Forecasting Transportation Network Speed Using Deep Capsule Networks with Nested LSTM Models
Accurate and reliable traffic forecasting for complicated transportation networks is of vital importance to modern transportation management. The complicated spatial dependencies of roadway links and the dynamic temporal patterns of traffic states make it particularly challenging. To address these challenges, we propose a new capsule network (CapsNet) to extract the spatial features of traffic networks and utilize a nested LSTM (NLSTM) structure to capture the hierarchical temporal dependencies in traffic sequence data. A framework for network-level traffic forecasting is also proposed by sequentially connecting CapsNet and NLSTM. On the basis of literature review, our study is the first to adopt CapsNet and NLSTM in the field of traffic forecasting. An experiment on a Beijing transportation network with 278 links shows that the proposed framework with the capability of capturing complicated spatiotemporal traffic patterns outperforms multiple state-of-the-art traffic forecasting baseline models. The superiority and feasibility of CapsNet and NLSTM are also demonstrated, respectively, by visualizing and quantitatively evaluating the experimental results.
Modeling Conceptual Characteristics of Virtual Machines for CPU Utilization Prediction
Cloud services have grown rapidly in recent years, which provide high flexibility for cloud users to fulfill their computing requirements on demand. To wisely allocate computing resources in the cloud, it is inevitably important for cloud service providers to be aware of the potential utilization of various resources in the future. This paper focuses on predicting CPU utilization of virtual machines (VMs) in the cloud. We conduct empirical analysis on Microsoft Azure’s VM workloads and identify important conceptual characteristics of CPU utilization among VMs, including locality, periodicity and tendency. We propose a neural network method, named Time-aware Residual Networks (T-ResNet), to model the observed conceptual characteristics with expanded network depth for CPU utilization prediction. We conduct extensive experiments to evaluate the effectiveness of our proposed method and the results show that T-ResNet consistently outperforms baseline approaches in various metrics including RMSE, MAE and MAPE.
Data Pallets: Containerizing Storage For Reproducibility and Traceability
Trusting simulation output is crucial for Sandia’s mission objectives. We rely on these simulations to perform our high-consequence mission tasks given national treaty obligations. Other science and modeling applications, while they may have high-consequence results, still require the strongest levels of trust to enable using the result as the foundation for both practical applications and future research. To this end, the computing community has developed workflow and provenance systems to aid in both automating simulation and modeling execution as well as determining exactly how was some output was created so that conclusions can be drawn from the data. Current approaches for workflows and provenance systems are all at the user level and have little to no system level support making them fragile, difficult to use, and incomplete solutions. The introduction of container technology is a first step towards encapsulating and tracking artifacts used in creating data and resulting insights, but their current implementation is focused solely on making it easy to deploy an application in an isolated ‘sandbox’ and maintaining a strictly read-only mode to avoid any potential changes to the application. All storage activities are still using the system-level shared storage. This project explores extending the container concept to include storage as a new container type we call \emph{data pallets}. Data Pallets are potentially writeable, auto generated by the system based on IO activities, and usable as a way to link the contained data back to the application and input deck used to create it.
Reasoning From Data in the Mathematical Theory of Evidence
Mathematical Theory of Evidence (MTE) is known as a foundation for reasoning when knowledge is expressed at various levels of detail. Though much research effort has been committed to this theory since its foundation, many questions remain open. One of the most important open questions seems to be the relationship between frequencies and the Mathematical Theory of Evidence. The theory is blamed to leave frequencies outside (or aside of) its framework. The seriousness of this accusation is obvious: no experiment may be run to compare the performance of MTE-based models of real world processes against real world data. In this paper we develop a frequentist model of the MTE bringing to fall the above argument against MTE. We describe, how to interpret data in terms of MTE belief functions, how to reason from data about conditional belief functions, how to generate a random sample out of a MTE model, how to derive MTE model from data and how to compare results of reasoning in MTE model and reasoning from data. It is claimed in this paper that MTE is suitable to model some types of destructive processes
A Bayesian Perspective of Statistical Machine Learning for Big Data
Statistical Machine Learning (SML) refers to a body of algorithms and methods by which computers are allowed to discover important features of input data sets which are often very large in size. The very task of feature discovery from data is essentially the meaning of the keyword `learning’ in SML. Theoretical justifications for the effectiveness of the SML algorithms are underpinned by sound principles from different disciplines, such as Computer Science and Statistics. The theoretical underpinnings particularly justified by statistical inference methods are together termed as statistical learning theory. This paper provides a review of SML from a Bayesian decision theoretic point of view — where we argue that many SML techniques are closely connected to making inference by using the so called Bayesian paradigm. We discuss many important SML techniques such as supervised and unsupervised learning, deep learning, online learning and Gaussian processes especially in the context of very large data sets where these are often employed. We present a dictionary which maps the key concepts of SML from Computer Science and Statistics. We illustrate the SML techniques with three moderately large data sets where we also discuss many practical implementation issues. Thus the review is especially targeted at statisticians and computer scientists who are aspiring to understand and apply SML for moderately large to big data sets.
Reasoning over RDF Knowledge Bases using Deep Learning
Semantic Web knowledge representation standards, and in particular RDF and OWL, often come endowed with a formal semantics which is considered to be of fundamental importance for the field. Reasoning, i.e., the drawing of logical inferences from knowledge expressed in such standards, is traditionally based on logical deductive methods and algorithms which can be proven to be sound and complete and terminating, i.e. correct in a very strong sense. For various reasons, though, in particular, the scalability issues arising from the ever-increasing amounts of Semantic Web data available and the inability of deductive algorithms to deal with noise in the data, it has been argued that alternative means of reasoning should be investigated which bear high promise for high scalability and better robustness. From this perspective, deductive algorithms can be considered the gold standard regarding correctness against which alternative methods need to be tested. In this paper, we show that it is possible to train a Deep Learning system on RDF knowledge graphs, such that it is able to perform reasoning over new RDF knowledge graphs, with high precision and recall compared to the deductive gold standard.
Meet Cyrus – The Query by Voice Mobile Assistant for the Tutoring and Formative Assessment of SQL Learners
Being declarative, SQL stands a better chance at being the programming language for conceptual computing next to natural language programming. We examine the possibility of using SQL as a back-end for natural language database programming. Distinctly from keyword based SQL querying, keyword dependence and SQL’s table structure constraints are significantly less pronounced in our approach. We present a mobile device voice query interface, called Cyrus, to arbitrary relational databases. Cyrus supports a large type of query classes, sufficient for an entry level database class. Cyrus is also application independent, allows test database adaptation, and not limited to specific sets of keywords or natural language sentence structures. It’s cooperative error reporting is more intuitive, and iOS based mobile platform is also more accessible compared to most contemporary mobile and voice enabled systems.
What does it mean for data to be observed’ or missing’?
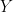
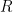

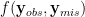

The Global Convergence of the Alternating Minimization Algorithm for Deep Neural Network Problems
In recent years, stochastic gradient descent (SGD) is a dominant optimization method for training deep neural networks. But the SGD suffers from several limitations including lack of theoretical guarantees, gradient vanishing, poor conditioning and difficulty in solving highly non-smooth constraints and functions, which motivates the development of alternating minimization-based methods for deep neural network optimization. However, as an emerging domain, there are still several challenges to overcome, where the major ones include: 1) no guarantee on the global convergence under mild conditions, and 2) low efficiency of computation for the subproblem optimization in each iteration. In this paper, we propose a novel deep learning alternating minimization (DLAM) algorithm to deal with those two challenges. Furthermore, global convergence of our DLAM algorithm is analyzed and guaranteed under mild conditions which are satisfied by commonly-used models. Experiments on real-world datasets demonstrate the effectiveness of our DLAM algorithm.
Adversarially-Trained Normalized Noisy-Feature Auto-Encoder for Text Generation
This article proposes Adversarially-Trained Normalized Noisy-Feature Auto-Encoder (ATNNFAE) for byte-level text generation. An ATNNFAE consists of an auto-encoder where the internal code is normalized on the unit sphere and corrupted by additive noise. Simultaneously, a replica of the decoder (sharing the same parameters as the AE decoder) is used as the generator and fed with random latent vectors. An adversarial discriminator is trained to distinguish training samples reconstructed from the AE from samples produced through the random-input generator, making the entire generator-discriminator path differentiable for discrete data like text. The combined effect of noise injection in the code and shared weights between the decoder and the generator can prevent the mode collapsing phenomenon commonly observed in GANs. Since perplexity cannot be applied to non-sequential text generation, we propose a new evaluation method using the total variance distance between frequencies of hash-coded byte-level n-grams (NGTVD). NGTVD is a single benchmark that can characterize both the quality and the diversity of the generated texts. Experiments are offered in 6 large-scale datasets in Arabic, Chinese and English, with comparisons against n-gram baselines and recurrent neural networks (RNNs). Ablation study on both the noise level and the discriminator is performed. We find that RNNs have trouble competing with the n-gram baselines, and the ATNNFAE results are generally competitive.
Efficient Spiking Neural Networks with Logarithmic Temporal Coding
A Spiking Neural Network (SNN) can be trained indirectly by first training an Artificial Neural Network (ANN) with the conventional backpropagation algorithm, then converting it into an SNN. The conventional rate-coding method for SNNs uses the number of spikes to encode magnitude of an activation value, and may be computationally inefficient due to the large number of spikes. Temporal-coding is typically more efficient by leveraging the timing of spikes to encode information. In this paper, we present Logarithmic Temporal Coding (LTC), where the number of spikes used to encode an activation value grows logarithmically with the activation value; and the accompanying Exponentiate-and-Fire (EF) spiking neuron model, which only involves efficient bit-shift and addition operations. Moreover, we improve the training process of ANN to compensate for approximation errors due to LTC. Experimental results indicate that the resulting SNN achieves competitive performance at significantly lower computational cost than related work.
Towards Formula Translation using Recursive Neural Networks
While it has become common to perform automated translations on natural language, performing translations between different representations of mathematical formulae has thus far not been possible. We implemented the first translator for mathematical formulae based on recursive neural networks. We chose recursive neural networks because mathematical formulae inherently include a structural encoding. In our implementation, we developed new techniques and topologies for recursive tree-to-tree neural networks based on multi-variate multi-valued Long Short-Term Memory cells. We propose a novel approach for mini-batch training that utilizes clustering and tree traversal. We evaluate our translator and analyze the behavior of our proposed topologies and techniques based on a translation from generic LaTeX to the semantic LaTeX notation. We use the semantic LaTeX notation from the Digital Library for Mathematical Formulae and the Digital Repository for Mathematical Formulae at the National Institute for Standards and Technology. We find that a simple heuristics-based clustering algorithm outperforms the conventional clustering algorithms on the task of clustering binary trees of mathematical formulae with respect to their topology. Furthermore, we find a mask for the loss function, which can prevent the neural network from finding a local minimum of the loss function. Given our preliminary results, a complete translation from formula to formula is not yet possible. However, we achieved a prediction accuracy of 47.05% for predicting symbols at the correct position and an accuracy of 92.3% when ignoring the predicted position. Concluding, our work advances the field of recursive neural networks by improving the training speed and quality of training. In the future, we will work towards a complete translation allowing a machine-interpretation of LaTeX formulae.
Learning Shaping Strategies in Human-in-the-loop Interactive Reinforcement Learning
Providing reinforcement learning agents with informationally rich human knowledge can dramatically improve various aspects of learning. Prior work has developed different kinds of shaping methods that enable agents to learn efficiently in complex environments. All these methods, however, tailor human guidance to agents in specialized shaping procedures, thus embodying various characteristics and advantages in different domains. In this paper, we investigate the interplay between different shaping methods for more robust learning performance. We propose an adaptive shaping algorithm which is capable of learning the most suitable shaping method in an on-line manner. Results in two classic domains verify its effectiveness from both simulated and real human studies, shedding some light on the role and impact of human factors in human-robot collaborative learning.
Anomaly Detection via Graphical Lasso

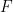
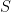

Efficiently Approximating Edit Distance Between Pseudorandom Strings


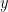
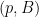

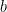
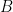






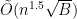

Multi-label Object Attribute Classification using a Convolutional Neural Network
Objects of different classes can be described using a limited number of attributes such as color, shape, pattern, and texture. Learning to detect object attributes instead of only detecting objects can be helpful in dealing with a priori unknown objects. With this inspiration, a deep convolutional neural network for low-level object attribute classification, called the Deep Attribute Network (DAN), is proposed. Since object features are implicitly learned by object recognition networks, one such existing network is modified and fine-tuned for developing DAN. The performance of DAN is evaluated on the ImageNet Attribute and a-Pascal datasets. Experiments show that in comparison with state-of-the-art methods, the proposed model achieves better results.
Optimizing Taxi Carpool Policies via Reinforcement Learning and Spatio-Temporal Mining
In this paper, we develop a reinforcement learning (RL) based system to learn an effective policy for carpooling that maximizes transportation efficiency so that fewer cars are required to fulfill the given amount of trip demand. For this purpose, first, we develop a deep neural network model, called ST-NN (Spatio-Temporal Neural Network), to predict taxi trip time from the raw GPS trip data. Secondly, we develop a carpooling simulation environment for RL training, with the output of ST-NN and using the NYC taxi trip dataset. In order to maximize transportation efficiency and minimize traffic congestion, we choose the effective distance covered by the driver on a carpool trip as the reward. Therefore, the more effective distance a driver achieves over a trip (i.e. to satisfy more trip demand) the higher the efficiency and the less will be the traffic congestion. We compared the performance of RL learned policy to a fixed policy (which always accepts carpool) as a baseline and obtained promising results that are interpretable and demonstrate the advantage of our RL approach. We also compare the performance of ST-NN to that of state-of-the-art travel time estimation methods and observe that ST-NN significantly improves the prediction performance and is more robust to outliers.
A Self-Learning Information Diffusion Model for Smart Social Networks
In this big data era, more and more social activities are digitized thereby becoming traceable, and thus the studies of social networks attract increasing attention from academia. It is widely believed that social networks play important role in the process of information diffusion. However, the opposite question, i.e., how does information diffusion process rebuild social networks, has been largely ignored. In this paper, we propose a new framework for understanding this reversing effect. Specifically, we first introduce a novel information diffusion model on social networks, by considering two types of individuals, i.e., smart and normal individuals, and two kinds of messages, true and false messages. Since social networks consist of human individuals, who have self-learning ability, in such a way that the trust of an individual to one of its neighbors increases (or decreases) if this individual received a true (or false) message from that neighbor. Based on such a simple self-learning mechanism, we prove that a social network can indeed become smarter, in terms of better distinguishing the true message from the false one. Moreover, we observe the emergence of social stratification based on the new model, i.e., the true messages initially posted by an individual closer to the smart one can be forwarded by more others, which is enhanced by the self-learning mechanism. We also find the crossover advantage, i.e., interconnection between two chain networks can make the related individuals possessing higher social influences, i.e., their messages can be forwarded by relatively more others. We obtained these results theoretically and validated them by simulations, which help better understand the reciprocity between social networks and information diffusion.
A Survey of Mixed Data Clustering Algorithms
Most of the datasets normally contain either numeric or categorical features. Mixed data comprises of both numeric and categorical features, and they frequently occur in various domains, such as health, finance, marketing, etc. Clustering is often sought on mixed data to find structures and to group similar objects. However, clustering mixed data is challenging because it is difficult to directly apply mathematical operations, such as summation, average etc. on the feature values of these datasets. In this paper, we review various types of mixed data clustering techniques in detail. We present a taxonomy to identify ten types of different mixed data clustering techniques. We also compare the performance of several mixed data clustering methods on publicly available datasets. The paper further identifies challenges in developing different mixed data clustering algorithms and provides guidelines for future directions in this area.
Explaining Deep Learning Models using Causal Inference
Although deep learning models have been successfully applied to a variety of tasks, due to the millions of parameters, they are becoming increasingly opaque and complex. In order to establish trust for their widespread commercial use, it is important to formalize a principled framework to reason over these models. In this work, we use ideas from causal inference to describe a general framework to reason over CNN models. Specifically, we build a Structural Causal Model (SCM) as an abstraction over a specific aspect of the CNN. We also formulate a method to quantitatively rank the filters of a convolution layer according to their counterfactual importance. We illustrate our approach with popular CNN architectures such as LeNet5, VGG19, and ResNet32.
• Quantum Reasoning using Lie Algebra for Everyday Life (and AI perhaps…)• Packing Sparse Convolutional Neural Networks for Efficient Systolic Array Implementations: Column Combining Under Joint Optimization• A Feature Complete SPIKE Banded Algorithm and Solver• Scene Parsing via Dense Recurrent Neural Networks with Attentional Selection• AttS2S-VC: Sequence-to-Sequence Voice Conversion with Attention and Context Preservation Mechanisms• Fast Beam Alignment for Millimeter Wave Communications: A Sparse Encoding and Phaseless Decoding Approach• ExcitNet vocoder: A neural excitation model for parametric speech synthesis systems• Multilingual and Unsupervised Subword Modeling for Zero-Resource Languages• Mathematical Theory of Evidence Versus Evidence• Gaining insight from large data volumes with ease• Observability Properties of Colored Graphs• Surrogate Modeling of Stochastic Functions – Application to computational Electromagnetic Dosimetry• On Weisfeiler-Leman Invariance: Subgraph Counts and Related Graph Properties• Multiple People Tracking Using Hierarchical Deep Tracklet Re-identification• Deep Learning Super-Diffusion in Multiplex Networks• Reducing Network Agnostophobia• An Agent-Based Approach for Optimizing Modular Vehicle Fleet Operation• Rethinking network reciprocity over social ties: local interactions make direct reciprocity possible and pave the rational way to cooperation• Second order Stein: SURE for SURE and other applications in high-dimensional inference• Bootstrapping Structural Change Tests• Many-Body Localization in Two Dimensions from Projected Entangled-Pair States• Policy Regret in Repeated Games• STA: Spatial-Temporal Attention for Large-Scale Video-based Person Re-Identification• Integrating Recurrence Dynamics for Speech Emotion Recognition• Relative Error RKHS Embeddings for Gaussian Kernels• SURE-fuse WFF: A Multi-resolution Windowed Fourier Analysis for Interferometric Phase Denoising• Feedback-Aware Precoding for Millimeter Wave Massive MIMO Systems• Median Confidence Regions in a Nonparametric Model• Complex Unitary Recurrent Neural Networks using Scaled Cayley Transform• Simulation of the energy efficiency auction prices in Brazil• LoRa Digital Receiver Analysis and Implementation• Optimal Distribution System Restoration with Microgrids and Distributed Generators• Count-Min: Optimal Estimation and Tight Error Bounds using Empirical Error Distributions• Design Rule Violation Hotspot Prediction Based on Neural Network Ensembles• Zero-shot Neural Transfer for Cross-lingual Entity Linking• Adversarial Sampling and Training for Semi-Supervised Information Retrieval• Computational Thinking with the Web Crowd using CodeMapper• Dual Latent Variable Model for Low-Resource Natural Language Generation in Dialogue Systems• Power Normalizing Second-order Similarity Network for Few-shot Learning• Symmetry Type Graphs on 4-Orbit maps• The Augmented Synthetic Control Method• Designing plateaued Boolean functions in spectral domain and their classification• Use of Neural Signals to Evaluate the Quality of Generative Adversarial Network Performance in Facial Image Generation• New Movement and Transformation Principle of Fuzzy Reasoning and Its Application to Fuzzy Neural Network• CED: Credible Early Detection of Social Media Rumors• An efficient branch-and-bound algorithm for submodular function maximization• Mapping Navigation Instructions to Continuous Control Actions with Position-Visitation Prediction• CAPTAIN: Comprehensive Composition Assistance for Photo Taking• R-SPIDER: A Fast Riemannian Stochastic Optimization Algorithm with Curvature Independent Rate• Fast On-the-fly Retraining-free Sparsification of Convolutional Neural Networks• A Note on Local Mode-in-State Participation Factors for Nonlinear Systems• Image Cartoon-Texture Decomposition Using Isotropic Patch Recurrence• Densely Connected Attention Propagation for Reading Comprehension• User-Centric Multiobjective Approach to Privacy Preservation and Energy Cost Minimization in Smart Home• Innovative 3D Depth Map Generation From A Holoscopic 3D Image Based on Graph Cut Technique• Properties of Noncommutative Renyi and Augustin Information• StationPlot: A New Non-stationarity Quantification Tool for Detection of Epileptic Seizures• Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-dependency• Skeleton-Based Action Recognition with Synchronous Local and Non-local Spatio-temporal Learning and Frequency Attention• Near Real-Time Data Labeling Using a Depth Sensor for EMG Based Prosthetic Arms• Breast Cancer Classification