What is object detection?
As a subset of computer vision, object detection is an automated method for locating interesting objects in an image with respect to the background. For example, Figure 1 shows two images with objects in the foreground. There is a bird in the left image, while there is a dog and a person in the right image.
Solving the object detection problem means placing a tight bounding box around these objects and associating the correct object category with each bounding box. Like other computer vision tasks, deep learning is the state-of-art method to perform object detection.

Figure 1. The Concept of Object DetectionImage source: https://www.flickr.com/photos/fab_photos_canine_et_sportive/41701235441/https://www.flickr.com/photos/santamonicamtns/19473214154/
How object detection works
A key issue for object detection is that the number of objects in the foreground can vary across images. But to understand how object detection works, let’s first consider restricting the object detection problem by assuming that there is only one object per image. If there is only one object per image, finding a bounding box and categorizing the object can be solved in a straightforward manner. The bounding box consists of four numbers, so learning the bounding box location can naturally be modeled as a regression problem. From there, categorizing the object is a classification problem.
The convolutional neural network (CNN) shown in Figure 2 provides a solution to the regression and classification problems for our restricted object detection problem. Like other traditional computer vision tasks such as image recognition, key points detection, and semantic segmentation, our restricted object detection problem deals with a fixed number of targets. These targets can be fit, by modeling the targets as a fixed number of classification or regression problems.
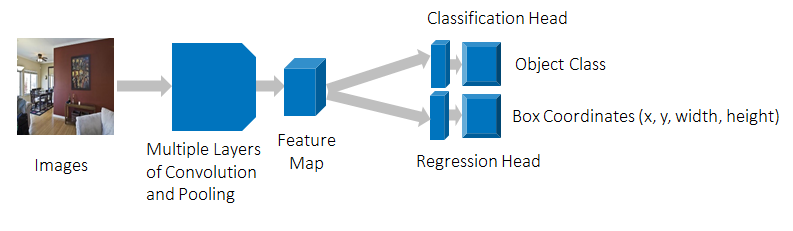
Figure 2. Network architecture to detect one object in the image
As already noted, true object detection must be able to deal with N objects, where N varies from image to image. Unfortunately, the CNN shown in Figure 2 cannot solve this more general problem. It may be possible to use a variant of the CNN by hypothesizing many rectangle box locations and sizes and simply use the CNN for object classification. We often refer to these rectangle boxes as windows. To be comprehensive, the window hypotheses must cover all possible locations and sizes in the image. For each window size and location, a decision can be made on whether there is an object present, and if so, the category for the object.
Figure 3. shows some of the possible windows when realizing object detection by this approach. Since there is a discrete number of pixels in the image, the total number of windows is a huge but countable number. However, this approach is computationally impractical given the huge number of windows to consider.
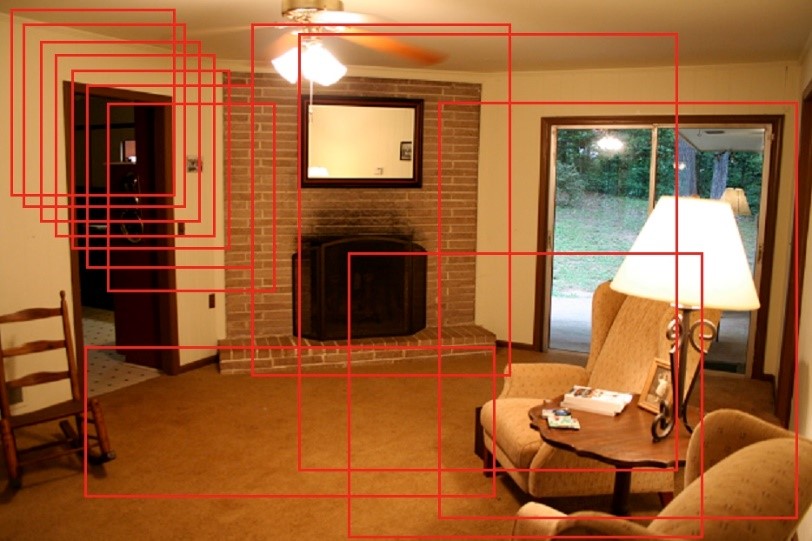
Figure 3. Some of the Possible Windows in Sliding Window ApproachImage source:https://www.flickr.com/photos/nate/482673741/
Efficient methods to look for objects with windows
Can we do object detection in a smart way by only looking at some of the windows? The answer is yes. There are two approaches to find this subset of windows, which lead to two different categories of object detection algorithms.
-
The first algorithm category is to do region proposal first. This means regions highly likely to contain an object are selected either with traditional computer vision techniques (like selective search), or by using a deep learning-based region proposal network (RPN). Once you have gathered the small set of candidate windows, you can formulate a set number of regression models and classification models to solve the object detection problem. This category includes algorithms like Faster R-CNN[1], R_FCN[2] and FPN-FRCN[3]. Algorithms in this category are usually called two-stage methods. They are generally more accurate, but slower than the single-stage method we introduce below.
-
The second algorithm category only looks for objects at fixed locations with fixed sizes. These locations and sizes are strategically selected so that most scenarios are covered. These algorithms usually separate the original images into fixed size grid regions. For each region, these algorithms try to predict a fixed number of objects of certain, pre-determined shapes and sizes. Algorithms belonging to this category are called single-stage methods. Examples of such methods include YOLO[4], SSD[5] and RetinaNet[6]. Algorithms in this category usually run faster but are less accurate. This type of algorithm is often utilized for applications requiring real-time detection.
We’ll discuss two common object detection methods below in more detail.
YOLO
YOLO (You Only Look Once) is the representative algorithm in single-stage object detection method. The steps it follows to detect objects are represented in Figure 4 and in the list below:

Figure 4. YOLO Object Detection Algorithm
-
Separate the original image into grids of equal size.
-
For each grid, predict a preset number of bounding boxes with predefined shapes centered around the grid center. Each prediction is associate with a class probability and an object confidence (whether it contains an object, or it is just the background).
-
Finally, select those bounding boxes associated with high object confidence and class probability. The object category is the object class with the highest class probability.
The preset number of bounding boxes with pre-defined shapes are called anchor boxes. They are obtained from the data by the K-means algorithm. The anchor box captures prior knowledge about object size and shape in the data set. Different anchors are designed to detect objects with different sizes and shapes. For example, in Figure 5, there are three anchors at one location. The red anchor box turns out to detect the person in the middle. In other words, the algorithm detects the object with the approximate size of this anchor box. The final prediction is usually different from the anchor location or size itself, an optimized offset obtained from the feature map of the image is added to the anchor location or size.

Figure 5. Anchor BoxesImage source: https://www.flickr.com/photos/762_photo/16751321393/
The architecture of the YOLO algorithm is shown in Figure 6. The detection layer contains many regression and classification optimizers, and the number is determined by the number of anchors.
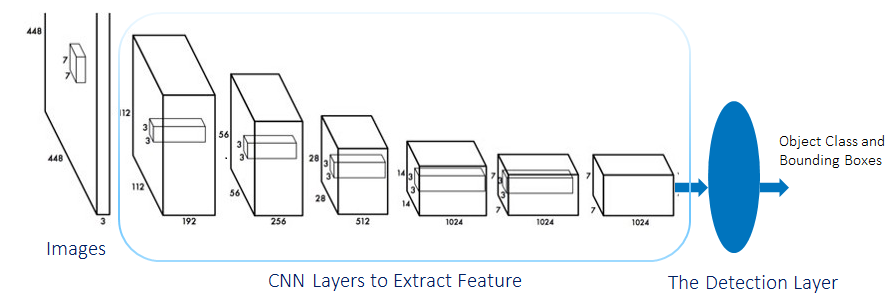
Figure 6 YOLO Network Architecture
Faster RCNN
Faster RCNN [1] is a two-stage object detection algorithm. Figure 7 illustrates the two stages in faster RCNN. Although “faster” is included in the algorithm name, that does not mean that it is faster than the one-stage method. The name is a historical artifact – it simply indicates that it is faster than it is previous versions, the original RCNN algorithm [7], and the Fast RCNN [8], by sharing the computation of feature extraction for each region of interest (RoI), and by introducing the deep learning-based region proposal network (RPN).
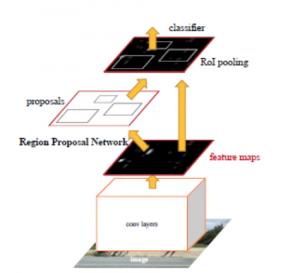
Figure 7. Faster RCNN Stages (Picture from the Original Faster RCNN Paper [1])