Introduction These past few weeks I’ve been writing about a new package I created, MCHT. Those blog posts were basically tutorials demonstrating how to use the package. (Read the first in the series here.) I’m done for now explaining the technical details of the package. Now I’m going to use the package for purpose I initially had: exploring the distribution of time separating U.S. economic recessions.
I wrote about this before. I suggested that the distribution of times between recessions can be modeled with a Weibull distribution, and based on this, a recession was likely to occur prior to the 2020 presidential election.
This claim raised eyebrows, and I want to respond to some of the comments made. Now, I would not be surprised to find this post the subject of an R1 on r/badeconomics, and I hope that no future potential employer finds this (or my previous) post, reads it, and then decides I’m an idiot and denies me a job. I don’t know enough to dogmatically subscribe to the idea but I do want to explore it. Blog posts are not journal articles, and I think this is a good space for me to make arguments that could be wrong and then see how others more intelligent than myself respond. The act of keeping a blog is good for me and my learning (which never ends).
Past Responses
My previous post on the distribution of times between recessions was… controversial. Have a look at the comments section of the original article and the comments of this reddit thread. Here is my summarization of some of the responses:
-
There was no statistical test for the goodness-of-fit of the Weibull distribution.
-
No data generating process (DGP) was proposed, in the sense that there’s no explanation for why the Weibull distribution would be appropriate, or the economic processes that produce memory in the distribution of times between recessions.
-
Isn’t it strange to suggest that other economic variables are irrelevant to when a recession occurs? That seems counterintuitive.
-
MAGA! (actually there were no MAGAs, thankfully)
Then there was this comment, by far the harshest one, by u/must_not_forget_pwd:
The idea that recessions are dependent on time is genuinely laughable. It is an idea that seems to be getting some traction in the chattering classes, who seem more interested in spewing forth political rantings rather than even the semblance of serious analysis. This also explains why no serious economist talks about the time and recession relationship. The lack of substance behind this time and recession idea is revealed by asking some very basic questions and having a grasp of some basic data. If recessions were so predictable, wouldn’t recessions be easy to prevent? Monetary and fiscal policies could be easily manipulated so as to engineer a persistent boom. Also, if investors could correctly predict the state of the economy it would be far easier for them to determine when to invest and to capture the subsequent boom. That is, invest in the recession, when goods and services are cheaper and have the project come on stream during the following boom and make a massive profit. If enough investors acted like this, there would be no recession to begin with due to the increase in investment. Finally, have a look at the growth of other countries. Australia hasn’t had two consecutive quarters of negative growth since the 1990-91 recession. Sure there have been hiccups along the way for Australia, such as the Asian Financial Crisis, the introduction of the GST, a US recession in the early 2000s, and more recently the Global Financial Crisis. Yet, Australia has managed to persist without a recession despite the passage of time. No one in Australia would take you seriously if you said that recessions were time dependent. If these “chattering classes” were interested in even half serious analysis of the US economy, while still wanting to paint a bleak picture, they could very easily look at what is going on right now. Most economists have the US economy growing above trend. This can be seen in the low unemployment rate and that inflation is starting to pickup. Sure wages growth is subdued, but wages growth should be looking to pickup anytime now. However, during this period the US government is injecting a large amount of fiscal stimulus into the US economy through tax cuts. Pumping large amounts of cash into the economy during a boom isn’t exactly a good thing to do and is a great way to overheat the economy and bring about higher inflation. This higher inflation would then cause the US Federal Reserve to react by increasing interest rates. This in turn could spark a US recession. Instead of this very simple and defensible story that requires a little bit of homework, we get subjected to this nonsense that recessions are linked to time. I think it’s time that people call out as nonsense the “analysis” that this blog post has. TL;DR: The idea that recessions are dependent on time is dumb, and if recessions were so easy to predict would mean that recessions wouldn’t exist. This doesn’t mean that a US recession couldn’t happen within the next few years, because it is easy to see how one could occur.
I think that the tone of this message could have been… nicer. That said, I generally welcome direct, harsh criticism, as I often learn a lot from it, or at least am given a lot to think about.
So let’s discuss these comments.
Goodness of Fit of the Weibull Distribution
First, a statistical test for the goodness of fit of the Weibull distribution. I personally was satisfied looking at the plots I made, but some people want a statistical test. The test that comes to mind is the Kolmogorov-Smirnov test, and R does support the simplest version of this test via ks.test(), but when you don’t know all of the parameters of the distribution assumed under the null hypothesis, then you cannot use ks.test(). This is because the test was derived assuming there were no unknown parameters; when nuisance parameters are present and need to be estimated, then the distribution used to compute 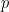
Good news, though; MCHT allows us to do the test properly! First, let’s get set up.
