Neural Rendering Model: Joint Generation and Prediction for Semi-Supervised Learning
Unsupervised and semi-supervised learning are important problems that are especially challenging with complex data like natural images. Progress on these problems would accelerate if we had access to appropriate generative models under which to pose the associated inference tasks. Inspired by the success of Convolutional Neural Networks (CNNs) for supervised prediction in images, we design the Neural Rendering Model (NRM), a new probabilistic generative model whose inference calculations correspond to those in a given CNN architecture. The NRM uses the given CNN to design the prior distribution in the probabilistic model. Furthermore, the NRM generates images from coarse to finer scales. It introduces a small set of latent variables at each level, and enforces dependencies among all the latent variables via a conjugate prior distribution. This conjugate prior yields a new regularizer based on paths rendered in the generative model for training CNNs-the Rendering Path Normalization (RPN). We demonstrate that this regularizer improves generalization, both in theory and in practice. In addition, likelihood estimation in the NRM yields training losses for CNNs, and inspired by this, we design a new loss termed as the Max-Min cross entropy which outperforms the traditional cross-entropy loss for object classification. The Max-Min cross entropy suggests a new deep network architecture, namely the Max-Min network, which can learn from less labeled data while maintaining good prediction performance. Our experiments demonstrate that the NRM with the RPN and the Max-Min architecture exceeds or matches the-state-of-art on benchmarks including SVHN, CIFAR10, and CIFAR100 for semi-supervised and supervised learning tasks.
Towards a Near Universal Time Series Data Mining Tool: Introducing the Matrix Profile
The last decade has seen a flurry of research on all-pairs-similarity-search (or, self-join) for text, DNA, and a handful of other datatypes, and these systems have been applied to many diverse data mining problems. Surprisingly, however, little progress has been made on addressing this problem for time series subsequences. In this thesis, we have introduced a near universal time series data mining tool called matrix profile which solves the all-pairs-similarity-search problem and caches the output in an easy-to-access fashion. The proposed algorithm is not only parameter-free, exact and scalable, but also applicable for both single and multidimensional time series. By building time series data mining methods on top of matrix profile, many time series data mining tasks (e.g., motif discovery, discord discovery, shapelet discovery, semantic segmentation, and clustering) can be efficiently solved. Because the same matrix profile can be shared by a diverse set of time series data mining methods, matrix profile is versatile and computed-once-use-many-times data structure. We demonstrate the utility of matrix profile for many time series data mining problems, including motif discovery, discord discovery, weakly labeled time series classification, and representation learning on domains as diverse as seismology, entomology, music processing, bioinformatics, human activity monitoring, electrical power-demand monitoring, and medicine. We hope the matrix profile is not the end but the beginning of many more time series data mining projects.
An exploration of algorithmic discrimination in data and classification
Algorithmic discrimination is an important aspect when data is used for predictive purposes. This paper analyzes the relationships between discrimination and classification, data set partitioning, and decision models, as well as correlation. The paper uses real world data sets to demonstrate the existence of discrimination and the independence between the discrimination of data sets and the discrimination of classification models.
Deep Weighted Averaging Classifiers
Recent advances in deep learning have achieved impressive gains in classification accuracy on a variety of types of data, including images and text. Despite these gains, however, concerns have been raised about the interpretability of these models, as well as issues related to calibration and robustness. In this paper we propose a simple way to modify any conventional deep architecture to automatically provide more transparent explanations for classification decisions, as well as an intuitive notion of the credibility of each prediction. Specifically, we draw on ideas from nonparametric kernel regression, and propose to predict labels based on a weighted sum of training instances, where the weights are determined by distance in a learned instance-embedding space. Working within the framework of conformal methods, we propose a new measure of nonconformity suggested by our model, and experimentally validate the accompanying theoretical expectations, demonstrating improved transparency, controlled error rates, and robustness to out-of-domain data, without compromising on accuracy or calibration.
Online Off-policy Prediction
This paper investigates the problem of online prediction learning, where learning proceeds continuously as the agent interacts with an environment. The predictions made by the agent are contingent on a particular way of behaving, represented as a value function. However, the behavior used to select actions and generate the behavior data might be different from the one used to define the predictions, and thus the samples are generated off-policy. The ability to learn behavior-contingent predictions online and off-policy has long been advocated as a key capability of predictive-knowledge learning systems but remained an open algorithmic challenge for decades. The issue lies with the temporal difference (TD) learning update at the heart of most prediction algorithms: combining bootstrapping, off-policy sampling and function approximation may cause the value estimate to diverge. A breakthrough came with the development of a new objective function that admitted stochastic gradient descent variants of TD. Since then, many sound online off-policy prediction algorithms have been developed, but there has been limited empirical work investigating the relative merits of all the variants. This paper aims to fill these empirical gaps and provide clarity on the key ideas behind each method. We summarize the large body of literature on off-policy learning, focusing on 1- methods that use computation linear in the number of features and are convergent under off-policy sampling, and 2- other methods which have proven useful with non-fixed, nonlinear function approximation. We provide an empirical study of off-policy prediction methods in two challenging microworlds. We report each method’s parameter sensitivity, empirical convergence rate, and final performance, providing new insights that should enable practitioners to successfully extend these new methods to large-scale applications.[Abridged abstract]
Training Generative Adversarial Networks with Weights
The impressive success of Generative Adversarial Networks (GANs) is often overshadowed by the difficulties in their training. Despite the continuous efforts and improvements, there are still open issues regarding their convergence properties. In this paper, we propose a simple training variation where suitable weights are defined and assist the training of the Generator. We provide theoretical arguments why the proposed algorithm is better than the baseline training in the sense of speeding up the training process and of creating a stronger Generator. Performance results showed that the new algorithm is more accurate in both synthetic and image datasets resulting in improvements ranging between 5% and 50%.
A Variational Inference Algorithm for BKMR in the Cross-Sectional Setting
The identification of pollutant effects is an important task in environmental health. Bayesian kernel machine regression (BKMR) is a standard tool for inference of individual-level pollutant health-effects, and we present a mean field Variational Inference (VI) algorithm for quick inference when only a single response per individual is recorded. Using simulation studies in the case of informative priors, we show that VI, although fast, produces anti-conservative credible intervals of covariate effects and conservative credible intervals for pollutant effects. To correct the coverage probabilities of covariate effects, we propose a simple Generalized Least Squares (GLS) approach that induces conservative credible intervals. We also explore using BKMR with flat priors and find that, while slower than the case with informative priors, this approach yields uncorrected credible intervals for covariate effects with coverage probabilities that are much closer to the nominal 95% level. We further note that fitting BKMR by VI provides a remarkable improvement in speed over existing MCMC methods.
An Experiment with Bands and Dimensions in Classifiers
This paper presents a new version of an oscillating error classifier that has added fixed value ranges through bands, for each column or feature of the input dataset. It is shown that some of the data can be correctly classified through using fixed value ranges only, while the rest can be classified by using the classifier technique. It also presents the classifier in terms of a biological model of neurons and neuron links.
State Aggregation Learning from Markov Transition Data
State aggregation is a model reduction method rooted in control theory and reinforcement learning. It reduces the complexity of engineering systems by mapping the system’s states into a small number of meta-states. In this paper, we study the unsupervised estimation of unknown state aggregation structures based on Markov trajectories. We formulate the state aggregation of Markov processes into a nonnegative factorization model, where left and right factor matrices correspond to aggregation and disaggregation distributions respectively. By leveraging techniques developed in the context of topic modeling, we propose an efficient polynomial-time algorithm for computing the estimated state aggregation model. Under some ‘anchor state’ assumption, we show that one can reliably recover the state aggregation structure from sample transitions with high probability. Sharp divergence error bounds are proved for the estimated aggregation and disaggregation distributions, and experiments with Manhattan traffic data are provided.
Deep Probabilistic Ensembles: Approximate Variational Inference through KL Regularization
In this paper, we introduce Deep Probabilistic Ensembles (DPEs), a scalable technique that uses a regularized ensemble to approximate a deep Bayesian Neural Network (BNN). We do so by incorporating a KL divergence penalty term into the training objective of an ensemble, derived from the evidence lower bound used in variational inference. We evaluate the uncertainty estimates obtained from our models for active learning on visual classification, consistently outperforming baselines and existing approaches.
OverSketch: Approximate Matrix Multiplication for the Cloud
We propose OverSketch, an approximate algorithm for distributed matrix multiplication in serverless computing. OverSketch leverages ideas from matrix sketching and high-performance computing to enable cost-efficient multiplication that is resilient to faults and straggling nodes pervasive in low-cost serverless architectures. We establish statistical guarantees on the accuracy of OverSketch and empirically validate our results by solving a large-scale linear program using interior-point methods and demonstrate a 34% reduction in compute time on AWS Lambda.
Bidirectional Quaternion Long-Short Term Memory Recurrent Neural Networks for Speech Recognition

CAB: Continuous Adaptive Blending Estimator for Policy Evaluation and Learning
The ability to perform offline A/B-testing and off-policy learning using logged contextual bandit feedback is highly desirable in a broad range of applications, including recommender systems, search engines, ad placement, and personalized health care. Both offline A/B-testing and off-policy learning require a counterfactual estimator that evaluates how some new policy would have performed, if it had been used instead of the logging policy. This paper proposes a new counterfactual estimator – called Continuous Adaptive Blending (CAB) – for this policy evaluation problem that combines regression and weighting approaches for an effective bias/variance trade-off. It can be substantially less biased than clipped Inverse Propensity Score weighting and the Direct Method, and it can have less variance compared with Doubly Robust and IPS estimators. Experimental results show that CAB provides excellent and reliable estimation accuracy compared to other blended estimators, and – unlike the SWITCH estimator – is sub-differentiable such that it can be used for learning.
ACE: An Actor Ensemble Algorithm for Continuous Control with Tree Search
In this paper, we propose an actor ensemble algorithm, named ACE, for continuous control with a deterministic policy in reinforcement learning. In ACE, we use actor ensemble (i.e., multiple actors) to search the global maxima of the critic. Besides the ensemble perspective, we also formulate ACE in the option framework by extending the option-critic architecture with deterministic intra-option policies, revealing a relationship between ensemble and options. Furthermore, we perform a look-ahead tree search with those actors and a learned value prediction model, resulting in a refined value estimation. We demonstrate a significant performance boost of ACE over DDPG and its variants in challenging physical robot simulators.
Frank-Wolfe Algorithm for Exemplar Selection
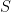
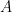


Scalable Bottom-up Subspace Clustering using FP-Trees for High Dimensional Data
Subspace clustering aims to find groups of similar objects (clusters) that exist in lower dimensional subspaces from a high dimensional dataset. It has a wide range of applications, such as analysing high dimensional sensor data or DNA sequences. However, existing algorithms have limitations in finding clusters in non-disjoint subspaces and scaling to large data, which impinge their applicability in areas such as bioinformatics and the Internet of Things. We aim to address such limitations by proposing a subspace clustering algorithm using a bottom-up strategy. Our algorithm first searches for base clusters in low dimensional subspaces. It then forms clusters in higher-dimensional subspaces using these base clusters, which we formulate as a frequent pattern mining problem. This formulation enables efficient search for clusters in higher-dimensional subspaces, which is done using FP-trees. The proposed algorithm is evaluated against traditional bottom-up clustering algorithms and state-of-the-art subspace clustering algorithms. The experimental results show that the proposed algorithm produces clusters with high accuracy, and scales well to large volumes of data. We also demonstrate the algorithm’s performance using real-life data, including ten genomic datasets and a car parking occupancy dataset.
Distributionally Robust Graphical Models
In many structured prediction problems, complex relationships between variables are compactly defined using graphical structures. The most prevalent graphical prediction methods—probabilistic graphical models and large margin methods—have their own distinct strengths but also possess significant drawbacks. Conditional random fields (CRFs) are Fisher consistent, but they do not permit integration of customized loss metrics into their learning process. Large-margin models, such as structured support vector machines (SSVMs), have the flexibility to incorporate customized loss metrics, but lack Fisher consistency guarantees. We present adversarial graphical models (AGM), a distributionally robust approach for constructing a predictor that performs robustly for a class of data distributions defined using a graphical structure. Our approach enjoys both the flexibility of incorporating customized loss metrics into its design as well as the statistical guarantee of Fisher consistency. We present exact learning and prediction algorithms for AGM with time complexity similar to existing graphical models and show the practical benefits of our approach with experiments.
Improved Audio Embeddings by Adjacency-Based Clustering with Applications in Spoken Term Detection
Embedding audio signal segments into vectors with fixed dimensionality is attractive because all following processing will be easier and more efficient, for example modeling, classifying or indexing. Audio Word2Vec previously proposed was shown to be able to represent audio segments for spoken words as such vectors carrying information about the phonetic structures of the signal segments. However, each linguistic unit (word, syllable, phoneme in text form) corresponds to unlimited number of audio segments with vector representations inevitably spread over the embedding space, which causes some confusion. It is therefore desired to better cluster the audio embeddings such that those corresponding to the same linguistic unit can be more compactly distributed. In this paper, inspired by Siamese networks, we propose some approaches to achieve the above goal. This includes identifying positive and negative pairs from unlabeled data for Siamese style training, disentangling acoustic factors such as speaker characteristics from the audio embedding, handling unbalanced data distribution, and having the embedding processes learn from the adjacency relationships among data points. All these can be done in an unsupervised way. Improved performance was obtained in preliminary experiments on the LibriSpeech data set, including clustering characteristics analysis and applications of spoken term detection.
YASENN: Explaining Neural Networks via Partitioning Activation Sequences
We introduce a novel approach to feed-forward neural network interpretation based on partitioning the space of sequences of neuron activations. In line with this approach, we propose a model-specific interpretation method, called YASENN. Our method inherits many advantages of model-agnostic distillation, such as an ability to focus on the particular input region and to express an explanation in terms of features different from those observed by a neural network. Moreover, examination of distillation error makes the method applicable to the problems with low tolerance to interpretation mistakes. Technically, YASENN distills the network with an ensemble of layer-wise gradient boosting decision trees and encodes the sequences of neuron activations with leaf indices. The finite number of unique codes induces a partitioning of the input space. Each partition may be described in a variety of ways, including examination of an interpretable model (e.g. a logistic regression or a decision tree) trained to discriminate between objects of those partitions. Our experiments provide an intuition behind the method and demonstrate revealed artifacts in neural network decision making.
RoboTurk: A Crowdsourcing Platform for Robotic Skill Learning through Imitation
Amalgamating Knowledge towards Comprehensive Classification
With the rapid development of deep learning, there have been an unprecedentedly large number of trained deep network models available online. Reusing such trained models can significantly reduce the cost of training the new models from scratch, if not infeasible at all as the annotations used for the training original networks are often unavailable to public. We propose in this paper to study a new model-reusing task, which we term as \emph{knowledge amalgamation}. Given multiple trained teacher networks, each of which specializes in a different classification problem, the goal of knowledge amalgamation is to learn a lightweight student model capable of handling the comprehensive classification. We assume no other annotations except the outputs from the teacher models are available, and thus focus on extracting and amalgamating knowledge from the multiple teachers. To this end, we propose a pilot two-step strategy to tackle the knowledge amalgamation task, by learning first the compact feature representations from teachers and then the network parameters in a layer-wise manner so as to build the student model. We apply this approach to four public datasets and obtain very encouraging results: even without any human annotation, the obtained student model is competent to handle the comprehensive classification task and in most cases outperforms the teachers in individual sub-tasks.
Multi-Task Graph Autoencoders
Image Smoothing via Unsupervised Learning
THORS: An Efficient Approach for Making Classifiers Cost-sensitive
In this paper, we propose an effective THresholding method based on ORder Statistic, called THORS, to convert an arbitrary scoring-type classifier, which can induce a continuous cumulative distribution function of the score, into a cost-sensitive one. The procedure, uses order statistic to find an optimal threshold for classification, requiring almost no knowledge of classifiers itself. Unlike common data-driven methods, we analytically show that THORS has theoretical guaranteed performance, theoretical bounds for the costs and lower time complexity. Coupled with empirical results on several real-world data sets, we argue that THORS is the preferred cost-sensitive technique.
SocialGCN: An Efficient Graph Convolutional Network based Model for Social Recommendation
Collaborative Filtering (CF) is one of the most successful approaches for recommender systems. With the emergence of online social networks, social recommendation has become a popular research direction. Most of these social recommendation models utilized each user’s local neighbors’ preferences to alleviate the data sparsity issue in CF. However, they only considered the local neighbors of each user and neglected the process that users’ preferences are influenced as information diffuses in the social network. Recently, Graph Convolutional Networks~(GCN) have shown promising results by modeling the information diffusion process in graphs that leverage both graph structure and node feature information. To this end, in this paper, we propose an effective graph convolutional neural network based model for social recommendation. Based on a classical CF model, the key idea of our proposed model is that we borrow the strengths of GCNs to capture how users’ preferences are influenced by the social diffusion process in social networks. The diffusion of users’ preferences is built on a layer-wise diffusion manner, with the initial user embedding as a function of the current user’s features and a free base user latent vector that is not contained in the user feature. Similarly, each item’s latent vector is also a combination of the item’s free latent vector, as well as its feature representation. Furthermore, we show that our proposed model is flexible when user and item features are not available. Finally, extensive experimental results on two real-world datasets clearly show the effectiveness of our proposed model.
Construction and Quality Evaluation of Heterogeneous Hierarchical Topic Models
In our work, we propose to represent HTM as a set of flat models, or layers, and a set of topical hierarchies, or edges. We suggest several quality measures for edges of hierarchical models, resembling those proposed for flat models. We conduct an assessment experimentation and show strong correlation between the proposed measures and human judgement on topical edge quality. We also introduce heterogeneous algorithm to build hierarchical topic models for heterogeneous data sources. We show how making certain adjustments to learning process helps to retain original structure of customized models while allowing for slight coherent modifications for new documents. We evaluate this approach using the proposed measures and show that the proposed heterogeneous algorithm significantly outperforms the baseline concat approach. Finally, we implement our own ESE called Rysearch, which demonstrates the potential of ARTM approach for visualizing large heterogeneous document collections.
Wasserstein Variational Gradient Descent: From Semi-Discrete Optimal Transport to Ensemble Variational Inference
Particle-based variational inference offers a flexible way of approximating complex posterior distributions with a set of particles. In this paper we introduce a new particle-based variational inference method based on the theory of semi-discrete optimal transport. Instead of minimizing the KL divergence between the posterior and the variational approximation, we minimize a semi-discrete optimal transport divergence. The solution of the resulting optimal transport problem provides both a particle approximation and a set of optimal transportation densities that map each particle to a segment of the posterior distribution. We approximate these transportation densities by minimizing the KL divergence between a truncated distribution and the optimal transport solution. The resulting algorithm can be interpreted as a form of ensemble variational inference where each particle is associated with a local variational approximation.
Causaltoolbox—Estimator Stability for Heterogeneous Treatment Effects
Estimating heterogeneous treatment effects has become extremely important in many fields and often life changing decisions for individuals are based on these estimates, for example choosing a medical treatment for a patient. In the recent years, a variety of techniques for estimating heterogeneous treatment effects, each making subtly different assumptions, have been suggested. Unfortunately, there are no compelling approaches that allow identification of the procedure that has assumptions that hew closest to the process generating the data set under study and researchers often select just one estimator. This approach risks making inferences based on incorrect assumptions and gives the experimenter too much scope for p-hacking. A single estimator will also tend to overlook patterns other estimators would have picked up. We believe that the conclusion of many published papers might change had a different estimator been chosen and we suggest that practitioners should evaluate many estimators and assess their similarity when investigating heterogeneous treatment effects. We demonstrate this by applying 32 different estimation procedures to an emulated observational data set; this analysis shows that different estimation procedures may give starkly different estimates. We also provide an extensible \texttt{R} package which makes it straightforward for practitioners to apply our analysis to their data.
Fused Gromov-Wasserstein distance for structured objects: theoretical foundations and mathematical properties
Optimal transport theory has recently found many applications in machine learning thanks to its capacity for comparing various machine learning objects considered as distributions. The Kantorovitch formulation, leading to the Wasserstein distance, focuses on the features of the elements of the objects but treat them independently, whereas the Gromov-Wasserstein distance focuses only on the relations between the elements, depicting the structure of the object, yet discarding its features. In this paper we propose to extend these distances in order to encode simultaneously both the feature and structure informations, resulting in the Fused Gromov-Wasserstein distance. We develop the mathematical framework for this novel distance, prove its metric and interpolation properties and provide a concentration result for the convergence of finite samples. We also illustrate and interpret its use in various contexts where structured objects are involved.
Interpreting the Ising Model: The Input Matters

Emerging Applications of Reversible Data Hiding
Reversible data hiding (RDH) is one special type of information hiding, by which the host sequence as well as the embedded data can be both restored from the marked sequence without loss. Beside media annotation and integrity authentication, recently some scholars begin to apply RDH in many other fields innovatively. In this paper, we summarize these emerging applications, including steganography, adversarial example, visual transformation, image processing, and give out the general frameworks to make these operations reversible. As far as we are concerned, this is the first paper to summarize the extended applications of RDH.
Connecting Knowledge Compilation Classes and Width Parameters
The field of knowledge compilation establishes the tractability of many tasks by studying how to compile them to Boolean circuit classes obeying some requirements such as structuredness, decomposability, and determinism. However, in other settings such as intensional query evaluation on databases, we obtain Boolean circuits that satisfy some width bounds, e.g., they have bounded treewidth or pathwidth. In this work, we give a systematic picture of many circuit classes considered in knowledge compilation and show how they can be systematically connected to width measures, through upper and lower bounds. Our upper bounds show that bounded-treewidth circuits can be constructively converted to d-SDNNFs, in time linear in the circuit size and singly exponential in the treewidth; and that bounded-pathwidth circuits can similarly be converted to uOBDDs. We show matching lower bounds on the compilation of monotone DNF or CNF formulas to structured targets, assuming a constant bound on the arity (size of clauses) and degree (number of occurrences of each variable): any d-SDNNF (resp., SDNNF) for such a DNF (resp., CNF) must be of exponential size in its treewidth, and the same holds for uOBDDs (resp., n-OBDDs) when considering pathwidth. Unlike most previous work, our bounds apply to any formula of this class, not just a well-chosen family. Hence, we show that pathwidth and treewidth respectively characterize the efficiency of compiling monotone DNFs to uOBDDs and d-SDNNFs with compilation being singly exponential in the corresponding width parameter. We also show that our lower bounds on CNFs extend to unstructured compilation targets, with an exponential lower bound in the treewidth (resp., pathwidth) when compiling monotone CNFs of constant arity and degree to DNNFs (resp., nFBDDs).
Compositional Language Understanding with Text-based Relational Reasoning
Neural networks for natural language reasoning have largely focused on extractive, fact-based question-answering (QA) and common-sense inference. However, it is also crucial to understand the extent to which neural networks can perform relational reasoning and combinatorial generalization from natural language—abilities that are often obscured by annotation artifacts and the dominance of language modeling in standard QA benchmarks. In this work, we present a novel benchmark dataset for language understanding that isolates performance on relational reasoning. We also present a neural message-passing baseline and show that this model, which incorporates a relational inductive bias, is superior at combinatorial generalization compared to a traditional recurrent neural network approach.
Adaptive penalization in high-dimensional regression and classification with external covariates using variational Bayes
Penalization schemes like Lasso or ridge regression are routinely used to regress a response of interest on a high-dimensional set of potential predictors. Despite being decisive, the question of the relative strength of penalization is often glossed over and only implicitly determined by the scale of individual predictors. At the same time, additional information on the predictors is available in many applications but left unused. Here, we propose to make use of such external covariates to adapt the penalization in a data-driven manner. We present a method that differentially penalizes feature groups defined by the covariates and adapts the relative strength of penalization to the information content of each group. Using techniques from the Bayesian tool-set our procedure combines shrinkage with feature selection and provides a scalable optimization scheme. We demonstrate in simulations that the method accurately recovers the true effect sizes and sparsity patterns per feature group. Furthermore, it leads to an improved prediction performance in situations where the groups have strong differences in dynamic range. In applications to data from high-throughput biology, the method enables re-weighting the importance of feature groups from different assays. Overall, using available covariates extends the range of applications of penalized regression, improves model interpretability and can improve prediction performance. We provide an open-source implementation of the method in the R package graper.
Instantly Deployable Expert Knowledge – Networks of Knowledge Engines
Knowledge and information are becoming the primary resources of the emerging information society. To exploit the potential of available expert knowledge, comprehension and application skills (i.e. expert competences) are necessary. The ability to acquire these skills is limited for any individual human. Consequently, the capacities to solve problems based on human knowledge in a manual (i.e. mental) way are strongly limited. We envision a new systemic approach to enable scalable knowledge deployment without expert competences. Eventually, the system is meant to instantly deploy humanity’s total knowledge in full depth for every individual challenge. To this end, we propose a socio-technical framework that transforms expert knowledge into a solution creation system. Knowledge is represented by automated algorithms (knowledge engines). Executable compositions of knowledge engines (networks of knowledge engines) generate requested individual information at runtime. We outline how these knowledge representations could yield legal, ethical and social challenges and nurture new business and remuneration models on knowledge. We identify major technological and economic concepts that are already pushing the boundaries in knowledge utilisation: e.g. in artificial intelligence, knowledge bases, ontologies, advanced search tools, automation of knowledge work, the API economy. We indicate impacts on society, economy and labour. Existing developments are linked, including a specific use case in engineering design.
Estimating Network Structure from Incomplete Event Data
Multivariate Bernoulli autoregressive (BAR) processes model time series of events in which the likelihood of current events is determined by the times and locations of past events. These processes can be used to model nonlinear dynamical systems corresponding to criminal activity, responses of patients to different medical treatment plans, opinion dynamics across social networks, epidemic spread, and more. Past work examines this problem under the assumption that the event data is complete, but in many cases only a fraction of events are observed. Incomplete observations pose a significant challenge in this setting because the unobserved events still govern the underlying dynamical system. In this work, we develop a novel approach to estimating the parameters of a BAR process in the presence of unobserved events via an unbiased estimator of the complete data log-likelihood function. We propose a computationally efficient estimation algorithm which approximates this estimator via Taylor series truncation and establish theoretical results for both the statistical error and optimization error of our algorithm. We further justify our approach by testing our method on both simulated data and a real data set consisting of crimes recorded by the city of Chicago.
A note on the prediction error of principal component regression
We analyse the prediction error of principal component regression (PCR) and prove non-asymptotic upper bounds for the corresponding squared risk. Under mild assumptions, we conclude that PCR performs as well as the oracle method obtained by replacing empirical principal components by their population counterparts. Our approach relies on perturbation bounds for the excess risk of principal component analysis.
Data Selection with Feature Decay Algorithms Using an Approximated Target Side
Data selection techniques applied to neural machine translation (NMT) aim to increase the performance of a model by retrieving a subset of sentences for use as training data. One of the possible data selection techniques are transductive learning methods, which select the data based on the test set, i.e. the document to be translated. A limitation of these methods to date is that using the source-side test set does not by itself guarantee that sentences are selected with correct translations, or translations that are suitable given the test-set domain. Some corpora, such as subtitle corpora, may contain parallel sentences with inaccurate translations caused by localization or length restrictions. In order to try to fix this problem, in this paper we propose to use an approximated target-side in addition to the source-side when selecting suitable sentence-pairs for training a model. This approximated target-side is built by pre-translating the source-side. In this work, we explore the performance of this general idea for one specific data selection approach called Feature Decay Algorithms (FDA). We train German-English NMT models on data selected by using the test set (source), the approximated target side, and a mixture of both. Our findings reveal that models built using a combination of outputs of FDA (using the test set and an approximated target side) perform better than those solely using the test set. We obtain a statistically significant improvement of more than 1.5 BLEU points over a model trained with all data, and more than 0.5 BLEU points over a strong FDA baseline that uses source-side information only.
Policy Certificates: Towards Accountable Reinforcement Learning
The performance of a reinforcement learning algorithm can vary drastically during learning because of exploration. Existing algorithms provide little information about their current policy’s quality before executing it, and thus have limited use in high-stakes applications like healthcare. In this paper, we address such a lack of accountability by proposing that algorithms output policy certificates, which upper bound the suboptimality in the next episode, allowing humans to intervene when the certified quality is not satisfactory. We further present a new learning framework (IPOC) for finite-sample analysis with policy certificates, and develop two IPOC algorithms that enjoy guarantees for the quality of both their policies and certificates.
Characterizing Well-behaved vs. Pathological Deep Neural Network Architectures
We introduce a principled approach, requiring only mild assumptions, for the characterization of deep neural networks at initialization. Our approach applies both to fully-connected and convolutional networks and incorporates the commonly used techniques of batch normalization and skip-connections. Our key insight is to consider the evolution with depth of statistical moments of signal and sensitivity, thereby characterizing the well-behaved or pathological behaviour of input-output mappings encoded by different choices of architecture. We establish: (i) for feedforward networks with and without batch normalization, depth multiplicativity inevitably leads to ill-behaved moments and distributional pathologies; (ii) for residual networks, on the other hand, the mechanism of identity skip-connection induces power-law rather than exponential behaviour, leading to well-behaved moments and no distributional pathology.
• Uploading Brain into Computer: Whom to Upload First?• Distilling Critical Paths in Convolutional Neural Networks• Attention-Mechanism-based Tracking Method for Intelligent Internet of Vehicles• Vehicle Tracking Using Surveillance with Multimodal Data Fusion• Demystifying Neural Network Filter Pruning• MAMMO: A Deep Learning Solution for Facilitating Radiologist-Machine Collaboration in Breast Cancer Diagnosis• A mixed signal architecture for convolutional neural networks• Automated Diagnosis of Lymphoma with Digital Pathology Images Using Deep Learning• Quaternion Convolutional Neural Networks for Heterogeneous Image Processing• Finding and Following of Honeycombing Regions in Computed Tomography Lung Images by Deep Learning• When Not to Classify: Detection of Reverse Engineering Attacks on DNN Image Classifiers• Similarity Learning with Higher-Order Proximity for Brain Network Analysis• New interaction potentials for alkali and alkaline-earth aluminosilicate glasses• Topological Semantics for Lumped Parameter Systems Modeling• Learning Bone Suppression from Dual Energy Chest X-rays using Adversarial Networks• Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge• Toward Efficient Breast Cancer Diagnosis and Survival Prediction Using L-Perceptron• Advanced Denoising for X-ray Ptychography• On exponential convergence of SGD in non-convex over-parametrized learning• Identifying ground scatter and ionospheric scatter signals by using their fine structure at Ekaterinburg decameter coherent radar• Un-normalized hypergraph p-Laplacian based semi-supervised learning methods• Blockchain and human episodic memory• Finite element approximation of non-Markovian random fields• An amplitudes-perturbation data augmentation method in convolutional neural networks for EEG decoding• Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network• Towards a full solution of the large N double-scaled SYK model• Consistency of quasi-maximum likelihood for processes with asymMetric laplacian innovation• Weighted Upper Edge Cover: Complexity and Approximability• Fast Neural Chinese Word Segmentation for Long Sentences• GPU Acceleration of an Established Solar MHD Code using OpenACC• Embedded polarizing filters to separate diffuse and specular reflection• Rate of convergence for the weighted Hermite variations of the fractional Brownian motion• Evaluating the Ability of LSTMs to Learn Context-Free Grammars• Mixing Time of Metropolis-Hastings for Bayesian Community Detection• Multi-View Network Embedding Via Graph Factorization Clustering and Co-Regularized Multi-View Agreement• Modelling the Hidden Flexibility of Clustered Unit Commitment• MixTrain: Scalable Training of Formally Robust Neural Networks• Molecular Transformer for Chemical Reaction Prediction and Uncertainty Estimation• Characterizing Task Completion Latencies in Fog Computing• Building Corpora for Single-Channel Speech Separation Across Multiple Domains• Planning Low-Carbon Campus Energy Hubs• Sparse and Smooth Signal Estimation: Convexification of L0 Formulations• Strong consistency of kernel estimator in a semiparametric regression model• An upper bound on the Wiener Index of a k-connected graph• Robust multiple-set linear canonical analysis based on minimum covariance determinant estimator• Gramian-Based Optimization for the Analysis and Control of Traffic Networks• Partitions and deformed cumulants of type B with remarks on the Blitvi{ć} model• The Set-Maxima Problem in a Geometric Setting• Flow-Cut Gaps and Face Covers in Planar Graphs• Finding Independent Transversals Efficiently• Automatic Assessment of Full Left Ventricular Coverage in Cardiac Cine Magnetic Resonance Imaging with Fisher-Discriminative 3D CNN• Training Domain Specific Models for Energy-Efficient Object Detection• Quasi-Newton Optimization in Deep Q-Learning for Playing ATARI Games• Reconstructing Speech Stimuli From Human Auditory Cortex Activity Using a WaveNet Approach• Seismic Signal Denoising and Decomposition Using Deep Neural Networks• The Sitting Closer to Friends than Enemies Problem in the Circumference• Proceedings of the 2018 Workshop on Compositional Approaches in Physics, NLP, and Social Sciences• Photonic Recurrent Ising Sampler• The planning problem in Mean Field Games as regularized mass transport• Investigating First Returns: The Effect of Multicolored Vectors• The Relationship Between Pascal’s Triangle and Random Walks• The RLLChatbot: a solution to the ConvAI Challenge• Combinatorics of cluster structures in Schubert varieties• Static Data Structure Lower Bounds Imply Rigidity• Nonparametric Analysis of Finite Mixtures• CNN-based MultiChannel End-to-End Speech Recognition for everyday home environments• Learning acoustic word embeddings with phonetically associated triplet network• Brownian winding fields• Style Separation and Synthesis via Generative Adversarial Networks• View Inter-Prediction GAN: Unsupervised Representation Learning for 3D Shapes by Learning Global Shape Memories to Support Local View Predictions• Y^2Seq2Seq: Cross-Modal Representation Learning for 3D Shape and Text by Joint Reconstruction and Prediction of View and Word Sequences• Component-based Attention for Large-scale Trademark Retrieval• On the degree pairs of a graph• The relationship between linguistic expression and symptoms of depression, anxiety, and suicidal thoughts: A longitudinal study of blog content• Bayesian State Estimation for Unobservable Distribution Systems via Deep Learning• Early Prediction of Acute Kidney Injury in Critical Care Setting Using Clinical Notes• Learning to Steer by Mimicking Features from Heterogeneous Auxiliary Networks• Weighted Matchings via Unweighted