The intuition
Let us begin with a brief explanation about Benford’s law and why should it work as a fraud detector method. Given a set of numbers, the first thing we need to do is to extract the first digit of each number. For example, for (121,245,12,55) the first digits will be (1,2,1,5). Perhaps our intuition would say that for a large set of numbers, each first digit, from 1 to 9, would appear in equal proportion, that is 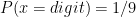
The probability of each first digit can be obtained through the following formula:
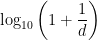
which will result in the following probabilities:

###
Generalization to more than one digit
The Benford’s law can be generalized to more digits. We will show the results for the first two digits and for the second digit alone. The formula for the first two digits is the same as the formula for the first digit with 

Finally, probabilities for the second digit alone can be obtained from the plot above by adding the probabilities that have the same second digits, from 0 to 9.

When can we use the Benford’s law?
Naturally, the Benford’s law requires data in a large range that goes through several orders of magnitude. For example, the law will not work for heights and weights of human beings. However, it is more likely to work for average heights of all species in the world or for the population of all countries in the world.
Application: Brazilian Presidential Elections from 2002 to 2018
The Brazilian electoral system has raised a lot of inflamed discussion in the previous years, especially when we were closer to the 2018 elections. Most of the critiques come from the fact that the Brazilian elections use an electronic ballot box that does not print the vote. Some people say these electronic devices are safe and some people say they make the elections blurry and impossible to audit. The latest discussion were mostly focused on the following facts:
Brazilian congress passes a bill that forces the electronic devices to print the votes. The voter would then verify the information in the paper and put it in a regular ballot box. If the electoral results came to be suspicious we could count the paper votes to see if the results match.
-
President Dilma used her veto power on this bill, forcing the elections to stay as they were, without the printed votes.
-
The Congress had a new voting that bypassed the president’s veto and reestablished the printed votes.
The Supreme Court declared the new bill to be unconstitutional and that was the end of the discussion. We had the elections only with the electronic votes.
Of course this raised a lot of critiques because there was a lot a pressure coming from the government to stop printed votes. Moreover, the same party was on the government for the fourth four years term and most of the judges is the Supreme Court were put there by them. We also had some public trials where hackers would try to break the electronic ballot and so they did without any problems.
On the other hand, no one knew exactly how a potential fraud would be performed without raising suspicion, the discussion was very speculative and did not solve anything. A alternative media company called Brasil Paralelo started a research on the Benford’s law and committed to use the law in the 2018 elections. Previous tests showed that the 2010 elections were fine and raised some doubts about the 2014 elections. They showed their results in a video and said that they found close to 80% inconsistency in the data in the 2018 first round. They were going to publish a document with more details on the results but we were not able to find it. Therefore, we will base our opinion solely on the video. The data is published by the government and they used it in a aggregation level of electoral zones, which is in fact the most adequate aggregation. An electoral zone is like a school, where we have several rooms with ballots where people go to vote. The size of electoral zones has a lot of variation going from a few hundreds or less to more than 50000, thus the use of the Benford’s law seems adequate. However, this study did not answer all our questions (that is our personal opinion) because of the following reasons:
We have our doubts on how efficiently the Benford’s law can detect frauds. In the empirical example we will fraud the data to show that we need a significant change to be able to see the fraud. Moreover, it is very hard that any real data will fit perfectly to the law. This has been widely shown by a chi2 test that rejects the data following the law, even if the figures show a very good fit. Therefore, we can only be suspicious if the data deviates a lot from the Benford’s law and, in our opinion, we should also be concerned about changing patterns in the data. For example, the same tests should be performed to many elections to see what changes between them. The data from many elections is easy to download and organize (as we will show in the application) and we could not find comparisons between elections in the Brasil Paralelo application.
- It is possible to fail to detect the fraud if we apply the law to all the data at the same time. Therefore, one should try to use sub-samples such as regions and states to give more robustness to the results. Brasil Paralelo did that, but they went to far in our opinion. Many of their sub-samples are not big enough. The fact is that we need large samples to have a reasonable convergence to the Benford’s law distribution. What we understood from the video is that they tested more than 100 sub-samples, only for the first digit equals 1. They based their analysis a lot on State level subsamples and many States may have a bad result just because the sample is very small. This comments take me to the next problem:
They did more than 100 tests of the Benford’s law and reported them in the video for the first digit equals 1. They used a confidence band of 3% and rejected all tests that had a proportion of 1s as the first digit outside the interval. The high inconsistency they reported in the end means that many of the sub-samples had proportions outside the intervals. The tricky thing here is that the intervals are the same for all sub-samples, i.e. they did not control the intervals for the sample size, which is something very obvious. If they did, and compared to all elections since 2002, they would probably find that based on their criteria all elections would be inconsistent, which only means that this test is not very good.
We would like to apologize to Brasil Paralelo if our comments were unfair. They were based on the video alone and we may have missed something. Their analysis was very good and they were very brave to do it. They only deserve our respect.
Disclosure: We are not going to try to fake neutrality. We are all for transparency and the chain of events that killed the printed vote bill is very weird. However, we will try to make our analysis as unbiased as possible. The most important thing here is that all the results can be reproduced by anyone with a little knowledge of R. We are not audit experts and we do can make mistakes.
2002 elections
The first step was to download de data and to create a function that transformed the votes into digits proportion to compare with the Benford’s law. We put the download code, the function and some metadata on Brazilian regions in the end of the post.
We will start the analysis by assuming that the 2002 elections were fine, otherwise we have no base to compare the other elections. Moreover, the analysis will be on the second round of the elections.
Now let us see how the data fits to the Benford’s law. The bars represent the Benford’s law and the lines are the proportion of digits for each candidate. The adjustment of the data to the Benford’s law is very good in the three figures below.



