ADEPOS: Anomaly Detection based Power Saving for Predictive Maintenance using Edge Computing
In industry 4.0, predictive maintenance(PM) is one of the most important applications pertaining to the Internet of Things(IoT). Machine learning is used to predict the possible failure of a machine before the actual event occurs. However, the main challenges in PM are (a) lack of enough data from failing machines, and (b) paucity of power and bandwidth to transmit sensor data to cloud throughout the lifetime of the machine. Alternatively, edge computing approaches reduce data transmission and consume low energy. In this paper, we propose Anomaly Detection based Power Saving(ADEPOS) scheme using approximate computing through the lifetime of the machine. In the beginning of the machines life, low accuracy computations are used when the machine is healthy. However, on the detection of anomalies, as time progresses, the system is switched to higher accuracy modes. We show using the NASA bearing dataset that using ADEPOS, we need 8.8X less neurons on average and based on post-layout results, the resultant energy savings are 6.4 to 6.65X
MDFS – MultiDimensional Feature Selection
Identification of informative variables in an information system is often performed using simple one-dimensional filtering procedures that discard information about interactions between variables. Such approach may result in removing some relevant variables from consideration. Here we present an R package MDFS (MultiDimensional Feature Selection) that performs identification of informative variables taking into account synergistic interactions between multiple descriptors and the decision variable. MDFS is an implementation of an algorithm based on information theory. Computational kernel of the package is implemented in C++. A high-performance version implemented in CUDA C is also available. The applications of MDFS are demonstrated using the well-known Madelon dataset that has synergistic variables by design. The dataset comes from the UCI Machine Learning Repository. It is shown that multidimensional analysis is more sensitive than one-dimensional tests and returns more reliable rankings of importance.
Understanding Deep Neural Networks Using Topological Data Analysis
Deep neural networks (DNN) are black box algorithms. They are trained using a gradient descent back propagation technique which trains weights in each layer for the sole goal of minimizing training error. Hence, the resulting weights cannot be directly explained. Using Topological Data Analysis (TDA) we can get an insight on how the neural network is thinking, specifically by analyzing the activation values of validation images as they pass through each layer.
Pymc-learn: Practical Probabilistic Machine Learning in Python
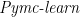


Session-based Recommendation with Graph Neural Networks
The problem of session-based recommendation aims to predict users’ actions based on anonymous sessions. Previous methods on the session-based recommendation most model a session as a sequence and capture users’ preference to make recommendations. Though achieved promising results, they fail to consider the complex items transitions among all session sequences, and are insufficient to obtain accurate users’ preference in the session. To better capture the structure of the user-click sessions and take complex transitions of items into account, we propose a novel method, i.e. Session-based Recommendation with Graph Neural Networks, SR-GNN for brevity. In the proposed method, session sequences are aggregated together and modeled as graph-structure data. Based on this graph, GNN can capture complex transitions of items, which are difficult to be revealed by the conventional sequential methods. Each session is then represented as the composition of the global preference and current interests of the session using an attention network. Extensive experiments conducted on two real datasets show that SR-GNN evidently outperforms the state-of-the-art session-based recommendation methods and always obtain stable performance with different connection schemes, session representations, and session lengths.
Can automated smoothing significantly improve benchmark time series classification algorithms?
tl;dr: no, it cannot, at least not on average on the standard archive problems. We assess whether using six smoothing algorithms (moving average, exponential smoothing, Gaussian filter, Savitzky-Golay filter, Fourier approximation and a recursive median sieve) could be automatically applied to time series classification problems as a preprocessing step to improve the performance of three benchmark classifiers (1-Nearest Neighbour with Euclidean and Dynamic Time Warping distances, and Rotation Forest). We found no significant improvement over unsmoothed data even when we set the smoothing parameter through cross validation. We are not claiming smoothing has no worth. It has an important role in exploratory analysis and helps with specific classification problems where domain knowledge can be exploited. What we observe is that the automatic application does not help and that we cannot explain the improvement of other time series classification algorithms over the baseline classifiers simply as a function of the absence of smoothing.
