Weighted likelihood mixture modeling and model based clustering
A weighted likelihood approach for robust fitting of a mixture of multivariate Gaussian components is developed in this work. Two approaches have been proposed that are driven by a suitable modification of the standard EM and CEM algorithms, respectively. In both techniques, the M-step is enhanced by the computation of weights aimed at downweighting outliers. The weights are based on Pearson residuals stemming from robust Mahalanobis-type distances. Formal rules for robust clustering and outlier detection can be also defined based on the fitted mixture model. The behavior of the proposed methodologies has been investigated by some numerical studies and real data examples in terms of both fitting and classification accuracy and outlier detection.
Anomaly Analysis for Co-located Datacenter Workloads in the Alibaba Cluster
In warehouse-scale cloud datacenters, co-locating online services and offline batch jobs is an efficient approach to improving datacenter utilization. To better facilitate the understanding of interactions among the co-located workloads and their real-world operational demands, Alibaba recently released a cluster usage and co-located workload dataset, which is the first publicly dataset with precise information about the category of each job. In this paper, we perform a deep analysis on the released Alibaba workload dataset, from the perspective of anomaly analysis and diagnosis. Through data preprocessing, node similarity analysis based on Dynamic Time Warping (DTW), co-located workloads characteristics analysis and anomaly analysis based on iForest, we reveals several insights including: (1) The performance discrepancy of machines in Alibaba’s production cluster is relatively large, for the distribution and resource utilization of co-located workloads is not balanced. For instance, the resource utilization (especially memory utilization) of batch jobs is fluctuating and not as stable as that of online containers, and the reason is that online containers are long-running jobs with more memory-demanding and most batch jobs are short jobs, (2) Based on the distribution of co-located workload instance numbers, the machines can be classified into 8 workload distribution categories1. And most patterns of machine resource utilization curves are similar in the same workload distribution category. (3) In addition to the system failures, unreasonable scheduling and workload imbalance are the main causes of anomalies in Alibaba’s cluster.
Tetris: Re-architecting Convolutional Neural Network Computation for Machine Learning Accelerators
Inference efficiency is the predominant consideration in designing deep learning accelerators. Previous work mainly focuses on skipping zero values to deal with remarkable ineffectual computation, while zero bits in non-zero values, as another major source of ineffectual computation, is often ignored. The reason lies on the difficulty of extracting essential bits during operating multiply-and-accumulate (MAC) in the processing element. Based on the fact that zero bits occupy as high as 68.9% fraction in the overall weights of modern deep convolutional neural network models, this paper firstly proposes a weight kneading technique that could eliminate ineffectual computation caused by either zero value weights or zero bits in non-zero weights, simultaneously. Besides, a split-and-accumulate (SAC) computing pattern in replacement of conventional MAC, as well as the corresponding hardware accelerator design called Tetris are proposed to support weight kneading at the hardware level. Experimental results prove that Tetris could speed up inference up to 1.50x, and improve power efficiency up to 5.33x compared with the state-of-the-art baselines.
A Grammar-Based Structural CNN Decoder for Code Generation
Code generation maps a program description to executable source code in a programming language. Existing approaches mainly rely on a recurrent neural network (RNN) as the decoder. However, we find that a program contains significantly more tokens than a natural language sentence, and thus it may be inappropriate for RNN to capture such a long sequence. In this paper, we propose a grammar-based structural convolutional neural network (CNN) for code generation. Our model generates a program by predicting the grammar rules of the programming language; we design several CNN modules, including the tree-based convolution and pre-order convolution, whose information is further aggregated by dedicated attentive pooling layers. Experimental results on the HearthStone benchmark dataset show that our CNN code generator significantly outperforms the previous state-of-the-art method by 5 percentage points; additional experiments on several semantic parsing tasks demonstrate the robustness of our model. We also conduct in-depth ablation test to better understand each component of our model.
