Unless otherwise stated, 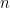
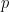
fit will denote the output/result of the glmnet call. The data matrix is denoted by 
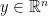
standardize
When standardize = TRUE (default), columns of the data matrix x are standardized, i.e. each column of x has mean 0 and standard deviation 1. More specifically, we have that for each 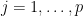
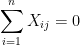
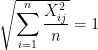
Why might we want to do this? Standardizing our features before model fitting is common practice in statistical learning. This is because if our features are on vastly different scales, the features with larger scales will tend to dominate the action. (One instance where we might not want to standardize our features is if they are already all measured along the same scale, e.g. meters or kilograms.)
Notice that the standardization here is slightly different from that offered by the scale function: scale(x, center = TRUE, scale = TRUE) gives the standardization

We verify this with a small data example. Generate data according to the following code:
Create a version of the data matrix which has standardized columns:
Next, we run glmnet on Xs and y with both possible options for standardize:
We can check that we get the same fit in both cases (modulo numerical precision):
The documentation notes that the coefficients returned are on the original scale. Let’s confirm that with our small data set. Run glmnet with the original data matrix and standardize = TRUE:
For each column 
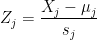


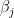
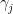
fit2 and fit3 respectively, then we should have
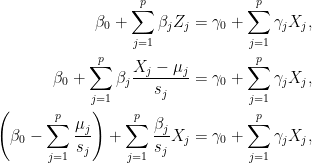
i.e. we should have 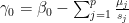

The discussion above has been for the standardization of x. What about standardization for y? The documentation notes that when family = "gaussian", y is automatically standardized, and the coefficients are unstandardized at the end of the procedure.
More concretely, let the mean and standard deviation of 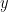


glmnet on standardized y gives intercept 

glmnet on unstandardized y will give intercept 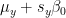
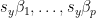
Again, this can be verified empirically:
Related