We could not find anything interesting in the second digit analysis alone. Therefore, we will only show the results for the first digit and the first and second digits together from here on. If you want to see the results for the second digit you can do it yourself by modifying the second digit code above to other data. Additionally, in the end of the post we show an analysis where we induce some fraud to the data to see how the Benford’s law behaves. The code is very simple and you can use it to test several types of fraud.
Looking at the Regions
Brazil has five regions of States, in this part of the post we will look at the two biggest regions (Southeastern and Northeastern regions). The reason is that the fraud may be small, local and hard to detect if we look at the entire country. These two regions have enough data to make us comfortable with the sample size. First, let’s prepare the data:
The plots are generated with the code below. As you can see, if we move to regions we find some bigger deviations, especially in the SE region. It is very hard to say if this is a pattern from the data or a fraud. The best we could think of is to look at other years and see if the pattern stays the same.


Comparing all elections from 2002 to 2014
Brazil
Preparing the data:
The code below plots the Benford’s law and the data for all elections between 2002 and 2014 for the entire country. Although we may see small variations across the years. we don’t think we can say anything about fraud by looking only at these plots. Assuming 2002 was ok, all the figures below can say is that 2006, 2010 and 2014 were also ok.


Southeastern Region
Preparing the data:
The code below plots the Benford’s law and the data for all elections between 2002 and 2014 for the Southeastern region. The conclusions here as the same as the conclusions for the entire country. If 2002 was fine then the other years were also fine. Note that the plots show the winner in red and the looser in green. Since Aecio won in the Southeast the colors are alternated in the 2014 plot. Nevertheless, Dilma’s patters remains the same as in 2010 and the same as Lula’s pattern in 2002 and 2006. Dilma was Lula’s candidate after his two terms and they are from the same party. The opposition candidate was always from the same party too.


Northeastern Region
Preparing the data:
The code below plots the Benford’s law and the data for all elections between 2002 and 2014 for the Northeastern region. Here we can start to see some difference in the plots that may raise some doubts. In 2002, everything was fine and the data for both candidates fit the Benford’s law very well. However, since 2006 we have a clear deviation from the law for the candidate that won the elections. The proportion of ones as the first digit decreases a lot and the proportion of larger values are mostly bigger than what the Benford’s law would predict. Similar results are found if we look at the first two digits together. This could be due to a change in voting patters or fraud. However, if we choose the fraud hypothesis we would have to assume that all elections were fraudulent between 2006 and 2014. This could be the case, because in 2006 Lula was reelected, meaning that he was already in the government and may have had some influence in the electoral process. Still, we don’t think the Benford’s law is useful to detect frauds alone. It can only be useful to support other evidence and perhaps give a stronger confirmation. Results like this could be used as a starting point to further investigation on the elections. However, auditing electronic ballot boxes is not easy.