I already demonstrated how to perform a bootstrap version of the Kolmogorov-Smirnov test in one of my blog posts about MCHT, and the code below is basically a direct copy of that code. While the test is not exact, it should be asymptotically appropriate.
The test does not reject the null hypothesis; there isn’t evidence that the data is not following a Weibull distribution (according to that test; read on).
Compare this to the Kolmogorov-Smirnov test checking whether the data follows the exponential distribution.
Here, the null hypothesis is rejected; there is evidence that the data wasn’t drawn from an exponential distribution.
What do the above two results signify? If we assume that the time between recessions is independent and identically distributed, then there is not evidence against the Weibull distribution, but there is evidence against the exponential distribution. (The exponential distribution is actually a special case of the Weibull distribution, so the second test effectively rules out that special case.) The exponential distribution has the memoryless property; if we say that the time between events follows an exponential distribution, then knowing that it’s been 
We will revisit the goodness of fit later, though.
How Recessions Occur
I do have some personal beliefs about what causes recessions to occur that would lead me to think that the time between recessions does exhibit some form of memory and would also address the point raised by u/must_not_forget_pwd about Australia not having had a recession in decades. This perspective is primarily shaped by two books, [1] and [2].
In short, I agree with the aforementioned reddit user; recessions are not inevitable. The stability of an economy is a characteristic of that economy and some economies are more stable than others. [1] notes that the Canadian economy had a dearth of banking crises in the 19th and 20th centuries, with the most recent one effectively due to the 2008 crisis in the United States. Often the stability of the financial sector (and probably the economy as a whole) is strongly related to the political coalition responsible for drafting the de facto rules that the financial system follows. In some cases the financial sector is politically weak and continuously plundered by the government. Sometimes it’s politically weak and allowed to exist unmolested by the government but is well whipped. Financiers are allowed to make money and the government repays its debts but if the financial sector steps out of line and takes on too much risk it will be punished. And then there’s the situation where the financial sector is politically powerful and able to get away with bad behavior, perhaps even being rewarded for that behavior by government bailouts. That’s the financial system the United States has.
So let’s consider the latter case, where the financial sector is politically powerful. This is where the Minsky narrative (see [2]) takes hold. He describes a boom-and-bust cycle, but critically, the cause of the bust was built into the boom. After a bust, many in the financial sector “learn their lesson” and become more conservative risk-takers. In this regime the economy recovers and some growth resumes. Over time, the financial sector “forgets” the lessons it learned from the previous bust and begins to take greater risks. Eventually these risks become so great that a greater systematic risk appears and the financial sector, as a whole, stands on shaky ground. Something goes wrong (like the bottom falls out of the housing market or the Russian government defaults), the bets taken by the financial sector go the wrong way, and a crisis ensues. The extra wrinkle in the American financial system is that the financial sector not only isn’t punished for the risks they’ve taken, they get rewarded with a bailout financed by taxpayers and the executives who made those decisions get golden parachutes (although there may be a trivial fine).
If the Minsky narrative is correct, then economic booms do die of “old age”, as eventually the boom is driven by increasingly risky behavior that eventually leads to collapse. When the government is essentially encouraging this behavior with blank-check guarantees, the risks taken grow (risky contracts become lotto tickets paid for by someone else when you lose, but you get all the winnings). Taken together, one can see why there could be some form of memory in the time between recessions. Busts are an essential feature of such an economy.
So what about the Australian economy, as u/must_not_forget_pwd brought up? In short, I think the Australian economy is prototyped by the Canadian economy as described in [1] and thus doesn’t follow the rules driving the boom/bust cycle in America. I think the Australian economy is the Australian economy and the American economy is the American economy. One is stable, the other is not. I’m studying the unstable one, not trying the explain the stability of the other.
Are Other Variables Irrelevant?
First, does time matter to when a recession occurs? The short answer is “Yes, duh!” If you’re going to have any meaningful discussion about when a recession will occur you have to account for the time frame you’re considering. A recession within the next 30 years is much more likely than a recession in the next couple months (if only because one case covers the other, but in general a recession should be more likely to occur within a longer period of time than a shorter one).
But I think the question about “does time matter” is more a question about whether an economy essentially remembers how long it has been since the last recession or not. That’s both an economic and statistical question.
