By Tal Peretz, Data Scientist

Gradient Boosted Decision Trees and Random Forest are my favorite ML models for tabular heterogeneous datasets. These models are the top performers on Kaggle competitions and in widespread use in the industry.
Catboost, the new kid on the block, has been around for a little more than a year now, and it is already threatening XGBoost, LightGBM and H2O.
Why Catboost?
Better Results
Catboost achieves the best results on the benchmark, and that’s great, yet I don’t know if I would replace a working production model for only a fraction of a log-loss improvement alone (especially when the company who conducted the benchmark has a clear interest in the favor of Catboost 😅).
Though, when you look at datasets where categorical features play a large role, such as Amazon and the *Internet *datasets, this improvement becomes significant and undeniable.
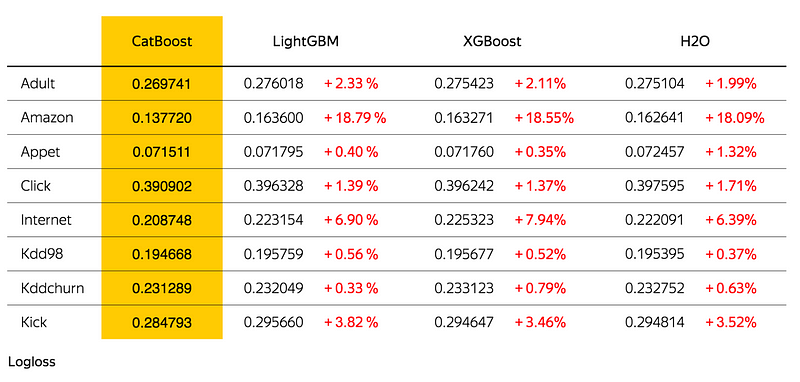 GBDT Algorithms Benchmark
GBDT Algorithms Benchmark
Faster Predictions
While training time can take up longer than other GBDT implementations, prediction time is 13–16 times faster than the other libraries according to the Yandex benchmark.
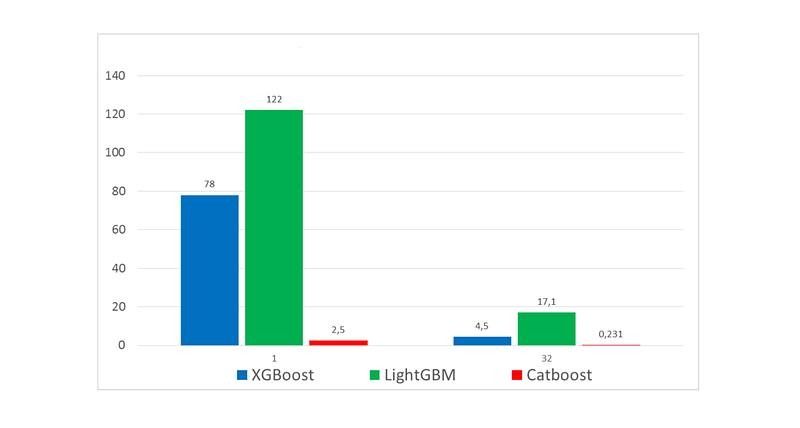 Left: CPU, Right: GPU
Left: CPU, Right: GPU
Batteries Included
Catboost’s default parameters are a better starting point than in other GBDT algorithms. And this is good news for beginners who want a plug and play model to start experience tree ensembles or Kaggle competitions.
Yet, there are some very important parameters which we must address and we’ll talk about those in a moment.