Probabilistic Random Forest: A machine learning algorithm for noisy datasets
Machine learning (ML) algorithms become increasingly important in the analysis of astronomical data. However, since most ML algorithms are not designed to take data uncertainties into account, ML based studies are mostly restricted to data with high signal-to-noise ratio. Astronomical datasets of such high-quality are uncommon. In this work we modify the long-established Random Forest (RF) algorithm to take into account uncertainties in the measurements (i.e., features) as well as in the assigned classes (i.e., labels). To do so, the Probabilistic Random Forest (PRF) algorithm treats the features and labels as probability distribution functions, rather than deterministic quantities. We perform a variety of experiments where we inject different types of noise to a dataset, and compare the accuracy of the PRF to that of RF. The PRF outperforms RF in all cases, with a moderate increase in running time. We find an improvement in classification accuracy of up to 10% in the case of noisy features, and up to 30% in the case of noisy labels. The PRF accuracy decreased by less then 5% for a dataset with as many as 45% misclassified objects, compared to a clean dataset. Apart from improving the prediction accuracy in noisy datasets, the PRF naturally copes with missing values in the data, and outperforms RF when applied to a dataset with different noise characteristics in the training and test sets, suggesting that it can be used for Transfer Learning.
Adversarial Unsupervised Representation Learning for Activity Time-Series
Sufficient physical activity and restful sleep play a major role in the prevention and cure of many chronic conditions. Being able to proactively screen and monitor such chronic conditions would be a big step forward for overall health. The rapid increase in the popularity of wearable devices provides a significant new source, making it possible to track the user’s lifestyle real-time. In this paper, we propose a novel unsupervised representation learning technique called activity2vec that learns and ‘summarizes’ the discrete-valued activity time-series. It learns the representations with three components: (i) the co-occurrence and magnitude of the activity levels in a time-segment, (ii) neighboring context of the time-segment, and (iii) promoting subject-invariance with adversarial training. We evaluate our method on four disorder prediction tasks using linear classifiers. Empirical evaluation demonstrates that our proposed method scales and performs better than many strong baselines. The adversarial regime helps improve the generalizability of our representations by promoting subject invariant features. We also show that using the representations at the level of a day works the best since human activity is structured in terms of daily routines
Stable Tensor Neural Networks for Rapid Deep Learning
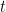
Estimating the Mean and Variance of a High-dimensional Normal Distribution Using a Mixture Prior
Economics of Human-AI Ecosystem: Value Bias and Lost Utility in Multi-Dimensional Gaps
In recent years, artificial intelligence (AI) decision-making and autonomous systems became an integrated part of the economy, industry, and society. The evolving economy of the human-AI ecosystem raising concerns regarding the risks and values inherited in AI systems. This paper investigates the dynamics of creation and exchange of values and points out gaps in perception of cost-value, knowledge, space and time dimensions. It shows aspects of value bias in human perception of achievements and costs that encoded in AI systems. It also proposes rethinking hard goals definitions and cost-optimal problem-solving principles in the lens of effectiveness and efficiency in the development of trusted machines. The paper suggests a value-driven with cost awareness strategy and principles for problem-solving and planning of effective research progress to address real-world problems that involve diverse forms of achievements, investments, and survival scenarios.
Nudging Neural Conversational Model with Domain Knowledge
Neural conversation models are attractive because one can train a model directly on dialog examples with minimal labeling. With a small amount of data, however, they often fail to generalize over test data since they tend to capture spurious features instead of semantically meaningful domain knowledge. To address this issue, we propose a novel approach that allows any human teachers to transfer their domain knowledge to the conversation model in the form of natural language rules. We tested our method with three different dialog datasets. The improved performance across all domains demonstrates the efficacy of our proposed method.
Detecting Irregular Patterns in IoT Streaming Data for Fall Detection
Detecting patterns in real time streaming data has been an interesting and challenging data analytics problem. With the proliferation of a variety of sensor devices, real-time analytics of data from the Internet of Things (IoT) to learn regular and irregular patterns has become an important machine learning problem to enable predictive analytics for automated notification and decision support. In this work, we address the problem of learning an irregular human activity pattern, fall, from streaming IoT data from wearable sensors. We present a deep neural network model for detecting fall based on accelerometer data giving 98.75 percent accuracy using an online physical activity monitoring dataset called ‘MobiAct’, which was published by Vavoulas et al. The initial model was developed using IBM Watson studio and then later transferred and deployed on IBM Cloud with the streaming analytics service supported by IBM Streams for monitoring real-time IoT data. We also present the systems architecture of the real-time fall detection framework that we intend to use with mbientlabs wearable health monitoring sensors for real time patient monitoring at retirement homes or rehabilitation clinics.