What about other variables? Am I saying that other variables don’t matter when I use only time to predict when the next recession occurs? No, that’s not what I’m saying.
Let’s consider regression equations, often of the form

I think economists are used to thinking about equations like this as essentially causal statements, but that’s not what a regression equation is, and when we estimate a regression equation we are not automatically estimating a function that needs to be interpreted causally. If a regression equation tells us something about causality, that’s great, but that’s not what they do.
Granted, economics students are continuously being reminded the correlation is not causation, but I think many then start to think that we should not compute a regression equation unless the relationship expressed can be interpreted causally. However, knowing that two variables are correlated, and how they are correlated, is often useful.
When we compute a regression function from data, we are computing a function that estimates conditional expectations. This function, when given the value of one variable, tells us what value we can expect for the other variable. That relationship may or may not be due to causality, but the fact that the two variables are not independent of each other can be, in and of itself, a useful fact.
My favorite example in the “correlation is not causation” discussion (probably mentioned first in some econometrics textbook or my econometrics professor) is the relationship between the damage caused by a fire and the number of firefighters at the scene of the fire. Let’s just suppose that we have some data, 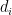


There is a positive relationship between the number of firefighters at the scene of the fire and the damage done by the fire. Does this mean that firefighters make fires worse? No, it does not. But if you’re a spectator and you see ten firefighters running the scene of a fire, can you expect the fire to be more damaging than fires where there are five firefighters and not as damaging as fires with fifteen firefighters? Sure, this is reasonable. Not only that, it’s a useful fact to know.
Importantly, when we choose the variables to include in a regression equation, we are deciding what variables we want to use for conditioning. That choice could be motivated by a causal model (because we care about causality), or by model fit (making the smallest error in our predictions while being sufficiently simple), or simply by what’s available. Some models may do better than others at predicting a variable but they all do the same thing: compute conditional expectations.
My point is this: when I use time as the only variable of interest when attempting to predict when a recession occurs, I’m essentially making a prediction based on a model that conditions only on time and nothing else. That’s not the same thing as saying that excluded variables don’t matter. Rather, a variable excluded in the model is effectively treated as being a part of the random soup that generated the data I observe. I’m not conditioning on its values to make predictions. Could my prediction be refined by including that information? Perhaps. But that doesn’t make the prediction automatically useless. In fact, I think we should start with predictions that condition on little to see if conditioning on more variables adds any useful information, generally preferring the simple to the complex given equal predictive value. This is essentially what most 
I never looked at a model that uses more information than just time, though. I wouldn’t be shocked if using more variables would lead to a better model. But I don’t have that data, and to be completely honest, I don’t want to spend the time to try and get a “great” prediction for when the next recession will occur. My numbers are essentially a back-of-the-envelope calculation. It could be improved, but just because there’s (perhaps significant) room for improvement doesn’t render the calculation useless, and I think I may have evidence that shows the calculation has some merit.
The reddit user had a long discussion about how well the economy would function if predicting the time between recessions only depended on time, that the Federal Reserve would head off every recession and investors would be adjusting their behavior in ways that render the calculation useless. My response is this: I’m not a member of the Fed. I have no investments. My opinion doesn’t matter to the economy. Thus, it’s okay for me to treat the decisions of the Fed, politicians, bank presidents, other investors, and so forth, as part of that random soup producing the economy I’m experiencing, because my opinions do not invalidate the assumptions of the calculation.
There is a sense in which statistics are produced with an audience in mind. I remember Nate Silver making this point in a podcast (don’t ask me which) when discussing former FBI director James Comey’s decision almost days before the 2016 presidential election to announce a reopening of an investigation into Hillary Clinton’s e-mails, which was apparently at least partially driven by the belief that Clinton was very likely to win. Silver said that Comey did not account for the fact that he was a key actor in the process he was trying to predict and that his decisions could change the likelihood of Clinton winning. He invalidated the numbers with his decision based on them. He was not the target audience of the numbers Nate Silver was producing.
I think a similar argument can be made here. If my decisions and beliefs mattered to the economy, then I should account for them in predictions, conditioning on them. But they don’t matter, so I’ve invalidated nothing, and the people who do matter likely are (or should be) reaching conclusions in a much more sophisticated way.
A Second Look at Goodness of Fit
I’m a statistician. Statistics is my hammer. Everything looks like a nail to me. You know why? Because hammering nails is fun.
When I read u/must_not_forget_pwd’s critique, I tried to formulate it in a mathematical way, because that’s what I do. Here’s my best way to describe it in mathematical terms:
-
The time between recessions are all independent of one another.