Augmentations• Signal Detection for Faster than Nyquist Transmission Based on Deep Learning• Learning to Compose Topic-Aware Mixture of Experts for Zero-Shot Video Captioning• Promising Accurate Prefix Boosting for sequence-to-sequence ASR• Uncertainty in Quantum Rule-Based Systems• Median Binary-Connect Method and a Binary Convolutional Neural Nework for Word Recognition• Modeling Dynamics of Social Network and Opinion at Individual Level• GeoSay: A Geometric Saliency for Extracting Buildings in Remote Sensing Images• Deep Neural Networks for ECG-free Cardiac Phase and End-Diastolic Frame Detection on Coronary Angiographies• New Parameters on MDS Self-dual Codes over Finite Fields• PaDNet: Pan-Density Crowd Counting• A Flexible Spatial Autoregressive Modelling Framework for Mixed Covariates of Multiple Data Types• Remarks on Nash equilibria in mean field game models with a major player• A new exact approach for the Bilevel Knapsack with Interdiction Constraints• Growth-fragmentation processes in Brownian motion indexed by the Brownian tree• Differentiation and Passivity for Control of Brayton-Moser Systems• Neural Image Compression for Gigapixel Histopathology Image Analysis• Effects of Dataset properties on the training of GANs• Entropy Rate of Time-Varying Wireless Networks• Position filtering-based non-orthogonal multiple access in mobile scenarios• Growing Critical: Self-Organized Criticality in a Developing Neural System• Deep Reinforcement Learning based Modulation and Coding Scheme Selection in Cognitive Heterogeneous Networks• Baselines for Reinforcement Learning in Text Games• Monotone Increment Processes, Classical Markov Processes and Loewner Chains• In SDP relaxations, inaccurate solvers do robust optimization• Using Stock Prices as Ground Truth in Sentiment Analysis to Generate Profitable Trading Signals• Iterative Marginal Maximum Likelihood DOD and DOA Estimation for MIMO Radar in the Presence of SIRP Clutter• Power and Leadership: A Complex Systems Science Approach Part I – Representation and Dynamics• Private Information Retrieval Schemes with Regenerating Codes• Spatial and Temporal white noises under sublinear G-expectation• microNER: A Micro-Service for German Named Entity Recognition based on BiLSTM-CRF• Joint Tx-Rx Beamforming and Power Allocation for 5G Millimeter-Wave Non-Orthogonal Multiple Access (MmWave-NOMA) Networks• Transfer Learning from LDA to BiLSTM-CNN for Offensive Language Detection in Twitter• User Fairness Non-orthogonal Multiple Access (NOMA) for 5G Millimeter-Wave Communications with Analog Beamforming• DOD-CNN: Doubly-injecting Object Information for Event Recognition• Kernel Adaptive Filtering for Nonlinearity-Tolerant Optical Direct Detection Systems• DP-4-colorability of two classes of planar graphs• Flexible Representative Democracy: An Introduction with Binary Issues• A note on existence of free Stein kernels• Supervisor Obfuscation Against Actuator Enablement Attack• A Tight Analysis of Bethe Approximation for Permanent• Model Inconsistent but Correlated Noise: Multi-view Subspace Learning with Regularized Mixture of Gaussians• On the acceleration of forward-backward splitting via an inexact Newton method• Every Testable (Infinite) Property of Bounded-Degree Graphs Contains an Infinite Hyperfinite Subproperty• On the Minimal Edge Density of $K_4$-free 6-critical Graphs• Multi-branch Convolutional Neural Network for Multiple Sclerosis Lesion Segmentation• Generative Adversarial Policy Networks for Behavioural Repertoire• SurReal: enhancing Surgical simulation Realism using style transfer• Scalable and Energy-Efficient Millimeter Massive MIMO Architectures: Reflect-Array and Transmit-Array Antennas• Instance Retrieval at Fine-grained Level Using Multi-Attribute Recognition• Simulation-based inference methods for partially observed Markov model via the R package is2• Bicoherence analysis of nonstationary and nonlinear processes• Infinite arc-transitive and highly-arc-transitive digraphs• Maximum Distance Sub-Lattice Problem• $O(\log^2k/\log\log{k})$-Approximation Algorithm for Directed Steiner Tree: A Tight Quasi-Polynomial-Time Algorithm• Glycerol confined in zeolitic imidazolate frameworks: The temperature-dependent cooperativity length scale of glassy freezing• Scale-free collaboration networks: An author name disambiguation perspective• Branch and bound algorithm for the traveling salesman problem is not a direct type algorithm• A Holistic Visual Place Recognition Approach using Lightweight CNNs for Severe ViewPoint and Appearance Changes• Subtractive Magic and Antimagic Total Labeling for Basic Families of Graphs• Computing the Value of Computation for Planning• IMS at the PolEval 2018: A Bulky Ensemble Depedency Parser meets 12 Simple Rules for Predicting Enhanced Dependencies in Polish• Perfectly nested circuits• Adapting End-to-End Neural Speaker Verification to New Languages and Recording Conditions with Adversarial Training• FLOPs as a Direct Optimization Objective for Learning Sparse Neural Networks• An explicit formula for the distance characteristic polynomial of threshold graphs• Generative Adversarial Speaker Embedding Networks for Domain Robust End-to-End Speaker Verification• Prototypical Clustering Networks for Dermatological Disease Diagnosis• Synchronization in Network Geometries with Finite Spectral Dimension• Unconventional Arterial Intersection Designs under Connected and Automated Vehicle Environment: A Survey• Class-conditional embeddings for music source separation• Counting restricted orientations of random graphs• Forging new worlds: high-resolution synthetic galaxies with chained generative adversarial networks
Like this:
Like Loading…
Related