with Path Signature Features and Temporal Transformer Module• PydMobileNet: Improved Version of MobileNets with Pyramid Depthwise Separable Convolution• Use of muscle synergies extracted via higher-order tensor decomposition for proportional myoelectric control• Alternating Segmentation and Simulation for Contrast Adaptive Tissue Classification• Unnamed Entity Recognition of Sense Mentions• A random walk version of Robbins’ problem: small horizon• Leveraging mmWave Imaging and Communications for Simultaneous Localization and Mapping• Sense Perception Common Sense Relationships• Probability density function of SDEs with unbounded and path–dependent drift coefficient• Cross-modality deep learning brings bright-field microscopy contrast to holography• On Hallucinating Context and Background Pixels from a Face Mask using Multi-scale GANs• Detection of Sparse Positive Dependence• Transfer Learning for Mixed-Integer Resource Allocation Problems in Wireless Networks• Boosting the Robustness Verification of DNN by Identifying the Achilles’s Heel• Directional Adaptive MUSIC-like Algorithm under α-Stable Distributed Noise• Simulating LIDAR Point Cloud for Autonomous Driving using Real-world Scenes and Traffic Flows• Unsupervised Online Learning With Multiple Postsynaptic Neurons Based on Spike-Timing-Dependent Plasticity Using a TFT-Type NOR Flash Memory Array• Not just a matter of semantics: the relationship between visual similarity and semantic similarity• Explicit Pose Deformation Learning for Tracking Human Poses• VommaNet: an End-to-End Network for Disparity Estimation from Reflective and Texture-less Light Field Images• Batch Feature Erasing for Person Re-identification and Beyond• High SNR Consistent Compressive Sensing Without Signal and Noise Statistics• The limit distribution of the maximum probability nearest neighbor ball• Learning from power system data stream: phasor-detective approach• High Quality Prediction of Protein Q8 Secondary Structure by Diverse Neural Network Architectures• A simulink circuit model for measurement of consumption of electric energy using frequency method• The Impatient May Use Limited Optimism to Minimize Regret• Robust Website Fingerprinting Through the Cache Occupancy Channel• Extinction time of non-Markovian self-similar processes, persistence, annihilation of jumps and the Fréchet distribution• Edge-Based Blur Kernel Estimation Using Sparse Representation and Self-Similarity• Pacing Equilibrium in First-Price Auction Markets• What Propels Celebrity Follower Counts? Language Use or Social Connectivity• Optical Flow Dataset and Benchmark for Visual Crowd Analysis• A Study of Human Body Characteristics Effect on Micro-Doppler-Based Person Identification using Deep Learning• Link Prediction in Dynamic Graphs for Recommendation• On the local time process of a skew Brownian motion• Batch Self Organizing maps for distributional data using adaptive distances• Optimal Allocations for Sample Average Approximation• Sequential Image-based Attention Network for Inferring Force Estimation without Haptic Sensor• Singularity of Generalized Grey Brownian Motion and Time-Changed Brownian Motion• Eigenvalues of symmetrized shuffling operators• A Greedy approximation scheme for Sparse Gaussian process regression• Recursive Sparse Pseudo-input Gaussian Process SARSA• Additive Manufacturing Graded-material Design based on Phase-field and Topology Optimization• On Human Robot Interaction using Multiple Modes• Emergence of linguistic conventions in multi-agent reinforcement learning• Classifiers Based on Deep Sparse Coding Architectures are Robust to Deep Learning Transferable Examples• Open-vocabulary Phrase Detection• Parameter Sharing Reinforcement Learning Architecture for Multi Agent Driving Behaviors• Machine Learning for Health (ML4H) Workshop at NeurIPS 2018• Induced subgraphs with many repeated degrees• GroundNet: Segmentation-Aware Monocular Ground Plane Estimation with Geometric Consistency• Monotonicity and