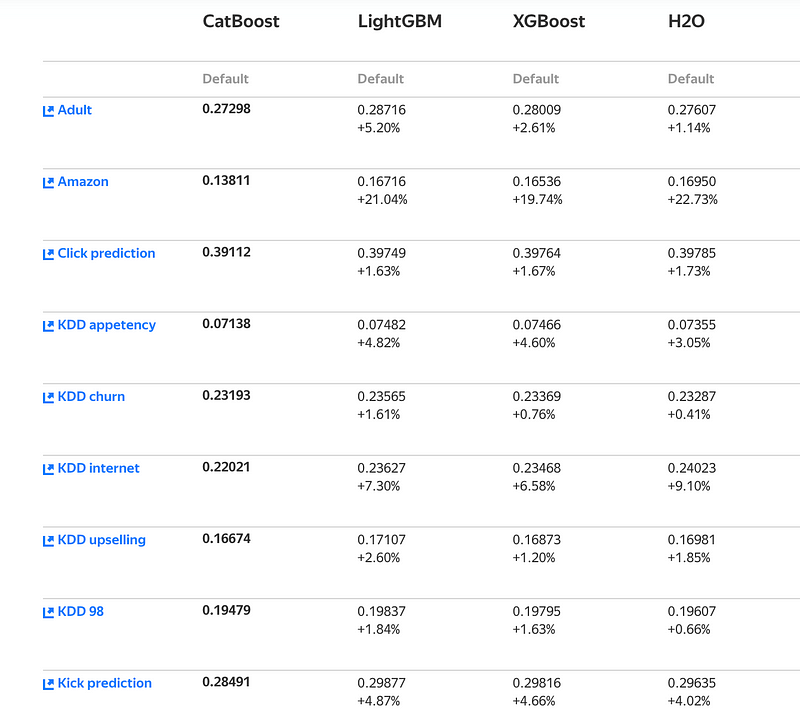 GBDT Algorithms with default parameters Benchmark
GBDT Algorithms with default parameters Benchmark
Some more noteworthy advancements by Catboost are the features interactions, object importance and the snapshot support.
In addition to classification and regression, Catboost supports ranking out of the box.
Battle Tested
Yandex is relying heavily on Catboost for ranking, forecasting and recommendations. This model is serving more than 70 million users each month.
CatBoost is an algorithm for gradient boosting on decision trees. Developed by Yandex researchers and engineers, it is the successor of the MatrixNet algorithmthat is widely used within the company for ranking tasks, forecasting and making recommendations. It is universal and can be applied across a wide range of areas and to a variety of problems.

The Algorithm
Classic Gradient Boosting
 Gradient Boosting on Wikipedia
Gradient Boosting on Wikipedia
Catboost Secret Sauce
Catboost introduces two critical algorithmic advances - the implementation of ordered boosting, a permutation-driven alternative to the classic algorithm, and an innovative algorithm for processing categorical features.
Both techniques are using random permutations of the training examples to fight the prediction shift caused by a special kind of target leakage present in all existing implementations of gradient boosting algorithms.
Categorical Feature Handling
Ordered Target Statistic
Most of the GBDT algorithms and Kaggle competitors are already familiar with the use of Target Statistic (or target mean encoding).
It’s a simple yet effective approach in which we encode each categorical feature with the estimate of the expected target y conditioned by the category.
Well, it turns out that applying this encoding carelessly (average value of y over the training examples with the same category) results in a target leakage.
To fight this *prediction shift *CatBoost uses a more effective strategy. It relies on the ordering principle and is inspired by online learning algorithms which get training examples sequentially in time. In this setting, the values of TS for each example rely only on the observed history.
To adapt this idea to a standard offline setting, Catboost introduces an artificial “time�— a random permutation σ1 of the training examples.
Then, for each example, it uses all the available “history� to compute its Target Statistic.
Note that, using only one random permutation, results in preceding examples with higher variance in Target Statistic than subsequent ones. To this end, CatBoost uses different permutations for different steps of gradient boosting.
One Hot Encoding
Catboost uses a one-hot encoding for all the features with at most one_hot_max_size unique values. The default value is 2.
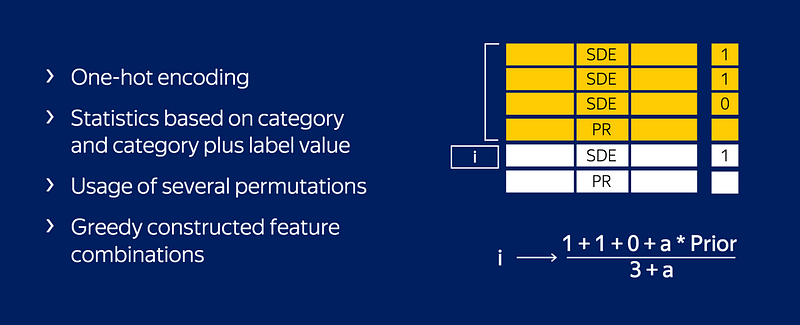 Catboost’s Secret Sauce
Catboost’s Secret Sauce
Orderd Boosting
CatBoost has two modes for choosing the tree structure, Ordered and Plain. Plain mode corresponds to a combination of the standard GBDT algorithm with an ordered Target Statistic.