A Survey of Challenges for Runtime Verification from Advanced Application Domains (Beyond Software)
Runtime verification is an area of formal methods that studies the dynamic analysis of execution traces against formal specifications. Typically, the two main activities in runtime verification efforts are the process of creating monitors from specifications, and the algorithms for the evaluation of traces against the generated monitors. Other activities involve the instrumentation of the system to generate the trace and the communication between the system under analysis and the monitor. Most of the applications in runtime verification have been focused on the dynamic analysis of software, even though there are many more potential applications to other computational devices and target systems. In this paper we present a collection of challenges for runtime verification extracted from concrete application domains, focusing on the difficulties that must be overcome to tackle these specific challenges. The computational models that characterize these domains require to devise new techniques beyond the current state of the art in runtime verification.
nn-dependability-kit: Engineering Neural Networks for Safety-Critical Systems
nn-dependability-kit is an open-source toolbox to support safety engineering of neural networks. The key functionality of nn-dependability-kit includes (a) novel dependability metrics for indicating sufficient elimination of uncertainties in the product life cycle, (b) formal reasoning engine for ensuring that the generalization does not lead to undesired behaviors, and (c) runtime monitoring for reasoning whether a decision of a neural network in operation time is supported by prior similarities in the training data.
Stochastic Adaptive Neural Architecture Search for Keyword Spotting
The problem of keyword spotting i.e. identifying keywords in a real-time audio stream is mainly solved by applying a neural network over successive sliding windows. Due to the difficulty of the task, baseline models are usually large, resulting in a high computational cost and energy consumption level. We propose a new method called SANAS (Stochastic Adaptive Neural Architecture Search) which is able to adapt the architecture of the neural network on-the-fly at inference time such that small architectures will be used when the stream is easy to process (silence, low noise, …) and bigger networks will be used when the task becomes more difficult. We show that this adaptive model can be learned end-to-end by optimizing a trade-off between the prediction performance and the average computational cost per unit of time. Experiments on the Speech Commands dataset show that this approach leads to a high recognition level while being much faster (and/or energy saving) than classical approaches where the network architecture is static.
Anomaly Detection using Deep Learning based Image Completion
Automated surface inspection is an important task in many manufacturing industries and often requires machine learning driven solutions. Supervised approaches, however, can be challenging, since it is often difficult to obtain large amounts of labeled training data. In this work, we instead perform one-class unsupervised learning on fault-free samples by training a deep convolutional neural network to complete images whose center regions are cut out. Since the network is trained exclusively on fault-free data, it completes the image patches with a fault-free version of the missing image region. The pixel-wise reconstruction error within the cut out region is an anomaly image which can be used for anomaly detection. Results on surface images of decorated plastic parts demonstrate that this approach is suitable for detection of visible anomalies and moreover surpasses all other tested methods.
The MalSource Dataset: Quantifying Complexity and Code Reuse in Malware Development
During the last decades, the problem of malicious and unwanted software (malware) has surged in numbers and sophistication. Malware plays a key role in most of today’s cyber attacks and has consolidated as a commodity in the underground economy. In this work, we analyze the evolution of malware from 1975 to date from a software engineering perspective. We analyze the source code of 456 samples from 428 unique families and obtain measures of their size, code quality, and estimates of the development costs (effort, time, and number of people). Our results suggest an exponential increment of nearly one order of magnitude per decade in aspects such as size and estimated effort, with code quality metrics similar to those of benign software. We also study the extent to which code reuse is present in our dataset. We detect a significant number of code clones across malware families and report which features and functionalities are more commonly shared. Overall, our results support claims about the increasing complexity of malware and its production progressively becoming an industry.
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
GPipe is a scalable pipeline parallelism library that enables learning of giant deep neural networks. It partitions network layers across accelerators and pipelines execution to achieve high hardware utilization. It leverages recomputation to minimize activation memory usage. For example, using partitions over 8 accelerators, it is able to train networks that are 25x larger, demonstrating its scalability. It also guarantees that the computed gradients remain consistent regardless of the number of partitions. It achieves an almost linear speed up without any changes in the model parameters: when using 4x more accelerators, training the same model is up to 3.5x faster. We train a 557 million parameters AmoebaNet model on ImageNet and achieve a new state-of-the-art 84.3% top-1 / 97.0% top-5 accuracy on ImageNet. Finally, we use this learned model as an initialization for training 7 different popular image classification datasets and obtain results that exceed the best published ones on 5 of them, including pushing the CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.
DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules

• Towards a Science of Mind• Improving Fingerprint Pore Detection with a Small FCN• Mathematical Modeling of Arterial Blood Pressure Using Photo-Plethysmography Signal in Breath-hold Maneuver• The Trace Criterion for Kernel Bandwidth Selection for Support Vector Data Description• Discretized Sum-product and Fourier decay in $\mathbb{R}^n$• Granularity and Generalized Inclusion Functions – Their Variants and Contamination• Seq2Seq Mimic Games: A Signaling Perspective• On enumerating factorizations in reflection groups• Automatic Text Document Summarization using Semantic-based Analysis• A General Economic Dispatch Problem with Marginal Losses• Non null controllability of Stokes equations with memory• Subspace Clustering through Sub-Clusters• CAN: Composite Appearance Network and a Novel Evaluation Metric for Person Tracking• Infinite-Horizon Gaussian Processes• Reduced Order Model Predictive Control For Setpoint Tracking• On Generality and Knowledge Transferability in Cross-Domain Duplicate Question Detection for Heterogeneous Community Question Answering• Unconstrained Submodular Maximization with Constant Adaptive Complexity• Conditional GANs for Multi-Illuminant Color Constancy: Revolution or Yet Another Approach?• A Spectral View of Adversarially Robust Features• Fluctuation theory for Lévy processes with completely monotone jumps• Streaming End-to-end Speech Recognition For Mobile Devices• Concept-Oriented Deep Learning: Generative Concept Representations• The Utility of Sparse Representations for Control in Reinforcement Learning• Context-Dependent Upper-Confidence Bounds for Directed Exploration• A note on hyperparameters in black-box adversarial examples• Information Theoretic Limits for Standard and One-Bit Compressed Sensing with Graph-Structured Sparsity• Massive Scaling Limit of the Ising Model: Subcritical Analysis and Isomonodromy• Detecting The Objects on The Road Using Modular Lightweight Network• Mean Square Prediction Error of Misspecified Gaussian Process Models• Investigating Bell Inequalities for Multidimensional Relevance Judgments in Information Retrieval• Stability of Gaussian Process State Space Models• Gaussian Process based Passivation of a Class of Nonlinear Systems with Unknown Dynamics• Importance of the window function choice for the predictive modelling of memristors• Asymptotics for Small Nonlinear Price Impact: a PDE Homogenization Approach to the Multidimensional Case• Equilibrium Distributions and Stability Analysis of Gaussian Process State Space Models• Neural network state estimation for full quantum state tomography• Stable Model-based Control with Gaussian Process Regression for Robot Manipulators• Optical Flow Based Background Subtraction with a Moving Camera: Application to Autonomous Driving• To stay discovered: On tournament mean score sequences and the Bradley–Terry model• Spatial-temporal Multi-Task Learning for Within-field Cotton Yield Prediction• Ground Plane Polling for 6DoF Pose Estimation of Objects on the Road• Evolutionary Game for Consensus Provision in Permissionless Blockchain Networks with Shard• Composite Binary Decomposition Networks• AclNet: efficient end-to-end audio classification CNN• The Potential of Learned Index Structures for Index Compression• HSCS: Hierarchical Sparsity Based Co-saliency Detection for RGBD Images• Deep Knockoffs• Subtask Gated Networks for Non-Intrusive Load Monitoring• Exploring Media Bias and Toxicity in South Asian Political Discourse• DeRPN: Taking a further step toward more general object detection• An ODE Method to Prove the Geometric Convergence of Adaptive Stochastic Algorithms• Concept of round non-flat thin film solar cells and their power conversion efficiency calculation• Fixed Point Quasiconvex Subgradient Method• Graphs with Flexible Labelings allowing Injective Realizations• An Algorithmic Perspective on Imitation Learning• Outage Analysis of $2\times2 $ MIMO-MRC in Correlated Rician Fading• Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization• Joint Range and Angle Estimation for FMCW MIMO Radar and Its Application• Universal graph for graphs with cutwidth at most 2• Robust recoverable 0-1 optimization problems under polyhedral