rigidity of the W-entropy on RCD(0, N) spaces• Learning Features and Abstract Actions for Computing Generalized Plans• Robust cross-domain disfluency detection with pattern match networks• Portfolio Theory, Information Theory and Tsallis Statistics• Representation Mixing for TTS Synthesis• Generalized network recovery based on topology and optimization for real-world systems• Dynamic Interaction Mechanics CrossAnt• PointConv: Deep Convolutional Networks on 3D Point Clouds• Matching RGB Images to CAD Models for Object Pose Estimation• Hitting Probability and the Hausdorff Measure of the Level sets for Spherical Gaussian Fields• Iris Presentation Attack Detection Based on Photometric Stereo Features• Bayesian Modeling of Intersectional Fairness: The Variance of Bias• Optical Flow Based Online Moving Foreground Analysis• Exploit the Connectivity: Multi-Object Tracking with TrackletNet• Modeling Baseball Outcomes as Higher-Order Markov Chains• GLStyleNet: Higher Quality Style Transfer Combining Global and Local Pyramid Features• Integral Equation Approach to Stationary Stochastic Counting Process with Independent Increments• DeepConsensus: using the consensus of features from multiple layers to attain robust image classification• Probabilistic Graphs for Sensor Data-driven Modelling of Power Systems at Scale• Deep Learning with Inaccurate Training Data for Image Restoration• CIFAR10 to Compare Visual Recognition Performance between Deep Neural Networks and Humans• Convolutional-Sparse-Coded Dynamic Mode Decomposition and Its Application to River State Estimation• Image-to-GPS Verification Through A Bottom-Up Pattern Matching Network• GAN-QP: A Novel GAN Framework without Gradient Vanishing and Lipschitz Constraint• A conditional limit theorem for independent random variables• On the geometric median of triangular domains and other median type points• Information Theoretic Bound on Optimal Worst-case Error in Binary Mixture Identification• Enhancing the Robustness of Prior Network in Out-of-Distribution Detection• Algorithmic complexity in Computational Biology• Learning to infer: RL-based search for DNN primitive selection on Heterogeneous Embedded Systems• Asymptotic behaviour of heavy-tailed branching processes in random environments• On Matching Faces with Alterations due to Plastic Surgery and Disguise• Unimodality of the Andrews-Garvan-Dyson cranks of partitions• How many matchings cover the nodes of a graph?• ApproxCS: Near-Sensor Approximate Compressed Sensing for IoT-Healthcare Systems• Radio-wave communication with chaos• Distribution Discrepancy Maximization for Image Privacy Preserving• Second Order Optimality Conditions for Optimal Control Problems of Stochastic Evolution Equations• Well-posedness of Stochastic Riccati Equations and Closed-Loop Solvability for Stochastic Linear Quadratic Optimal Control Problems• Implementation of Robust Face Recognition System Using Live Video Feed Based on CNN• Transfer Learning with Deep CNNs for Gender Recognition and Age Estimation• Optimization on the symplectic group• Ising-PageRank model of opinion formation on social networks• Neural Multi-Task Learning for Citation Function and Provenance• A Tracy-Widom Empirical Estimator For Valid P-values With High-Dimensional Datasets• Shannon meets von Neumann: A Minimax Theorem for Channel Coding in the Presence of a Jammer• Proximity Full-Text Search with a Response Time Guarantee by Means of Additional Indexes• The Taboo Trap: Behavioural Detection of Adversarial Samples• RGB-based 3D Hand Pose Estimation via Privileged Learning with Depth Images• Dynamic Flows with Adaptive Route Choice• Deep Siamese Networks with Bayesian non-Parametrics for Video Object Tracking• Linear Scaling Quantum Transport Methodologies• Taming the latency in multi-user VR 360$^\circ$: A QoE-aware deep learning-aided multicast framework• Facial Expression and Peripheral Physiology Fusion to Decode Individualized Affective Experience
Like this:
Like Loading…
Related