Recommender systems use algorithms to provide users with product or service recommendations. Recently, these systems have been using machine learning algorithms from the field of artificial intelligence. An increasing number of online companies are utilizing recommendation systems to increase user interaction and enrich shopping potential. Use cases of recommendation systems have been expanding rapidly. They across many aspects of eCommerce and online media, and we expect this trend to continue.
Recommendation systems (often called “recommendation engines”) have the potential to change the way websites communicate with users. They allow companies to maximize their ROI based on the information they have on each customer’s preferences and purchases.
In this article, we will be looking upon machine learning methods which provide the personalized experiences. This matters most to the customers on different websites and end-consumers of the different business lines
Before we begin our journey of understanding how machine learning enhances personalization across various businesses, let us try to get a little idea about machine learning first. Machine learning mainly focuses on the development of computer programs which can teach themselves to grow and change when exposed to new data. Machine learning studies algorithms for self-learning to do stuff. It can process massive data faster with the learning algorithm.
Data is growing day by day, and it is impossible to understand all of the data with higher speed and higher accuracy. More than 80% of the data is unstructured that is audios, videos, photos, documents, graphs, etc. Finding patterns in data on planet earth is impossible for human brains. The data has been very massive and the time taken to compute would increase only. This is where Machine Learning comes into action, to help people with significant data in minimum time.
In this section, we will introduce you to different techniques in machine learning that can help in the personalization of your business services for your end user. User experience and conversion(eventually) are the prime goals of a business. The following algorithms are the means which will help you in achieving personalization
Regression
Regression analysis is a form of predictive modeling technique which investigates the relationship between a dependent and independent variable. Regression(linear) aims at finding a straight line which can accurately depict the actual relationship between the two variables.
Regression can help finance and investment professionals as well as professionals in other businesses. Regression can help predict sales for a company based on weather, previous sales, GDP growth or other conditions. The capital asset pricing model (CAPM) is an often-used regression model in finance for pricing assets and discovering costs of capital. The general form of each type of regression is:
Linear Regression: Y = a + bX + u
Where:
Y = the variable that you are trying to predict (dependent variable)
X = the variable that you are using to predict Y (independent variable)
a = the intercept
b = the slope
u = the regression residual
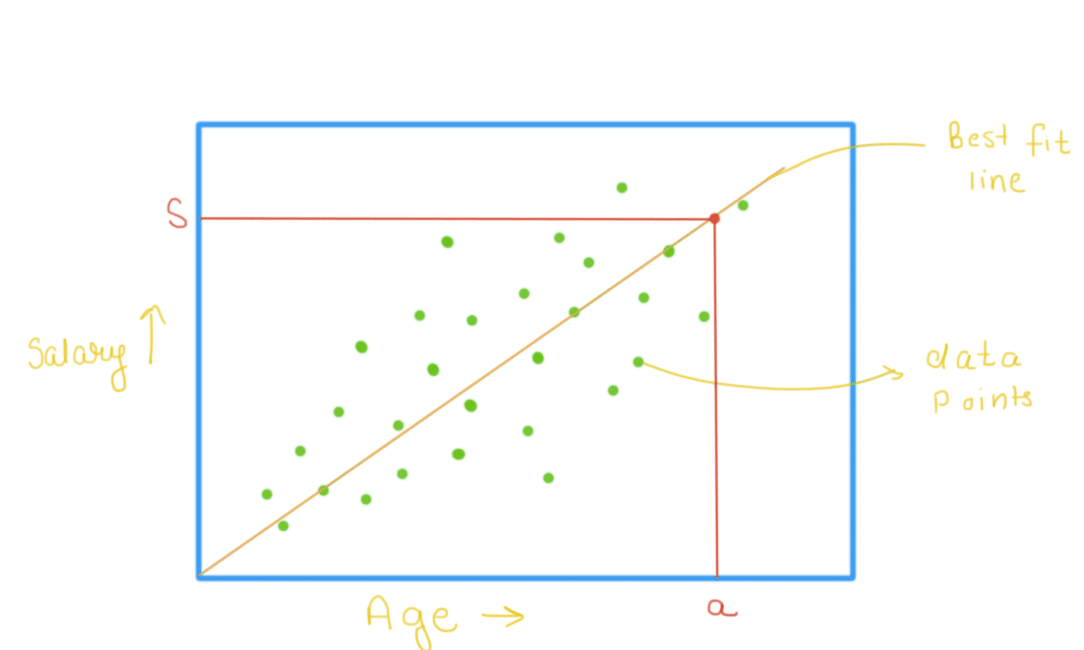
Let us take one example here. A firm X is trying to predict the salary of individuals using their age as the deciding parameter. One can plot all the available data points and find out a “best-fit line” which will describe the relationship between your age and salary parameter. In the following picture, green dots are all the available data points and the straight line passing through these points is the best fit line. Using this line, we can make predictions of salary for the other customers. Say we want to predict the salary of a person with age a. Using the best fit line, we will look at the corresponding value of salary when age is a(given parameter). Using such predictions, businesses like retail can offer different products(based on pricing) to different customers in personalizing their experience on the platform
Classifiers
In machine learning and statistics, classification is an important supervised learning approach in which the computer program learns from the data input given to it and then uses this learning to classify new observation. This data set may simply be bi-class (like identifying whether the person is male or female or that the mail is spam or non-spam) or it may be multi-class too. Some examples of classification problems are speech recognition, handwriting recognition, biometric identification, document classification etc.
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection.
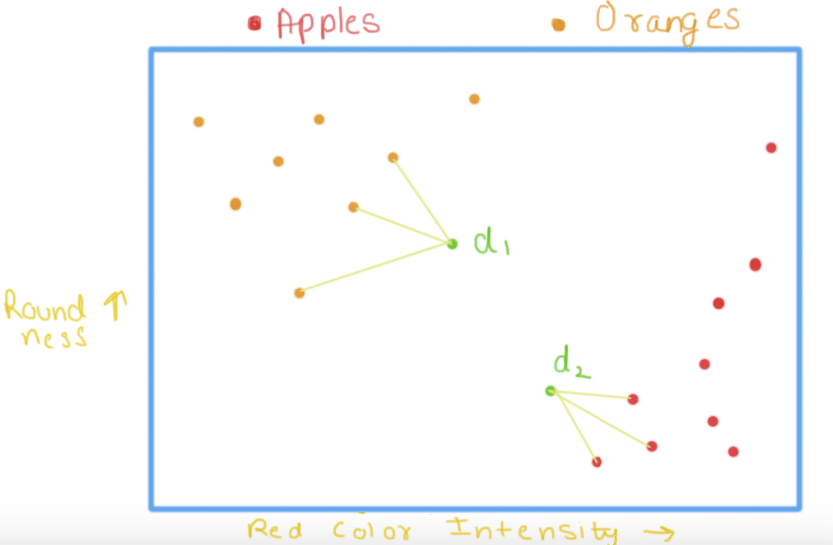
Let us take an illustration here. Suppose you want to classify apples from oranges. Our data contains 2 parameters i.e. roundness of fruit and intensity of the red color of the fruit. We then proceed to plot them. As we can see, the upper left corner contains the oranges(one with less red color intensity and more roundness) and lower right contain all the data points that represent an apple. Suppose we have a fruit whose roundness and red color intensity we know, say d1 and d2. We check the nearest neighbors of d1 and d2 and assign the class accordingly to the new data points. Nearest points to d1 are all oranges hence d1 is classified as an orange and closest points to d2 are all apples hence d2 is classified as apple.
Classification techniques are used when we have a set of predefined classes for personalization scheme. Suppose we want to classify customers on the basis of movie categories they watch on Netflix to provide movie recommendations from that particular genre, then classification techniques come really handy!
Clustering Methods
Clustering is one of the most important unsupervised learning problems; so, like every other problem of this kind, it deals with finding a structure in a collection of unlabeled data.A loose definition of clustering could be “the process of organizing objects into groups whose members are similar in some way”.A cluster is, therefore, a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters.
The goal of clustering is to determine the intrinsic grouping in a set of unlabeled data. But how to decide what constitutes a good clustering? It can be shown that there is no absolute “best” criterion which would be independent of the final aim of the clustering. Consequently, it is the user which must supply this criterion, in such a way that the result of the clustering will suit their needs.For instance, we might need to find representatives for homogeneous groups (data reduction), in finding “natural clusters” and describe their unknown properties (“natural” data types), in finding useful and suitable groupings (“useful” data classes) or in finding unusual data objects (outlier detection).
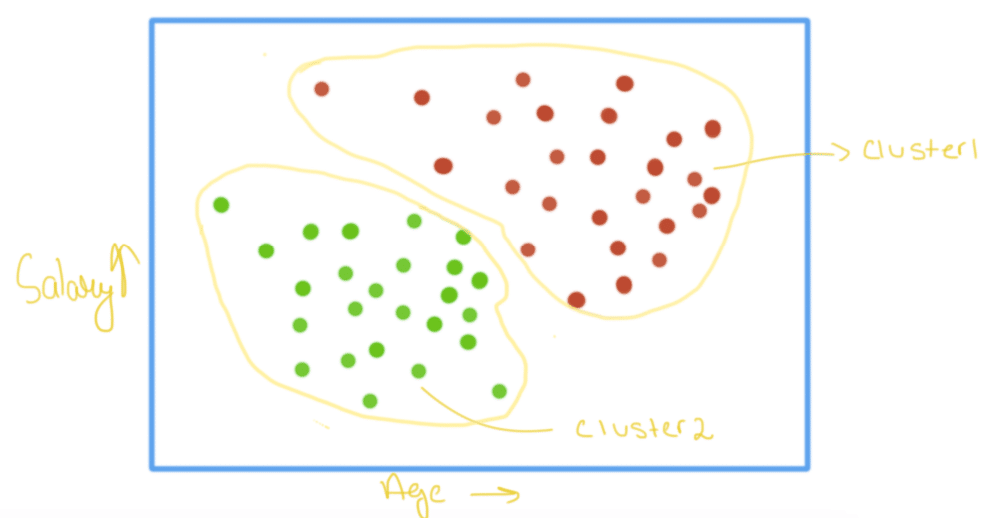
Given below is an age vs salary plot, where we can identify two sets of individuals in the data. One set is those who are younger in age and purchased the new budget smartphone whereas another cluster represents the people who are much more mature and earning high salaries but didn’t buy the product. It was easily inferred that the product was hit among the younger generation with income falling in the middle-class level
Association Rule Learning Methods
In basic terms, association rules present relations between items. They are statements that help to discover relationships between data in a database. An association rule is an implication of the form A → B. Here ‘A’ is a premise, which represents a condition that must be true for ‘B’ to hold. ‘B’ is a conclusion that happens when ‘A’ is true. An antecedent is an element found in data whereas a consequent is found in combination with the antecedent.
It is a popular technique for uncovering interesting relationships between different variables in huge databases. The association rules are suitable to build recommendation engines, like those of Amazon or Netflix. Simply put, this method allows one to thoroughly analyze the items bought by different users. With this analysis, one can easily find relations between them
To understand the strength of associations among these transactions, the algorithm uses various metrics:
-
Support helps to choose from billions of records only the most important and interesting itemsets for further analysis. You can set a specific condition here, for example, analyze itemsets that occur 40 times out of 12,000 transactions.
-
Confidence tells us how likely a consequent is when the antecedent has occurred. Example — how likely it is for a user to buy a biography book of Agassi when they’ve already bought that of Sampras.
-
Lift controls the consequent frequency to avoid a negative dependence or a substitution effect. The rule may show a high confidence value for products that have a weak association. The lift considerst the support of both antecedent and consequent to calculate the conditional probability and avoid fluke.
Reinforcement Methods
A Markov chain is a mathematical system that experiences transitions from one state to another according to certain probabilistic rules. The defining characteristic of a Markov chain is that no matter how the process arrived at its present state, the possible future states are fixed. In other words, the probability of transitioning to any particular state is dependent solely on the current state and time elapsed. The state space, or set of all possible states, can be anything: letters, numbers, weather conditions, baseball scores, or stock performances.
Markov chains are similar as finite state machines, and random walks provide a prolific example of their usefulness in mathematics. They arise broadly in statistical and information-theoretical contexts. Their application lies in economics, game theory, queueing (communication) theory, genetics, and finance. While it is possible to discuss Markov chains with any size of state space, the initial theory and most applications should focus on cases with a finite (or countably infinite) number of states.
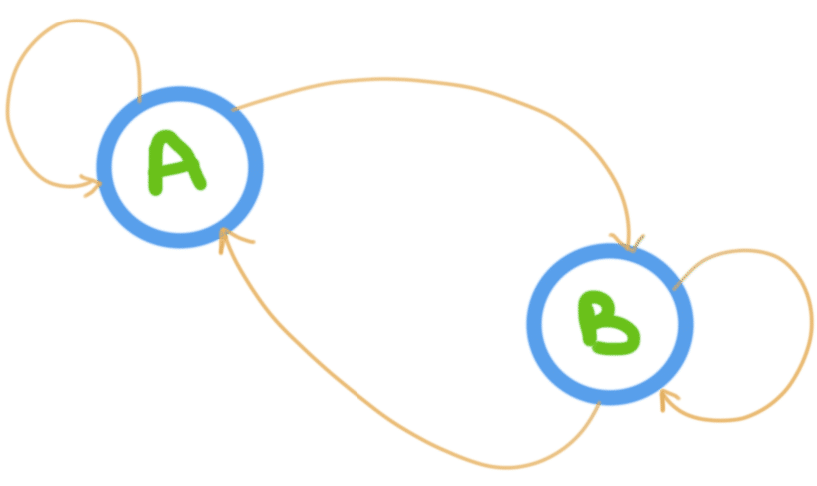
Considering the fact that Markov chains make use of just real-time data without taking into account historical information, this method is not one-size-fits-all. An example of a good use case is PageRank, Google’s algorithm that determines the order of search results.
However, when building, for instance, an AI-driven recommendation engine, you’ll have to combine Markov chains with other ML methods, including the above-mentioned ones. To wit, Netflix uses a slew of ML approaches to providing users with hyper-personalized offerings.
In this blog, we looked at different techniques in ML through which one can provide personalization to end users of their respective businesses. Consumers are connecting with brands via multiple channels, which means retailers must do more to drive customer loyalty. Marketing teams need to harness actionable insights from the multiple data channels available to them to create engaging and relevant conversations with the customers. The more personalized the experience, the happier the customer.
Please follow and like us:
![]()