-
Each period of growth follows its own distribution, with its own unique parameters.
-
The time separating recessions is memoryless. Knowing how long it has been since the last recession tells us nothing about how much longer we have till the next recession.
I wanted a model that one might call “maximum unpredictability”. So if 
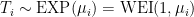

My claim is essentially that 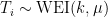


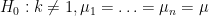
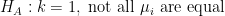
Is it possible to decide between these two hypotheses? They’re not nested and it’s not really possible to use the generalized likelihood ratio test because the parameter space that includes both 
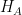
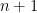
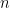
ts().)
Could that statistic be used to decide between the two hypotheses? I tried searching through literature (in particular, see [3]) and my conclusion is… maybe? To be completely honest, by this point we’ve left the realm of conventional statistics and are now turning into mad scientists, because not only are the hypotheses we’re testing and the statistic we’re using to decide between them just wacky, how the hell are we supposed to know the distribution of this test statistic under the null hypothesis when there are two nuisance parameters that likely aren’t going anywhere? Oh, and while we’re at it, the sample size of the data set of interest is really small, so don’t even think about using asymptotic reasoning!
I think you can see how this descent into madness would end up with me discovering the maximized Monte Carlo test (see [4]) and then writing MCHT to implement it. I’ll try anyting once, so the product of all that sweat and labor is below.
Both tests failed to reject the null hypothesis. Unfortunately that doesn’t seem to say much. First, it doesn’t show the null hypothesis isn’t correct; it’s just not obviously incorrect. This is always the case, but the bizarre test I’m implementing here is severely underpowered perhaps to the point of being useless. The alternative hypothesis (which I assigned to my “opponent”) is severely disadvantaged.
The conclusion of the above results isn’t in fact that I’m right. Given the severe lack of power of the test, I would say that the results of the test above are essentially inconclusive.
Conclusion
I’m going to be straight with you: if you read this whole article, I probably wasted your time, and for that I am truly sorry.
I suppose you got to enjoy some stream-of-consciousness thoughts about a controversial blog post I wrote where I made a defense that may or may not be convincing, then watched as I developed a strange statistical test that probably didn’t even work to settle a debate with some random guy on reddit, saying he claimed something that honestly he would likely deny and end that imaginary argument inconclusively.
But hey, at least I satisfied my curiosity. And I’m pretty proud of MCHT, which I created to help me write this blog post. Maybe if I hadn’t spent three straight days writing nothing but blog posts, this one would have been better, but the others seemed pretty good. So something good came out of this trip… right?
Maybe I can end like this: do I still think that a recession before the 2020 election is likely? Yes. Do I think that a Weibull describes the time between recessions decently? Conditioning on nothing else, I think so. I still think that my previous work has some merit as a decent back-of-the-envelope calculation. Do I think that the time between recessions has a memory? In short, yes. And while we’re on the topic, I’m not the Fed, so my opinions don’t matter.
All that said, though, smarter people than me may have different opinions and their contributions to this discussion are probably more valuable than mine. For instance, the people at Goldman Sachs believe a recession soon is unlikely; but the people at J.P. Morgan Chase believe a recession could strike in 2020. I’m certainly persuadable on the above points, and as I’ve said before, I think the simple analysis could enhance the narrative advanced by better predictions.
Now that I’ve written this post, we will return to our regular scheduled programming. Thanks for reading! (Please don’t judge me.)
References
-
C. Calomiris and S. Haber, Fragile by design: the political origins of banking crises and scarce credit (2014), Princeton University Press, Princeton
-
H. P. Minsky, Stabilizing an unstable economy (1986), Yale University Press, New Haven
-
D. R. Cox, Tests of separate families of hypotheses, Proc. Fourth Berkeley Symp. on Math. Stat. and Prob., vol. 1 (1961) pp. 105-123
-
J-M Dufour, Monte Carlo tests with nuisance parameters: A general approach to finite-sample inference and nonstandard asymptotics, Journal of Econometrics, vol. 133 no. 2 (2006) pp. 443-477
Packt Publishing published a book for me entitled Hands-On Data Analysis with NumPy and Pandas, a book based on my video course Unpacking NumPy and Pandas. This book covers the basics of setting up a Python environment for data analysis with Anaconda, using Jupyter notebooks, and using NumPy and pandas. If you are starting out using Python for data analysis or know someone who is, please consider buying my book or at least spreading the word about it. You can buy the book directly or purchase a subscription to Mapt and read it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)!
Related