from Histopathological Images with Inception Recurrent Residual Convolutional Neural Network• A Bayesian Approach to Income Inference in a Communication Network• Deep Learning Approach for Building Detection in Satellite Multispectral Imagery• Bayesian variational inference for exponential random graph models• Detecting Work Zones in SHRP 2 NDS Videos Using Deep Learning Based Computer Vision• Formal Limitations on the Measurement of Mutual Information• A new resource measure with respect to resource destroying maps• Scene Text Detection and Recognition: The Deep Learning Era• Input Perturbations for Adaptive Regulation and Learning• A stochastically perturbed mean curvature flow by colored noise• Besov class via heat semigroup on Dirichlet spaces I: Sobolev type inequalities• More robust estimation of sample average treatment effects using Kernel Optimal Matching in an observational study of spine surgical interventions• Scalability Evaluation of Iterative Algorithms Used for Supercomputer Simulation of Physical processes• The method of multimodal MRI brain image segmentation based on differential geometric features• The Queue-Hawkes Process: Ephemeral Self-Excitement• Improving End-to-end Speech Recognition with Pronunciation-assisted Sub-word Modeling• Minimax Optimal Sequential Hypothesis Tests for Markov Processes• Many $H$-copies in graphs with a forbidden tree• IP Geolocation through Reverse DNS• Coronary Calcium Detection using 3D Attention Identical Dual Deep Network Based on Weakly Supervised Learning• Prediction and forecasting models based on patient’s history and biomarkers with application to Scleroderma disease• Averaging principle for stochastic real Ginzburg-Landau equation driven by $α$-stable process• Using NonBacktracking Expansion to Analyze k-core Pruning Process• On Word and Gómez Graphs and Their Automorphism Groups in the Degree Diameter Problem• Centralized adaptive traffic control strategy design across multiple intersections based on vehicle path flows: An approximated Lagrangian decomposition approach• PolyNeuron: Automatic Neuron Discovery via Learned Polyharmonic Spline Activations• Automatic Brain Structures Segmentation Using Deep Residual Dilated U-Net• Uniform, Integral and Feasible Proofs for the Determinant Identities• Playing by the Book: Towards Agent-based Narrative Understanding through Role-playing and Simulation• Channel Coding at Low Capacity• Fully Convolutional Network with Multi-Step Reinforcement Learning for Image Processing• Diversity-Driven Extensible Hierarchical Reinforcement Learning• Coverage Centrality Maximization in Undirected Networks• Reactive Task and Motion Planning for Robust Whole-Body Dynamic Locomotion in Constrained Environments• Convolution Algebras for Finite Reductive Monoids• Traversal with Enumeration of Geometric Graphs in Bounded Space• Constructing Geometric Graphs of Cop Number Three• Langevin-gradient parallel tempering for Bayesian neural learning• Discovering heterogeneous subpopulations for fine-grained analysis of opioid use and opioid use disorders• Deep Face Quality Assessment• Compressive Sensing and Morphology Singular Entropy-Based Real-time Secondary Voltage Control of Multi-area Power Systems• Model predictive trajectory optimization and tracking for on-road autonomous vehicles• Towards Governing Agent’s Efficacy: Action-Conditional $β$-VAE for Deep Transparent Reinforcement Learning• Generalization Bounds for Vicinal Risk Minimization Principle• Neural-based Pinyin-to-Character Conversion with Adaptive Vocabulary• Multi-labeled Relation Extraction with Attentive Capsule Network• Bayesian Convolutional Neural Networks for Compressed Sensing Restoration• Neural Generative Models for 3D Faces with Application in 3D Texture Free Face Recognition• Anticipated mean-field backward stochastic differential equations with jumps• Universal Randomized Guessing with Application to Asynchronous Decentralized Brute-Force Attacks• User Modeling for Task Oriented Dialogues• Improved Visual Relocalization by Discovering Anchor Points• A globally and linearly convergent PGM for zero-norm regularized quadratic optimization with sphere constraint• Fashion and Apparel Classification using Convolutional Neural Networks• Attentive Aspect Modeling for Review-aware Recommendation• ReSet: Learning Recurrent Dynamic Routing in ResNet-like Neural Networks• Adapting multi-armed bandits policies to contextual bandits scenarios• Integrating Multiple Receptive Fields through Grouped Active Convolution
Like this:
Like Loading…
Related