uncertainty• Inhomogeneous Restricted Lattice Walks• Location-Verification and Network Planning via Machine Learning Approaches• On central Fubini-like numbers and polynomials• Incentivizing the Dynamic Workforce: Learning Contracts in the Gig-Economy• Error correcting codes from sub-exceeding fonction• Measuring Majority Power and Veto Power of Voting Rules• Machine Decisions and Human Consequences• Compact I/O-Efficient Representation of Separable Graphs and Optimal Tree Layouts• Itô vs Stratonovich in the presence of absorbing states• All roads lead to Rome: Many ways to double spend your cryptocurrency• Minor-Obstructions for Apex-Pseudoforests• Entropy-regularized Optimal Transport Generative Models• Strongly regular graphs from integral point sets in even dimensional affine spaces over finite fields• Technical Analysis and Discrete False Discovery Rate: Evidence from MSCI Indices• A Novel Approach to Sparse Inverse Covariance Estimation Using Transform Domain Updates and Exponentially Adaptive Thresholding• Reconstructing Tree-Child Networks from Reticulate-Edge-Deleted Subnetworks• A new centered spatio-temporal autologistic regression model. Application to spatio-temporal analysis of esca disease in a vineyard• DropFilter: A Novel Regularization Method for Learning Convolutional Neural Networks• PRAMs over integers do not compute maxflow efficiently• Higher order asymptotics for Large Deviations• Progressive Algorithms for Domination and Independence• PaccMann: Prediction of anticancer compound sensitivity with multi-modal attention-based neural networks• A ($4/3+ε$)-Approximation Algorithm for Arboricity From Pseudoforest Partitions• Evolutionary Diversity Optimization Using Multi-Objective Indicators• Using recurrences in time and frequency within U-net architecture for speech enhancement• Fixation properties of multiple cooperator configurations on regular graphs• Sequential games and nondeterministic selection functions• Gaussian fluctuations of the determinant of Wigner Matrices• Evaluating Uncertainty Quantification in End-to-End Autonomous Driving Control• Tangles are decided by weighted vertex sets• Minimal linear codes in odd characteristic• Estimation from Quantized Gaussian Measurements: When and How to Use Dither• On the Parameter Estimation of the Generalized Exponential Distribution Under Progressive Type-I Interval Censoring Scheme• SoundSignaling: Realtime, Stylistic Modification of a Personal Music Corpus for Information Delivery• Learning Where to Fixate on Foveated Images• Nearly ETH-Tight Algorithms for Planar Steiner Tree with Terminals on Few Faces• Residual Convolutional Neural Network Revisited with Active Weighted Mapping• The Perfect Match: 3D Point Cloud Matching with Smoothed Densities• On the Homogenized Linial Arrangement: Intersection Lattice and Genocchi Numbers• Ontology based Approach for Precision Agriculture• A generalized meta-loss function for distillation and learning using privileged information for classification and regression• On the Complexity of Exploration in Goal-Driven Navigation• A tight kernel for computing the tree bisection and reconnection distance between two phylogenetic trees• Bayesian learning for the Markowitz portfolio selection problem• Well-posedness for some non-linear diffusion processes and related PDE on the Wasserstein space• On the rational Turán exponents conjecture• Pre-training Graph Neural Networks with Kernels• Exact Recovery in the Hypergraph Stochastic Block Model: a Spectral Algorithm• Efficient Construction of a Complete Index for Pan-Genomics Read Alignment• Image Pre-processing Using OpenCV Library on MORPH-II Face Database• On the law of the minimum of the solutions to a class of unidimensional SDEs• Mode Variational LSTM Robust to Unseen Modes of Variation: Application to Facial Expression Recognition• Stable graphs: distributions and line-breaking construction• Automatic Paper Summary Generation from Visual and Textual Information• High-sensitivity high-speed compressive spectrometer for Raman imaging• Exploring Gameplay With AI Agents• Grasp2Vec: Learning Object Representations from Self-Supervised Grasping• Adaptive Thouless-Anderson-Palmer equation for higher-order Markov random fields
Like this:
Like Loading…
Related