In this post, we will focus on the penalty.factor option.
Unless otherwise stated, 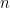
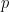
fit will denote the output/result of the glmnet call.
penalty.factor
When this option is not set, for each value of 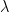
lambda, glmnet is minimizing the following objective function:
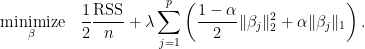
When the option is set to a vector c(c_1, ..., c_p), glmnet minimizes the following objective instead:

In the documentation, it is stated that “the penalty factors are internally rescaled to sum to nvars and the lambda sequence will reflect this change.” However, from my own experiments, it seems that the penalty factors are internally rescaled to sum to nvars but the lambda sequence remains the same. Let’s generate some data:
We fit two models, fit which uses the default options for glmnet, and fit2 which has penalty.factor = rep(2, 5):
What we find is that these two models have the exact same lambda sequence and produce the same beta coefficients.
The same thing happens when we supply our own lambda sequence:
Hence, my conclusion is that if penalty.factor is set to c(c_1, ..., c_p), glmnet is really minimizing
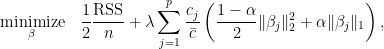
where 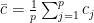
Related