VizRec: A framework for secure data exploration via visual representation
Visual representations of data (visualizations) are tools of great importance and widespread use in data analytics as they provide users visual insight to patterns in the observed data in a simple and effective way. However, since visualizations tools are applied to sample data, there is a a risk of visualizing random fluctuations in the sample rather than a true pattern in the data. This problem is even more significant when visualization is used to identify interesting patterns among many possible possibilities, or to identify an interesting deviation in a pair of observations among many possible pairs, as commonly done in visual recommendation systems. We present VizRec, a framework for improving the performance of visual recommendation systems by quantifying the statistical significance of recommended visualizations. The proposed methodology allows to control the probability of misleading visual recommendations using both classical statistical testing procedures and a novel application of the Vapnik Chervonenkis (VC) dimension method which is a fundamental concept in statistical learning theory.
Modeling IoT-aware Business Processes – A State of the Art Report
This research report presents an analysis of the state of the art of modeling Internet of Things (IoT)-aware business processes. IOT links the physical world to the digital world. Traditionally, we would find information about events and processes in the physical world in the digital world entered by humans and humans using this information to control the physical world. In the IoT paradigm, the physical world is equipped with sensors and actuators to create a direct link with the digital world. Business processes are used to coordinate a complex environment including multiple actors for a common goal, typically in the context of administrative work. In the past few years, we have seen research efforts on the possibilities to model IoT- aware business processes, extending process coordination to real world entities directly. This set of research efforts is relatively small when compared to the overall research effort into the IoT and much of the work is still in the early research stage. To create a basis for a bridge between IoT and BPM, the goal of this report is to collect and analyze the state of the art of existing frameworks for modeling IoT-aware business processes.
A Method For Dynamic Ensemble Selection Based on a Filter and an Adaptive Distance to Improve the Quality of the Regions of Competence
Dynamic classifier selection systems aim to select a group of classifiers that is most adequate for a specific query pattern. This is done by defining a region around the query pattern and analyzing the competence of the classifiers in this region. However, the regions are often surrounded by noise which can difficult the classifier selection. This fact makes the performance of most dynamic selection systems no better than static selections. In this paper, we demonstrate that the performance dynamic selection systems end up limited by the quality of the regions extracted. Thereafter, we propose a new dynamic classifier selection that improves the regions of competence in order to achieve higher recognition rates. obtained from several classification databases show the proposed method not only increase the recognition performance but also decreases the computational cost.
Dialogue Natural Language Inference
Consistency is a long standing issue faced by dialogue models. In this paper, we frame the consistency of dialogue agents as natural language inference (NLI) and create a new natural language inference dataset called Dialogue NLI. We propose a method which demonstrates that a model trained on Dialogue NLI can be used to improve the consistency of a dialogue model, and evaluate the method with human evaluation and with automatic metrics on a suite of evaluation sets designed to measure a dialogue model’s consistency.
Ludometrics: Luck, and How to Measure It
Game theory is the study of tractable games which may be used to model more complex systems. Board games, video games and sports, however, are intractable by design, so ‘ludological’ theories about these games as complex phenomena should be grounded in empiricism. A first ‘ludometric’ concern is the empirical measurement of the amount of luck in various games. We argue against a narrow view of luck which includes only factors outside any player’s control, and advocate for a holistic definition of luck as complementary to the variation in effective skill within a population of players. We introduce two metrics for luck in a game for a given population – one information theoretical, and one Bayesian, and discuss the estimation of these metrics using sparse, high-dimensional regression techniques. Finally, we apply these techniques to compare the amount of luck between various professional sports, between Chess and Go, and between two hobby board games: Race for the Galaxy and Seasons.
Sequence Generation with Guider Network
Sequence generation with reinforcement learning (RL) has received significant attention recently. However, a challenge with such methods is the sparse-reward problem in the RL training process, in which a scalar guiding signal is often only available after an entire sequence has been generated. This type of sparse reward tends to ignore the global structural information of a sequence, causing generation of sequences that are semantically inconsistent. In this paper, we present a model-based RL approach to overcome this issue. Specifically, we propose a novel guider network to model the sequence-generation environment, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments show that the proposed method leads to improved performance for both unconditional and conditional sequence-generation tasks.
Comparison of Classification Algorithms Used Medical Documents Categorization
Volume of text based documents have been increasing day by day. Medical documents are located within this growing text documents. In this study, the techniques used for text classification applied on medical documents and evaluated classification performance. Used data sets are multi class and multi labelled. Chi Square (CHI) technique was used for feature selection also SMO, NB, C4.5, RF and KNN algorithms was used for classification. The aim of this study, success of various classifiers is evaluated on multi class and multi label data sets consisting of medical documents. The first 400 features, while the most successful in the KNN classifier, feature number 400 and after the SMO has become the most successful classifier.
Probabilistic Programming with Densities in SlicStan: Efficient, Flexible and Deterministic
Stan is a probabilistic programming language that has been increasingly used for real-world scalable projects. However, to make practical inference possible, the language sacrifices some of its usability by adopting a block syntax, which lacks compositionality and flexible user-defined functions. Moreover, the semantics of the language has been mainly given in terms of intuition about implementation, and has not been formalised. This paper provides a formal treatment of the Stan language, and introduces the probabilistic programming language SlicStan — a compositional, self-optimising version of Stan. Our main contributions are: (1) the formalisation of a core subset of Stan through an operational density-based semantics; (2) the design and semantics of the Stan-like language SlicStan, which facilities better code reuse and abstraction through its compositional syntax, more flexible functions, and information-flow type system; and (3) a formal, semantic-preserving procedure for translating SlicStan to Stan.
Spectral Methods from Tensor Networks
A tensor network is a diagram that specifies a way to ‘multiply’ a collection of tensors together to produce another tensor (or matrix). Many existing algorithms for tensor problems (such as tensor decomposition and tensor PCA), although they are not presented this way, can be viewed as spectral methods on matrices built from simple tensor networks. In this work we leverage the full power of this abstraction to design new algorithms for certain continuous tensor decomposition problems. An important and challenging family of tensor problems comes from orbit recovery, a class of inference problems involving group actions (inspired by applications such as cryo-electron microscopy). Orbit recovery problems over finite groups can often be solved via standard tensor methods. However, for infinite groups, no general algorithms are known. We give a new spectral algorithm based on tensor networks for one such problem: continuous multi-reference alignment over the infinite group SO(2). Our algorithm extends to the more general heterogeneous case.
A Fast Algorithm for Clustering High Dimensional Feature Vectors



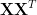

Anomaly Detection for imbalanced datasets with Deep Generative Models
Many important data analysis applications present with severely imbalanced datasets with respect to the target variable. A typical example is medical image analysis, where positive samples are scarce, while performance is commonly estimated against the correct detection of these positive examples. We approach this challenge by formulating the problem as anomaly detection with generative models. We train a generative model without supervision on the negative’ (common) datapoints and use this model to estimate the likelihood of unseen data. A successful model allows us to detect the positive’ case as low likelihood datapoints. In this position paper, we present the use of state-of-the-art deep generative models (GAN and VAE) for the estimation of a likelihood of the data. Our results show that on the one hand both GANs and VAEs are able to separate the positive’ and negative’ samples in the MNIST case. On the other hand, for the NLST case, neither GANs nor VAEs were able to capture the complexity of the data and discriminate anomalies at the level that this task requires. These results show that even though there are a number of successes presented in the literature for using generative models in similar applications, there remain further challenges for broad successful implementation.
CMI: An Online Multi-objective Genetic Autoscaler for Scientific and Engineering Workflows in Cloud Infrastructures with Unreliable Virtual Machines
Cloud Computing is becoming the leading paradigm for executing scientific and engineering workflows. The large-scale nature of the experiments they model and their variable workloads make clouds the ideal execution environment due to prompt and elastic access to huge amounts of computing resources. Autoscalers are middleware-level software components that allow scaling up and down the computing platform by acquiring or terminating virtual machines (VM) at the time that workflow’s tasks are being scheduled. In this work we propose a novel online multi-objective autoscaler for workflows denominated Cloud Multi-objective Intelligence (CMI), that aims at the minimization of makespan, monetary cost and the potential impact of errors derived from unreliable VMs. In addition, this problem is subject to monetary budget constraints. CMI is responsible for periodically solving the autoscaling problems encountered along the execution of a workflow. Simulation experiments on four well-known workflows exhibit that CMI significantly outperforms a state-of-the-art autoscaler of similar characteristics called Spot Instances Aware Autoscaling (SIAA). These results convey a solid base for deepening in the study of other meta-heuristic methods for autoscaling workflow applications using cheap but unreliable infrastructures.
Invertible Residual Networks
Reversible deep networks provide useful theoretical guarantees and have proven to be a powerful class of functions in many applications. Usually, they rely on analytical inverses using dimension splitting, fundamentally constraining their structure compared to common architectures. Based on recent links between ordinary differential equations and deep networks, we provide a sufficient condition when standard ResNets are invertible. This condition allows unconstrained architectures for residual blocks, while only requiring an adaption to their regularization scheme. We numerically compute their inverse, which has O(1) memory cost and computational cost of 5-20 forward passes. Finally, we show that invertible ResNets perform on par with standard ResNets on classifying MNIST and CIFAR10 images.
Analysing Dropout and Compounding Errors in Neural Language Models
This paper carries out an empirical analysis of various dropout techniques for language modelling, such as Bernoulli dropout, Gaussian dropout, Curriculum Dropout, Variational Dropout and Concrete Dropout. Moreover, we propose an extension of variational dropout to concrete dropout and curriculum dropout with varying schedules. We find these extensions to perform well when compared to standard dropout approaches, particularly variational curriculum dropout with a linear schedule. Largest performance increases are made when applying dropout on the decoder layer. Lastly, we analyze where most of the errors occur at test time as a post-analysis step to determine if the well-known problem of compounding errors is apparent and to what end do the proposed methods mitigate this issue for each dataset. We report results on a 2-hidden layer LSTM, GRU and Highway network with embedding dropout, dropout on the gated hidden layers and the output projection layer for each model. We report our results on Penn-TreeBank and WikiText-2 word-level language modelling datasets, where the former reduces the long-tail distribution through preprocessing and one which preserves rare words in the training and test set.
Unsupervised Learning of Interpretable Dialog Models
Recently several deep learning based models have been proposed for end-to-end learning of dialogs. While these models can be trained from data without the need for any additional annotations, it is hard to interpret them. On the other hand, there exist traditional state based dialog systems, where the states of the dialog are discrete and hence easy to interpret. However these states need to be handcrafted and annotated in the data. To achieve the best of both worlds, we propose Latent State Tracking Network (LSTN) using which we learn an interpretable model in unsupervised manner. The model defines a discrete latent variable at each turn of the conversation which can take a finite set of values. Since these discrete variables are not present in the training data, we use EM algorithm to train our model in unsupervised manner. In the experiments, we show that LSTN can help achieve interpretability in dialog models without much decrease in performance compared to end-to-end approaches.
• Principled Design and Implementation of Steerable Detectors• Quantum Structures in Human Decision-making: Towards Quantum Expected Utility• Deep Segment Attentive Embedding for Duration Robust Speaker Verification• Learning to decompose the modes in few-mode fibers with deep convolutional neural network• Online Diverse Learning to Rank from Partial-Click Feedback• Enhancing the Structural Performance of Additively Manufactured Objects• Improving Information Retrieval Results for Persian Documents using FarsNet• Multiple-Attribute Text Style Transfer• Near or Far, Wide Range Zero-Shot Cross-Lingual Dependency Parsing• Matrix Completion with Side Information using Manifold Optimization• Tropical Modeling of Weighted Transducer Algorithms on Graphs• How the fundamental concepts of mathematics and physics explain deep learning• Functional Nonlinear Sparse Models• Abelian groups are polynomially stable• A Stronger Baseline for Multilingual Word Embeddings• Modeling tropotaxis in ant colonies: recruitment and trail formation• Defining a Metric Space of Host Logs and Operational Use Cases• Power System Transient Stability Analysis Using Truncated Taylor Expansion Systems• Dynamics of drainage under stochastic rainfall in river networks• Variational Dropout via Empirical Bayes• Capsule Networks for Brain Tumor Classification based on MRI Images and Course Tumor Boundaries• DeepTileBars: Visualizing Term Distribution for Neural Information Retrieval• Exploring the Equivalence between Dynamic Dataflow Model and Gamma – General Abstract Model for Multiset mAnipulation• Shifting the Baseline: Single Modality Performance on Visual Navigation & QA• Exploring Semantic Incrementality with Dynamic Syntax and Vector Space Semantics• An $O(n \log n)$ time Algorithm for computing the Path-length Distance between Trees• Efficient Online Hyperparameter Optimization for Kernel Ridge Regression with Applications to Traffic Time Series Prediction• Improving Adversarial Robustness by Encouraging Discriminative Features• Packing a fixed number of identical circles in a circular container with circular prohibited areas• Incorporating Structured Commonsense Knowledge in Story Completion• Action convergence of operators and graphs• The contact process with avoidance• Independent Vector Analysis for Data Fusion Prior to Molecular Property Prediction with Machine Learning• Embedding Individual Table Columns for Resilient SQL Chatbots• Spectral Signatures in Backdoor Attacks• Simple Sensitivity Analysis for Differential Measurement Error• Stochastic Normalizations as Bayesian Learning• A Multidimensional Fatou Lemma for Conditional Expectations• Online Embedding Compression for Text Classification using Low Rank Matrix Factorization• An Approximation Algorithm for Active Friending in Online Social Networks• Analyzing and learning the language for different types of harassment• The Holdout Randomization Test: Principled and Easy Black Box Feature Selection• Prediction Error Meta Classification in Semantic Segmentation: Detection via Aggregated Dispersion Measures of Softmax Probabilities• On total regularity of mixed graphs with order close to the Moore bound• Exposing DeepFake Videos By Detecting Face Warping Artifacts• Non-monotone Behavior of the Heavy Ball Method• Implicit Regularization of Stochastic Gradient Descent in Natural Language Processing: Observations and Implications• Exposing Deep Fakes Using Inconsistent Head Poses• Introduction to the 1st Place Winning Model of OpenImages Relationship Detection Challenge• Identification and Estimation of Group-Level Partial Effects• Analyzing different prototype selection techniques for dynamic classifier and ensemble selection• On the Generation of Medical Question-Answer Pairs• Quasi-random number generators for multivariate distributions based on generative neural networks• SDCNet: Video Prediction Using Spatially-Displaced Convolution• Closed Form Variational Objectives For Bayesian Neural Networks with a Single Hidden Layer• Asynchronous Neighbor Discovery Using Coupled Compressive Sensing• Data-driven Perception of Neuron Point Process with Unknown Unknowns• Resilient Consensus Through Asynchronous Event-based Communication• Zero-Shot Transfer VQA Dataset• Meta-path Augmented Response Generation• Design Verifiably Correct Model Patterns to Facilitate Modeling Medical Best Practice Guidelines with Statecharts (Technical Report)• Non linear optimal stopping problem and Reflected BSDEs in the predictable setting• Noise Contrastive Estimation for Scalable Linear Models for One-Class Collaborative Filtering• Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification• Learning Latent Fractional dynamics with Unknown Unknowns• Combining Similarity Features and Deep Representation Learning for Stance Detection in the Context of Checking Fake News• Training Neural Speech Recognition Systems with Synthetic Speech Augmentation• On subexponential running times for approximating directed Steiner tree and related problems• Dirichlet belief networks for topic structure learning• Quantitative bounds in the inverse theorem for the Gowers $U^{s+1}$-norms over cyclic groups• Semantically-Aligned Equation Generation for Solving and Reasoning Math Word Problems• Adaptive MCMC for Generalized Method of Moments with Many Moment Conditions• Bayesian Hierarchical Modeling on Covariance Valued Data• Inverse optimization for the recovery of constraint parameters• Improving the Robustness of Speech Translation• Learning Based Control Policy and Regret Analysis for Online Quadratic Optimization with Asymmetric Information Structure• The age of secrecy and unfairness in recidivism prediction• Cooperative Spectrum Sharing Between D2D Users and Edge-Users: A Matching Theory Perspective• WheelCon: A wheel control-based gaming platform for studying human sensorimotor control• An Empirical Exploration of Curriculum Learning for Neural Machine Translation• Efficient Metropolitan Traffic Prediction Based on Graph Recurrent Neural Network• Stronger Data Poisoning Attacks Break Data Sanitization Defenses• Rationality-proof consensus: extended abstract• Unique Identification of Macaques for Population Monitoring and Control• Confiding in and Listening to Virtual Agents: The Effect of Personality• Information Geometry of Sensor Configuration• Effective Learning of Probabilistic Models for Clinical Predictions from Longitudinal Data• Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition• Risk-Stratify: Confident Stratification Of Patients Based On Risk• A General Framework for Multi-fidelity Bayesian Optimization with Gaussian Processes• A chemical language based approach for protein – ligand interaction prediction• Tight Approximation Ratio of Anonymous Pricing• Ranking Based Linear Constraint Handling Method with Adaptive Penalty• A Survey on Natural Language Processing for Fake News Detection• The AlexNet Moment for Homomorphic Encryption: HCNN, the First Homomorphic CNN on Encrypted Data with GPUs• Bayesian Ensembles of Crowds and Deep Learners for Sequence Tagging• Non-Asymptotic Guarantees For Sampling by Stochastic Gradient Descent• The Multiplicative Mixed Model with the mumm R package as a General and Easy Random Interaction Model Tool• Abstractive Summarization of Reddit Posts with Multi-level Memory Networks• Deep Optimisation: Solving Combinatorial Optimisation Problems using Deep Neural Networks• Drawing Clustered Graphs on Disk Arrangements• Adversarial Training of End-to-end Speech Recognition Using a Criticizing Language Model• Dealing with Ambiguity in Robotic Grasping via Multiple Predictions• Automated Theorem Proving in Intuitionistic Propositional Logic by Deep Reinforcement Learning• eLIAN: Enhanced Algorithm for Angle-constrained Path Finding• Topological effects of a vorticity filament on the coherent backscattering cone• Infinitely-many Primes in $\mathbb{N}$: A Graph Theoretic Approach• Power Control for D2D Underlay in Multi-cell Massive MIMO Networks• Planar Graphs of Bounded Degree have Constant Queue Number• Holant clones and the approximability of conservative holant problems• Multilayer Graph Signal Clustering• Generating Hard Instances for Robust Combinatorial Optimization• Time since maximum of Brownian motion and asymmetric Levy processes• Worst-Case Efficient Sorting with QuickMergesort• Arbitrary Pattern Formation on Infinite Grid by Asynchronous Oblivious Robots• An L1 Representer Theorem for Multiple-Kernel Regression• ATP: Directed Graph Embedding with Asymmetric Transitivity Preservation• The multicolour size-Ramsey number of powers of paths• Combining Long Short Term Memory and Convolutional Neural Network for Cross-Sentence n-ary Relation Extraction• Heterogeneity Aware Deep Embedding for Mobile Periocular Recognition• Algorithms for screening of Cervical Cancer: A chronological review• Normally ordered forms of powers of differential operators and their combinatorics• Efficient Neural Network Robustness Certification with General Activation Functions• Classification of Findings with Localized Lesions in Fundoscopic Images using a Regionally Guided CNN• CHIRRUP: a practical algorithm for unsourced multiple access• Competitively Chasing Convex Bodies• Distributed Automatic Load-Frequency Control with Optimality in Power Systems• Efficient Generation of Parallel Spin-images Using Dynamic Loop Scheduling• Importance of a Search Strategy in Neural Dialogue Modelling• Frequentist uncertainty estimates for deep learning• Two-Layered Superposition of Broadcast/Multicast and Unicast Signals in Multiuser OFDMA Systems• Convolutional Neural Networks for Epileptic Seizure Prediction• Foundations of Comparison-Based Hierarchical Clustering• Nonparametric identification in the dynamic stochastic block model• CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge• Progress and Tradeoffs in Neural Language Models• Lecture Notes on Optimal Power Flow (OPF)• Engaging Image Chat: Modeling Personality in Grounded Dialogue• Near-Linear Time Algorithm for n-fold ILPs via Color Coding• A martingale concept for non-monotone information in a jump process framework• Local search breaks 1.75 for Graph Balancing• Dantzig Selector with an Approximately Optimal Denoising Matrix and its Application to Reinforcement Learning• Improving the Coverage and the Generalization Ability of Neural Word Sense Disambiguation through Hypernymy and Hyponymy Relationships• Discovering conservation laws from data for control• Brawn and Brains: a Robust and Powerful approach to X-inclusive Whole-genome Association Studies• Neural Response Ranking for Social Conversation: A Data-Efficient Approach• Algebraic approach to promise constraint satisfaction• One-Bit OFDM Receivers via Deep Learning• Clustering and Learning from Imbalanced Data• Neural Likelihoods via Cumulative Distribution Functions• Proximal Gradient Method for Manifold Optimization• The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale• Satisfiability Thresholds for Regular Occupation Problems• Distribution of complex algebraic numbers on the unit circle• Chasing Nested Convex Bodies Nearly Optimally• On Evaluating the Generalization of LSTM Models in Formal Languages• Simple Attention-Based Representation Learning for Ranking Short Social Media Posts
Like this:
Like Loading…
Related