In Ordered mode boosting we perform a random permutation of the training examples - σ2, and maintain n different supporting models - M1, . . . , Mn such that the model Mi is trained using only the first i samples in the permutation.
At each step, in order to obtain the residual for j-th sample, we use the model Mj−1.
Unfortunately, this algorithm is not feasible in most practical tasks due to the need of maintaining n different models, which increase the complexity and memory requirements by n times. Catboost implements a modification of this algorithm, on the basis of the gradient boosting algorithm, using one tree structure shared by all the models to be built.
 Catboost Ordered Boosting and Tree Building
Catboost Ordered Boosting and Tree Building
In order to avoid prediction shift, Catboost uses permutations such that σ1 = σ2. This guarantees that the target-yi is not used for training Mi neither for the Target Statistic calculation nor for the gradient estimation.
Hands On
For this section, we’ll use the Amazon Dataset, since it’s clean and has a strong emphasize on categorical features.
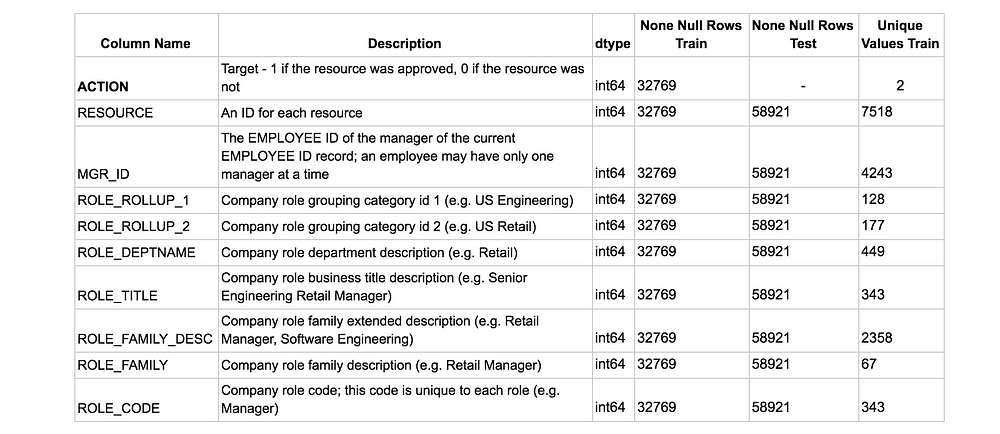 Dataset in a brief
Dataset in a brief
Tuning Catboost
Important Parameters
cat_features — This parameter is a must in order to leverage Catboost preprocessing of categorical features, if you encode the categorical features yourself and don’t pass the columns indices as cat_features *you are missing the essence of Catboost.* one_hot_max_size — As mentioned before,* Catboost uses a one-hot encoding for all features with at most *one_hot_max_size unique values. In our case, the categorical features have a lot of unique values, so we won’t use one hot encoding, but depending on the dataset it may be a good idea to adjust this parameter. learning_rate & n_estimators — The smaller the learning_rate, the more n_estimators needed to utilize the model. Usually the approach is to start with a relative high learning_rate, tune other parameters and then decrease the learning_rate while increasing n_estimators. max_depth — Depth of the base trees, *this parameter has an high impact on training time.* subsample — Sample rate of rows, can’t be used in a Bayesian boosting type setting. colsample_bylevel — Sample rate of columns. l2_leaf_reg — L2 regularization coefficient. random_strength — Every split gets a score and random_strength is adding some randomness to the score, it helps to reduce overfitting.