2018 elections
The 2018 elections were very different. First, the use of social media was very important and second, the opposition candidate in the second round was from a whole new party. The worker’s party still managed to put a candidate (Fernando Haddad) in the second round. Moreover, Dilma was impeached in 2016 and the vice president Temer assumed. Recall that the 2018 elections must be downloaded directly from the government page. In the end of the post we give the details on how to download the data and put it in the same format as the 2002-2014 data for the same code to work.
First, let us look at the entire country. The results are generated by the code below. The figure is just below the code. Once again, every thing looks fine if we look at the entire country. The data fits very well to the Benford’s law.

Southeast Region
Now let’s move to the Southeastern region. Here we have something very unusual. The curve for both candidates deviate significantly from the Benford’s law if we compare this region with previous elections. The curve for Fernando Haddad overestimates the smaller digits and underestimates the bigger digits and the curve for Jair Bolsonaro shows the opposite situation. Although the fit for the SE region was not perfect in previous elections, it followed the same pattern that was broken in 2018.

Northeast Region
Next, the NE region. There is nothing new here. The worker’s party candidate has the same pattern from the 2006-2014 period and the other candidate looks fine. Therefore, to say that the 2018 elections were fraudulent in the NE region we must also say that all elections from 2006 to 2014 were also fraudulent.

A brief look at the first round
Finally, let’s have a look at the first round of the 2018 elections in the NE and SE regions to see if there is something new. The first plot is for the SE region. It also shows the votes for the third place candidate. The pattern is the same as the second round. However, since Fernando Haddad and Ciro Gomes had similar results, if the elections were fraudulent it was probably to influence the results of Jair Bolsonaro. It is impossible to know if the fraud was to increase or decrease the number of votes. However, most critiques on the electronic system came from him and his supporters and he is also the author of the printed vote bill.

Finally, the NE region. We don’t know if we can get any new information from that. The worker’s party candidate has the same weird pattern from previous elections and from the second round of the 2018 elections. However, in the second round the first digit equals one was closer to 0.2 and now it is closer to the Benford’s value of 0.3. Bolsonaro had similar results from the second round with a little more variation in smaller digits. We will not risk to say anything about the other candidate because we have nothing to compare it with.

Conclusion
We think that the main conclusion here is that the Benford’s law alone does not prove anything. It still need the narrative and other evidence. In my opinion, the lack of transparency in the electronic system is a bigger problem than what the data is saying through the Benford’s law. If the elections were more transparent any suspicious results one could find could be further investigated. However, We don’t think that is the case.
Downloading the data
The data from 2002 to 2014 can be downloaded with the electionsBR package. The 2018 data must be downloaded manually.
After you download all the data, save the tables in a .csv or a .rda to avoid downloading it again. The 2018 data can be downloaded from:
http://agencia.tse.jus.br/estatistica/sead/odsele/votacao_candidato_munzona/votacao_candidato_munzona_2018.zip
The presidential data must be arranged to be in the same format as the other years:
Function to arrange data and other metadata
The code below shows the function we used to arrange de data. It filters for president, the desired round and the number of candidates. If you chose 3 candidates it will select the three most voted. Note that if you chose round = 2 the number of candidate must be 2 or 1. The function also extracts the first and second digits for each zone and calculates the proportion of each digit. It returns a list where each element is named after a candidate and each candidate has three data.frames: for the first digit, second digit and first and second digits together.
Code to induce fraud
Here we will induce fraud in the 2002 data to see if the Benford’s law can capture it by adding 1000 votes in all electoral zones. We know this is not a realistic fraud because some electoral zones are very small, but this test is just to see how the fraudulent data fits to the Benford’s law. Feel free to try different types of fraud.
Now let us have a look at what happens in the fraudulent data compared to the real data, just for the first candidate (Lula) to save some space. Feel free to look at the second candidate by changing the value [[1]] to [[2]]. The three figures below show that the fraudulent data deviates a lot from the Benford’s law. However, if you try very small changes in the data the deviation would be harder to identify.



Now we are going to show a justification for not using the chi2 test through all the post. The test statistic is defined as follows:
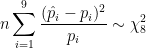
where 


Related