Model Exploration with Catboost
In addition to feature importance, which is quite popular for GBDT models to share, Catboost provides feature interactions and object (row) importance
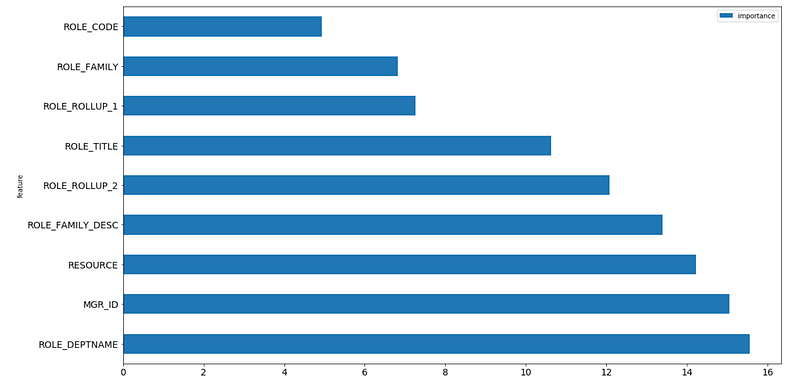 Catboost’s Feature Importance
Catboost’s Feature Importance
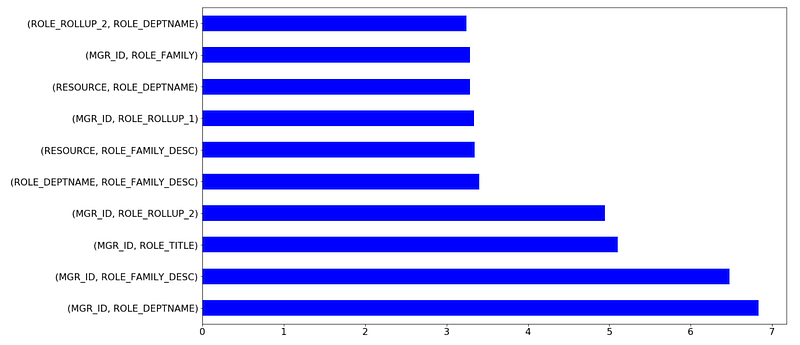 Catboost’s Feature Interactions
Catboost’s Feature Interactions
 Catboost’s Object Importance
Catboost’s Object Importance
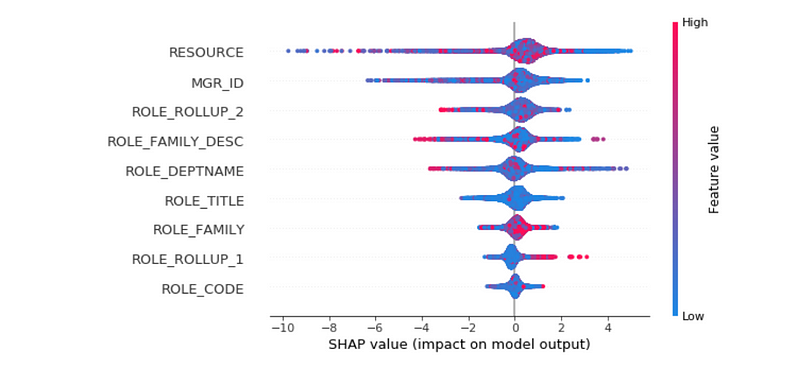 SHAP values can be used for other ensembles as well
SHAP values can be used for other ensembles as well
The Full Notebook
Check it out for some useful Catboost code snippets
Catboost Playground Notebook
Bottom Line
 Catboost vs. XGBoost (default, greedy and exhaustive parameter search)
Catboost vs. XGBoost (default, greedy and exhaustive parameter search)

Take Away
Catboost is built with a similar approach and attributes as with the “older� generation of GBDT models. Catboost’s power lies in its categorical features preprocessing, prediction time and model analysis. Catboost’s weaknesses are its training and optimization times. Don’t forget to pass cat_features argument to the classifier object. You aren’t really utilizing the power of Catboost without it. Though Catboost performs well with default parameters, there are several parameters that drive a significant improvement in results when tuned.
Further Reading
Huge thanks to Catboost Team Lead Anna Veronika Dorogush.
If you enjoyed this post, feel free to hit the clap button �� and if you’re interested in posts to come, make sure to follow me on
Medium:https://medium.com/@talperetz24Twitter:https://twitter.com/talperetz24LinkedIn:https://www.linkedin.com/in/tal-per/
Like every year, I want to mention DataHack- the best data driven hackathon out there. This year דור פרץ and I used Catboost for our project and won the 1st place �.
| Bio: Tal Peretz is a Data Scientist, Software Engineer, and a Continuous Learner. He is passionate about solving complex problems with high-value potential using data, code and algorithms. He especially likes building and improving models to separate the ones from the zeros. 0 | 1 |
Original. Reposted with permission.
Related: