Interventional Robustness of Deep Latent Variable Models
The ability to learn disentangled representations that split underlying sources of variation in high dimensional, unstructured data is of central importance for data efficient and robust use of neural networks. Various approaches aiming towards this goal have been proposed in the recent time — validating existing work is hence a crucial task to guide further development. Previous validation methods focused on shared information between generative factors and learned features. The effects of rare events or cumulative influences from multiple factors on encodings, however, remain uncaptured. Our experiments show that this already becomes noticeable in a simple, noise free dataset. This is why we introduce the interventional robustness score, which provides a quantitative evaluation of robustness in learned representations with respect to interventions on generative factors and changing nuisance factors. We show how this score can be estimated from labeled observational data, that may be confounded, and further provide an efficient algorithm that scales linearly in the dataset size. The benefits of our causally motivated framework are illustrated in extensive experiments.
Some New Layer Architectures for Graph CNN
While convolutional neural networks (CNNs) have recently made great strides in supervised classification of data structured on a grid (e.g. images composed of pixel grids), in several interesting datasets, the relations between features can be better represented as a general graph instead of a regular grid. Although recent algorithms that adapt CNNs to graphs have shown promising results, they mostly neglect learning explicit operations for edge features while focusing on vertex features alone. We propose new formulations for convolutional, pooling, and fully connected layers for neural networks that make more comprehensive use of the information available in multi-dimensional graphs. Using these layers led to an improvement in classification accuracy over the state-of-the-art methods on benchmark graph datasets.
A Mixture of Expert Approach for Low-Cost Customization of Deep Neural Networks
The ability to customize a trained Deep Neural Network (DNN) locally using user-specific data may greatly enhance user experiences, reduce development costs, and protect user’s privacy. In this work, we propose to incorporate a novel Mixture of Experts (MOE) approach to accomplish this goal. This architecture comprises of a Global Expert (GE), a Local Expert (LE) and a Gating Network (GN). The GE is a trained DNN developed on a large training dataset representative of many potential users. After deployment on an embedded edge device, GE will be subject to customized, user-specific data (e.g., accent in speech) and its performance may suffer. This problem may be alleviated by training a local DNN (the local expert, LE) on a small size customized training data to correct the errors made by GE. A gating network then will be trained to determine whether an incoming data should be handled by GE or LE. Since the customized dataset is in general very small, the cost of training LE and GN would be much lower than that of re-training of GE. The training of LE and GN thus can be performed at local device, properly protecting the privacy of customized training data. In this work, we developed a prototype MOE architecture for handwritten alphanumeric character recognition task. We use EMNIST as the generic dataset, LeNet5 as GE, and handwritings of 10 users as the customized dataset. We show that with the LE and GN, the classification accuracy is significantly enhanced over the customized dataset with almost no degradation of accuracy over the generic dataset. In terms of energy and network size, the overhead of LE and GN is around 2.5% compared to those of GE.
An Interdisciplinary Comparison of Sequence Modeling Methods for Next-Element Prediction
Data of sequential nature arise in many application domains in forms of, e.g. textual data, DNA sequences, and software execution traces. Different research disciplines have developed methods to learn sequence models from such datasets: (i) in the machine learning field methods such as (hidden) Markov models and recurrent neural networks have been developed and successfully applied to a wide-range of tasks, (ii) in process mining process discovery techniques aim to generate human-interpretable descriptive models, and (iii) in the grammar inference field the focus is on finding descriptive models in the form of formal grammars. Despite their different focuses, these fields share a common goal – learning a model that accurately describes the behavior in the underlying data. Those sequence models are generative, i.e, they can predict what elements are likely to occur after a given unfinished sequence. So far, these fields have developed mainly in isolation from each other and no comparison exists. This paper presents an interdisciplinary experimental evaluation that compares sequence modeling techniques on the task of next-element prediction on four real-life sequence datasets. The results indicate that machine learning techniques that generally have no aim at interpretability in terms of accuracy outperform techniques from the process mining and grammar inference fields that aim to yield interpretable models.
The UEA multivariate time series classification archive, 2018
Predictive Modeling of Biomedical Signals Using Controlled Spatial Transformation
An important paradigm in smart health is developing diagnosis tools and monitoring a patient’s heart activity through processing Electrocardiogram (ECG) signals is a key example, sue to high mortality rate of heart-related disease. However, current heart monitoring devices suffer from two important drawbacks: i) failure in capturing inter-patient variability, and ii) incapability of identifying heart abnormalities ahead of time to take effective preventive and therapeutic interventions. This paper proposed a novel predictive signal processing method to solve these issues. We propose a two-step classification framework for ECG signals, where a global classifier recognizes severe abnormalities by comparing the signal against a universal reference model. The seemingly normal signals are then passed through a personalized classifier, to recognize mild but informative signal morphology distortions. The key idea is to develop a novel deviation analysis based on a controlled nonlinear transformation to capture significant deviations of the signal towards any of predefined abnormality classes. Here, we embrace the proven but overlooked fact that certain features of ECG signals reflect underlying cardiac abnormalities before the occurrences of cardiac disease. The proposed method achieves a classification accuracy of 96.6% and provides a unique feature of predictive analysis by providing warnings before critical heart conditions. In particular, the chance of observing a severe problem (a red alarm) is raised by about 5% to 10% after observing a yellow alarm of the same type. Although we used this methodology to provide early precaution messages to elderly and high-risk heart-patients, the proposed method is general and applicable to similar bio-medical signal processing applications.
SDRL: Interpretable and Data-efficient Deep Reinforcement LearningLeveraging Symbolic Planning
Deep reinforcement learning (DRL) has gained great success by learning directly from high-dimensional sensory inputs, yet is notorious for the lack of interpretability. Interpretability of the subtasks is critical in hierarchical decision-making as it increases the transparency of black-box-style DRL approach and helps the RL practitioners to understand the high-level behavior of the system better. In this paper, we introduce symbolic planning into DRL and propose a framework of Symbolic Deep Reinforcement Learning (SDRL) that can handle both high-dimensional sensory inputs and symbolic planning. The task-level interpretability is enabled by relating symbolic actions to options.This framework features a planner — controller — meta-controller architecture, which takes charge of subtask scheduling, data-driven subtask learning, and subtask evaluation, respectively. The three components cross-fertilize each other and eventually converge to an optimal symbolic plan along with the learned subtasks, bringing together the advantages of long-term planning capability with symbolic knowledge and end-to-end reinforcement learning directly from a high-dimensional sensory input. Experimental results validate the interpretability of subtasks, along with improved data efficiency compared with state-of-the-art approaches.
An Evolutionary Algorithm with Crossover and Mutation for Model-Based Clustering
The expectation-maximization (EM) algorithm is almost ubiquitous for parameter estimation in model-based clustering problems; however, it can become stuck at local maxima, due to its single path, monotonic nature. Rather than using an EM algorithm, an evolutionary algorithm (EA) is developed. This EA facilitates a different search of the fitness landscape, i.e., the likelihood surface, utilizing both crossover and mutation. Furthermore, this EA represents an efficient approach to ‘hard’ model-based clustering and so it can be viewed as a sort of generalization of the k-means algorithm, which is itself equivalent to a classification EM algorithm for a Gaussian mixture model with spherical component covariances. The EA is illustrated on several data sets, and its performance is compared to k-means clustering as well as model-based clustering with an EM algorithm.
On the True Number of Clusters in a Dataset
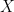
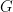
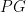
The Price of Fair PCA: One Extra Dimension
We investigate whether the standard dimensionality reduction technique of PCA inadvertently produces data representations with different fidelity for two different populations. We show on several real-world data sets, PCA has higher reconstruction error on population A than on B (for example, women versus men or lower- versus higher-educated individuals). This can happen even when the data set has a similar number of samples from A and B. This motivates our study of dimensionality reduction techniques which maintain similar fidelity for A and B. We define the notion of Fair PCA and give a polynomial-time algorithm for finding a low dimensional representation of the data which is nearly-optimal with respect to this measure. Finally, we show on real-world data sets that our algorithm can be used to efficiently generate a fair low dimensional representation of the data.
Dimensionality Reduction has Quantifiable Imperfections: Two Geometric Bounds
A Mixture Model Based Defense for Data Poisoning Attacks Against Naive Bayes Spam Filters
Naive Bayes spam filters are highly susceptible to data poisoning attacks. Here, known spam sources/blacklisted IPs exploit the fact that their received emails will be treated as (ground truth) labeled spam examples, and used for classifier training (or re-training). The attacking source thus generates emails that will skew the spam model, potentially resulting in great degradation in classifier accuracy. Such attacks are successful mainly because of the poor representation power of the naive Bayes (NB) model, with only a single (component) density to represent spam (plus a possible attack). We propose a defense based on the use of a mixture of NB models. We demonstrate that the learned mixture almost completely isolates the attack in a second NB component, with the original spam component essentially unchanged by the attack. Our approach addresses both the scenario where the classifier is being re-trained in light of new data and, significantly, the more challenging scenario where the attack is embedded in the original spam training set. Even for weak attack strengths, BIC-based model order selection chooses a two-component solution, which invokes the mixture-based defense. Promising results are presented on the TREC 2005 spam corpus.
Towards a Simple Approach to Multi-step Model-based Reinforcement Learning
When environmental interaction is expensive, model-based reinforcement learning offers a solution by planning ahead and avoiding costly mistakes. Model-based agents typically learn a single-step transition model. In this paper, we propose a multi-step model that predicts the outcome of an action sequence with variable length. We show that this model is easy to learn, and that the model can make policy-conditional predictions. We report preliminary results that show a clear advantage for the multi-step model compared to its one-step counterpart.
Democratizing Production-Scale Distributed Deep Learning
The interest and demand for training deep neural networks have been experiencing rapid growth, spanning a wide range of applications in both academia and industry. However, training them distributed and at scale remains difficult due to the complex ecosystem of tools and hardware involved. One consequence is that the responsibility of orchestrating these complex components is often left to one-off scripts and glue code customized for specific problems. To address these restrictions, we introduce \emph{Alchemist} – an internal service built at Apple from the ground up for \emph{easy}, \emph{fast}, and \emph{scalable} distributed training. We discuss its design, implementation, and examples of running different flavors of distributed training. We also present case studies of its internal adoption in the development of autonomous systems, where training times have been reduced by 10x to keep up with the ever-growing data collection.
ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning
We present ATOMIC, an atlas of everyday commonsense reasoning, organized through 300k textual descriptions. Compared to existing resources that center around taxonomic knowledge, ATOMIC focuses on inferential knowledge organized as typed if-then relations with variables (e.g., ‘if X pays Y a compliment, then Y will likely return the compliment’). We propose nine if-then relation types to distinguish causes v.s. effects, agents v.s. themes, voluntary v.s. involuntary events, and actions v.s. mental states. By generatively training on the rich inferential knowledge described in ATOMIC, we show that neural models can acquire simple commonsense capabilities and reason about previously unseen events. Experimental results demonstrate that multitask models that incorporate the hierarchical structure of if-then relation types lead to more accurate inference compared to models trained in isolation, as measured by both automatic and human evaluation.
DOLORES: Deep Contextualized Knowledge Graph Embeddings
We introduce a new method DOLORES for learning knowledge graph embeddings that effectively captures contextual cues and dependencies among entities and relations. First, we note that short paths on knowledge graphs comprising of chains of entities and relations can encode valuable information regarding their contextual usage. We operationalize this notion by representing knowledge graphs not as a collection of triples but as a collection of entity-relation chains, and learn embeddings for entities and relations using deep neural models that capture such contextual usage. In particular, our model is based on Bi-Directional LSTMs and learn deep representations of entities and relations from constructed entity-relation chains. We show that these representations can very easily be incorporated into existing models to significantly advance the state of the art on several knowledge graph prediction tasks like link prediction, triple classification, and missing relation type prediction (in some cases by at least 9.5%).
Mixture Density Generative Adversarial Networks
Generative Adversarial Networks have surprising ability for generating sharp and realistic images, though they are known to suffer from the so-called mode collapse problem. In this paper, we propose a new GAN variant called Mixture Density GAN that while being capable of generating high-quality images, overcomes this problem by encouraging the Discriminator to form clusters in its embedding space, which in turn leads the Generator to exploit these and discover different modes in the data. This is achieved by positioning Gaussian density functions in the corners of a simplex, using the resulting Gaussian mixture as a likelihood function over discriminator embeddings, and formulating an objective function for GAN training that is based on these likelihoods. We show that the optimum of our training objective is attained if and only if the generated and the real distribution match exactly. We further support our theoretical results with empirical evaluations on one synthetic and several real image datasets (CIFAR-10, CelebA, MNIST, and FashionMNIST). We demonstrate empirically (1) the quality of the generated images in Mixture Density GAN and their strong similarity to real images, as measured by the Fr\’echet Inception Distance (FID), which compares very favourably with state-of-the-art methods, and (2) the ability to avoid mode collapse and discover all data modes.
OpenCL Performance Prediction using Architecture-Independent Features
OpenCL is an attractive model for heterogeneous high-performance computing systems, with wide support from hardware vendors and significant performance portability. To support efficient scheduling on HPC systems it is necessary to perform accurate performance predictions for OpenCL workloads on varied compute devices, which is challeng- ing due to diverse computation, communication and memory access characteristics which result in varying performance between devices. The Architecture Independent Workload Characterization (AIWC) tool can be used to characterize OpenCL kernels according to a set of architecture-independent features. This work presents a methodology where AIWC features are used to form a model capable of predicting accelerator execution times. We used this methodology to predict execution times for a set of 37 computational kernels running on 15 different devices representing a broad range of CPU, GPU and MIC architectures. The predictions are highly accurate, differing from the measured experimental run-times by an average of only 1.2%, and correspond to actual execution time mispredictions of 9 {\mu}s to 1 sec according to problem size. A previously unencountered code can be instrumented once and the AIWC metrics embedded in the kernel, to allow performance prediction across the full range of modelled devices. The results suggest that this methodology supports correct selection of the most appropriate device for a previously unencountered code, which is highly relevant to the HPC scheduling setting.
Clustered Monotone Transforms for Rating Factorization
Exploiting low-rank structure of the user-item rating matrix has been the crux of many recommendation engines. However, existing recommendation engines force raters with heterogeneous behavior profiles to map their intrinsic rating scales to a common rating scale (e.g. 1-5). This non-linear transformation of the rating scale shatters the low-rank structure of the rating matrix, therefore resulting in a poor fit and consequentially, poor recommendations. In this paper, we propose Clustered Monotone Transforms for Rating Factorization (CMTRF), a novel approach to perform regression up to unknown monotonic transforms over unknown population segments. Essentially, for recommendation systems, the technique searches for monotonic transformations of the rating scales resulting in a better fit. This is combined with an underlying matrix factorization regression model that couples the user-wise ratings to exploit shared low dimensional structure. The rating scale transformations can be generated for each user, for a cluster of users, or for all the users at once, forming the basis of three simple and efficient algorithms proposed in this paper, all of which alternate between transformation of the rating scales and matrix factorization regression. Despite the non-convexity, CMTRF is theoretically shown to recover a unique solution under mild conditions. Experimental results on two synthetic and seven real-world datasets show that CMTRF outperforms other state-of-the-art baselines.
Conceptual Content in Deep Convolutional Neural Networks: An analysis into multi-faceted properties of neurons
In this paper we analyze convolutional layers of VGG16 model pre-trained on ILSVRC2012. We based our analysis on the responses of neurons to the images of all classes in ImageNet database. In our analysis, we first propose a visualization method to illustrate the learned content of each neuron. Next, we investigate single and multi-faceted neurons based on the diversity of neurons responses to different classes. Finally, we compute the neuronal similarity at each layer and make a comparison between them. Our results demonstrate that the neurons in lower layers exhibit a multi-faceted behavior, whereas the majority of neurons in higher layers comprise single-faceted property and tend to respond to a smaller number of classes.
Deep Counterfactual Regret Minimization
Counterfactual Regret Minimization (CFR) is the leading algorithm for solving large imperfect-information games. It iteratively traverses the game tree in order to converge to a Nash equilibrium. In order to deal with extremely large games, CFR typically uses domain-specific heuristics to simplify the target game in a process known as abstraction. This simplified game is solved with tabular CFR, and its solution is mapped back to the full game. This paper introduces Deep Counterfactual Regret Minimization (Deep CFR), a form of CFR that obviates the need for abstraction by instead using deep neural networks to approximate the behavior of CFR in the full game. We show that Deep CFR is principled and achieves strong performance in the benchmark game of heads-up no-limit Texas hold’em poker. This is the first successful use of function approximation in CFR for large games.
PerceptionNet: A Deep Convolutional Neural Network for Late Sensor Fusion
Human Activity Recognition (HAR) based on motion sensors has drawn a lot of attention over the last few years, since perceiving the human status enables context-aware applications to adapt their services on users’ needs. However, motion sensor fusion and feature extraction have not reached their full potentials, remaining still an open issue. In this paper, we introduce PerceptionNet, a deep Convolutional Neural Network (CNN) that applies a late 2D convolution to multimodal time-series sensor data, in order to extract automatically efficient features for HAR. We evaluate our approach on two public available HAR datasets to demonstrate that the proposed model fuses effectively multimodal sensors and improves the performance of HAR. In particular, PerceptionNet surpasses the performance of state-of-the-art HAR methods based on: (i) features extracted from humans, (ii) deep CNNs exploiting early fusion approaches, and (iii) Long Short-Term Memory (LSTM), by an average accuracy of more than 3%.
Dial2Desc: End-to-end Dialogue Description Generation
We first propose a new task named Dialogue Description (Dial2Desc). Unlike other existing dialogue summarization tasks such as meeting summarization, we do not maintain the natural flow of a conversation but describe an object or an action of what people are talking about. The Dial2Desc system takes a dialogue text as input, then outputs a concise description of the object or the action involved in this conversation. After reading this short description, one can quickly extract the main topic of a conversation and build a clear picture in his mind, without reading or listening to the whole conversation. Based on the existing dialogue dataset, we build a new dataset, which has more than one hundred thousand dialogue-description pairs. As a step forward, we demonstrate that one can get more accurate and descriptive results using a new neural attentive model that exploits the interaction between utterances from different speakers, compared with other baselines.
Towards Explainable NLP: A Generative Explanation Framework for Text Classification
Building explainable systems is a critical problem in the field of Natural Language Processing (NLP), since most machine learning models provide no explanations for the predictions. Existing approaches for explainable machine learning systems tend to focus on interpreting the outputs or the connections between inputs and outputs. However, the fine-grained information is often ignored, and the systems do not explicitly generate the human-readable explanations. To better alleviate this problem, we propose a novel generative explanation framework that learns to make classification decisions and generate fine-grained explanations at the same time. More specifically, we introduce the explainable factor and the minimum risk training approach that learn to generate more reasonable explanations. We construct two new datasets that contain summaries, rating scores, and fine-grained reasons. We conduct experiments on both datasets, comparing with several strong neural network baseline systems. Experimental results show that our method surpasses all baselines on both datasets, and is able to generate concise explanations at the same time.
MOHONE: Modeling Higher Order Network Effects in KnowledgeGraphs via Network Infused Embeddings
Many knowledge graph embedding methods operate on triples and are therefore implicitly limited by a very local view of the entire knowledge graph. We present a new framework MOHONE to effectively model higher order network effects in knowledge-graphs, thus enabling one to capture varying degrees of network connectivity (from the local to the global). Our framework is generic, explicitly models the network scale, and captures two different aspects of similarity in networks: (a) shared local neighborhood and (b) structural role-based similarity. First, we introduce methods that learn network representations of entities in the knowledge graph capturing these varied aspects of similarity. We then propose a fast, efficient method to incorporate the information captured by these network representations into existing knowledge graph embeddings. We show that our method consistently and significantly improves the performance on link prediction of several different knowledge-graph embedding methods including TRANSE, TRANSD, DISTMULT, and COMPLEX(by at least 4 points or 17% in some cases).
Latent Gaussian Count Time Series Modeling
This paper develops theory and methods for the copula modeling of stationary count time series. The techniques use a latent Gaussian process and a distributional transformation to construct stationary series with very flexible correlation features that can have any pre-specified marginal distribution, including the classical Poisson, generalized Poisson, negative binomial, and binomial count structures. A Gaussian pseudo-likelihood estimation paradigm, based only on the mean and autocovariance function of the count series, is developed via some new Hermite expansions. Particle filtering methods are studied to approximate the true likelihood of the count series. Here, connections to hidden Markov models and other copula likelihood approximations are made. The efficacy of the approach is demonstrated and the methods are used to analyze a count series containing the annual number of no-hitter baseball games pitched in major league baseball since 1893.
I Know the Feeling: Learning to Converse with Empathy
Beyond understanding what is being discussed, human communication requires an awareness of what someone is feeling. One challenge for dialogue agents is being able to recognize feelings in the conversation partner and reply accordingly, a key communicative skill that is trivial for humans. Research in this area is made difficult by the paucity of large-scale publicly available datasets both for emotion and relevant dialogues. This work proposes a new task for empathetic dialogue generation and EmpatheticDialogues, a dataset of 25k conversations grounded in emotional contexts to facilitate training and evaluating dialogue systems. Our experiments indicate that models explicitly leveraging emotion predictions from previous utterances are perceived to be more empathetic by human evaluators, while improving on other metrics as well (e.g. perceived relevance of responses, BLEU scores).
Adaptive Planner Scheduling with Graph Neural Networks
Automated planning is one of the foundational areas of AI. Since a single planner unlikely works well for all tasks and domains, portfolio-based techniques become increasingly popular recently. In particular, deep learning emerges as a promising methodology for online planner selection. Owing to the recent development of structural graph representations of planning tasks, we propose a graph neural network (GNN) approach to selecting candidate planners. GNNs are advantageous over a straightforward alternative, the convolutional neural networks, in that they are invariant to node permutations and that they incorporate node labels for better inference. Additionally, for cost-optimal planning, we propose a two-stage adaptive scheduling method to further improve the likelihood that a given task is solved in time. The scheduler may switch at halftime to a different planner, conditioned on the observed performance of the first one. Experimental results validate the effectiveness of the proposed method against strong baselines, both deep learning and non-deep learning based.
Robust Markov Decision Process: Beyond Rectangularity
Markov decision processes (MDPs) are a common approach used to model dynamic optimization problems. MDPs are specified by a set of states, actions, transition probability kernel and the rewards associated with transitions. The goal is to find a policy that maximizes the expected cumulated reward. However, in most real world problems, the model parameters are estimated from noisy observations and are uncertain. The optimal policy for the nominal parameters might be highly sensitive to even small perturbations in the parameters, leading to significantly suboptimal outcomes. To address this issue, we consider a robust approach where the uncertainty in probability transitions is modeled as an adversarial selection from an uncertainty set. Most prior works consider the case where uncertainty on transitions related to different states is uncoupled. However, the case of general uncertainty sets is known to be intractable. We consider a factor model where the transition probability is a linear function of a factor matrix that is uncertain and belongs to a factor matrix uncertainty set. It allows to model dependence between probability transitions across different states and it is significantly less conservative than prior approaches. We show that under a certain assumption, we can efficiently compute an optimal robust policy under the factor matrix uncertainty model. We show that an optimal robust policy can be chosen deterministic and in particular is an optimal policy for some transition kernel in the uncertainty set. This implies strong min-max duality. We introduce the robust counterpart of important structural results of classical MDPs and we provide a computational study to demonstrate the usefulness of our approach, where we present two examples where robustness improves the worst-case and the empirical performances while maintaining a reasonable performance on the nominal parameters.
META-DES.Oracle: Meta-learning and feature selection for ensemble selection
The key issue in Dynamic Ensemble Selection (DES) is defining a suitable criterion for calculating the classifiers’ competence. There are several criteria available to measure the level of competence of base classifiers, such as local accuracy estimates and ranking. However, using only one criterion may lead to a poor estimation of the classifier’s competence. In order to deal with this issue, we have proposed a novel dynamic ensemble selection framework using meta-learning, called META-DES. An important aspect of the META-DES framework is that multiple criteria can be embedded in the system encoded as different sets of meta-features. However, some DES criteria are not suitable for every classification problem. For instance, local accuracy estimates may produce poor results when there is a high degree of overlap between the classes. Moreover, a higher classification accuracy can be obtained if the performance of the meta-classifier is optimized for the corresponding data. In this paper, we propose a novel version of the META-DES framework based on the formal definition of the Oracle, called META-DES.Oracle. The Oracle is an abstract method that represents an ideal classifier selection scheme. A meta-feature selection scheme using an overfitting cautious Binary Particle Swarm Optimization (BPSO) is proposed for improving the performance of the meta-classifier. The difference between the outputs obtained by the meta-classifier and those presented by the Oracle is minimized. Thus, the meta-classifier is expected to obtain results that are similar to the Oracle. Experiments carried out using 30 classification problems demonstrate that the optimization procedure based on the Oracle definition leads to a significant improvement in classification accuracy when compared to previous versions of the META-DES framework and other state-of-the-art DES techniques.
Textbook Question Answering with Knowledge Graph Understanding and Unsupervised Open-set Text Comprehension
In this work, we introduce a novel algorithm for solving the textbook question answering (TQA) task which describes more realistic QA problems compared to other recent tasks. We mainly focus on two related issues with analysis of TQA dataset. First, it requires to comprehend long lessons to extract knowledge. To tackle this issue of extracting knowledge features from long lessons, we establish knowledge graph from texts and incorporate graph convolutional network (GCN). Second, scientific terms are not spread over the chapters and data splits in TQA dataset. To overcome this so called `out-of-domain’ issue, we add novel unsupervised text learning process without any annotations before learning QA problems. The experimental results show that our model significantly outperforms prior state-of-the-art methods. Moreover, ablation studies validate that both methods of incorporating GCN for extracting knowledge from long lessons and our newly proposed unsupervised learning process are meaningful to solve this problem.
A Neural Network Framework for Fair Classifier
Machine learning models are extensively being used in decision making, especially for prediction tasks. These models could be biased or unfair towards a specific sensitive group either of a specific race, gender or age. Researchers have put efforts into characterizing a particular definition of fairness and enforcing them into the models. In this work, mainly we are concerned with the following three definitions, Disparate Impact, Demographic Parity and Equalized Odds. Researchers have shown that Equalized Odds cannot be satisfied in calibrated classifiers unless the classifier is perfect. Hence the primary challenge is to ensure a degree of fairness while guaranteeing as much accuracy as possible. Fairness constraints are complex and need not be convex. Incorporating them into a machine learning algorithm is a significant challenge. Hence, many researchers have tried to come up with a surrogate loss which is convex in order to build fair classifiers. Besides, certain papers try to build fair representations by preprocessing the data, irrespective of the classifier used. Such methods, not only require a lot of unrealistic assumptions but also require human engineered analytical solutions to build a machine learning model. We instead propose an automated solution which is generalizable over any fairness constraint. We use a neural network which is trained on batches and directly enforces the fairness constraint as the loss function without modifying it further. We have also experimented with other complex performance measures such as H-mean loss, Q-mean-loss, F-measure; without the need for any surrogate loss functions. Our experiments prove that the network achieves similar performance as state of the art. Thus, one can just plug-in appropriate loss function as per required fairness constraint and performance measure of the classifier and train a neural network to achieve that.
HMLasso: Lasso for High Dimensional and Highly Missing Data
Sparse regression such as Lasso has achieved great success in dealing with high dimensional data for several decades. However, there are few methods applicable to missing data, which often occurs in high dimensional data. Recently, CoCoLasso was proposed to deal with high dimensional missing data, but it still suffers from highly missing data. In this paper, we propose a novel Lasso-type regression technique for Highly Missing data, called `HMLasso’. We use the mean imputed covariance matrix, which is notorious in general due to its estimation bias for missing data. However, we effectively incorporate it into Lasso, by using a useful connection with the pairwise covariance matrix. The resulting optimization problem can be seen as a weighted modification of CoCoLasso with the missing ratios, and is quite effective for highly missing data. To the best of our knowledge, this is the first method that can efficiently deal with both high dimensional and highly missing data. We show that the proposed method is beneficial with regards to non-asymptotic properties of the covariance matrix. Numerical experiments show that the proposed method is highly advantageous in terms of estimation error and generalization error.
ATM:Adversarial-neural Topic Model
Topic models are widely used for thematic structure discovery in text. But traditional topic models often require dedicated inference procedures for specific tasks at hand. Also, they are not designed to generate word-level semantic representations. To address these limitations, we propose a topic modeling approach based on Generative Adversarial Nets (GANs), called Adversarial-neural Topic Model (ATM). The proposed ATM models topics with Dirichlet prior and employs a generator network to capture the semantic patterns among latent topics. Meanwhile, the generator could also produce word-level semantic representations. To illustrate the feasibility of porting ATM to tasks other than topic modeling, we apply ATM for open domain event extraction. Our experimental results on the two public corpora show that ATM generates more coherence topics, outperforming a number of competitive baselines. Moreover, ATM is able to extract meaningful events from news articles.
Hierarchical Long Short-Term Concurrent Memory for Human Interaction Recognition
In this paper, we aim to address the problem of human interaction recognition in videos by exploring the long-term inter-related dynamics among multiple persons. Recently, Long Short-Term Memory (LSTM) has become a popular choice to model individual dynamic for single-person action recognition due to its ability of capturing the temporal motion information in a range. However, existing RNN models focus only on capturing the dynamics of human interaction by simply combining all dynamics of individuals or modeling them as a whole. Such models neglect the inter-related dynamics of how human interactions change over time. To this end, we propose a novel Hierarchical Long Short-Term Concurrent Memory (H-LSTCM) to model the long-term inter-related dynamics among a group of persons for recognizing the human interactions. Specifically, we first feed each person’s static features into a Single-Person LSTM to learn the single-person dynamic. Subsequently, the outputs of all Single-Person LSTM units are fed into a novel Concurrent LSTM (Co-LSTM) unit, which mainly consists of multiple sub-memory units, a new cell gate and a new co-memory cell. In a Co-LSTM unit, each sub-memory unit stores individual motion information, while this Co-LSTM unit selectively integrates and stores inter-related motion information between multiple interacting persons from multiple sub-memory units via the cell gate and co-memory cell, respectively. Extensive experiments on four public datasets validate the effectiveness of the proposed H-LSTCM by comparing against baseline and state-of-the-art methods.
Efficient Multi-Domain Dictionary Learning with GANs
In this paper, we propose the multi-domain dictionary learning (MDDL) to make dictionary learning-based classification more robust to data representing in different domains. We use adversarial neural networks to generate data in different styles, and collect all the generated data into a miscellaneous dictionary. To tackle the dictionary learning with many samples, we compute the weighting matrix that compress the miscellaneous dictionary from multi-sample per class to single sample per class. We show that the time complexity solving the proposed MDDL with weighting matrix is the same as solving the dictionary with single sample per class. Moreover, since the weighting matrix could help the solver rely more on the training data, which possibly lie in the same domain with the testing data, the classification could be more accurate.
Helping each Other: A Framework for Customer-to-Customer Suggestion Mining using a Semi-supervised Deep Neural Network
Suggestion mining is increasingly becoming an important task along with sentiment analysis. In today’s cyberspace world, people not only express their sentiments and dispositions towards some entities or services, but they also spend considerable time sharing their experiences and advice to fellow customers and the product/service providers with two-fold agenda: helping fellow customers who are likely to share a similar experience, and motivating the producer to bring specific changes in their offerings which would be more appreciated by the customers. In our current work, we propose a hybrid deep learning model to identify whether a review text contains any suggestion. The model employs semi-supervised learning to leverage the useful information from the large amount of unlabeled data. We evaluate the performance of our proposed model on a benchmark customer review dataset, comprising of the reviews of Hotel and Electronics domains. Our proposed approach shows the F-scores of 65.6% and 65.5% for the Hotel and Electronics review datasets, respectively. These performances are significantly better compared to the existing state-of-the-art system.
Distributed ReliefF based Feature Selection in Spark
Feature selection (FS) is a key research area in the machine learning and data mining fields, removing irrelevant and redundant features usually helps to reduce the effort required to process a dataset while maintaining or even improving the processing algorithm’s accuracy. However, traditional algorithms designed for executing on a single machine lack scalability to deal with the increasing amount of data that has become available in the current Big Data era. ReliefF is one of the most important algorithms successfully implemented in many FS applications. In this paper, we present a completely redesigned distributed version of the popular ReliefF algorithm based on the novel Spark cluster computing model that we have called DiReliefF. Spark is increasing its popularity due to its much faster processing times compared with Hadoop’s MapReduce model implementation. The effectiveness of our proposal is tested on four publicly available datasets, all of them with a large number of instances and two of them with also a large number of features. Subsets of these datasets were also used to compare the results to a non-distributed implementation of the algorithm. The results show that the non-distributed implementation is unable to handle such large volumes of data without specialized hardware, while our design can process them in a scalable way with much better processing times and memory usage.
Exact parametric causal mediation analysis for non-rare binary outcomes with binary mediators
In this paper, we derive the exact parametric expressions of natural direct and indirect effects, on the odds-ratio scale, in settings with a binary mediator. The effect decomposition we propose does not require the outcome to be rare and generalizes the existing one, allowing for interactions between both the exposure and the mediator and confounding covariates. Further, it outlines a more interpretable relationship between the causal effects and the correspondent pathway-specific logistic regression parameters. Our findings are applied to data coming from a microfinance experiment performed in Bosnia and Herzegovina. A simulation study for a comparison with estimators relying on the rare outcome assumption is also implemented.
R friendly multi-threading in C++
Calling multi-threaded C++ code from R has its perils. Since the R interpreter is single-threaded, one must not check for user interruptions or print to the R console from multiple threads. One can, however, synchronize with R from the main thread. The R package RcppThread (current version 0.5.0) contains a header only C++ library for thread safe communication with R that exploits this fact. It includes C++ classes for threads, a thread pool, and parallel loops that routinely synchronize with R. This article explains the package’s functionality and gives examples of its usage. The the synchronization mechanism may also apply to other threading frameworks. Benchmarks suggest that, although synchronization causes overhead, the parallel abstractions of RcppThread are competitive with other popular libraries in typical scenarios encountered in statistical computing.
Profit-Maximizing A/B Tests
Marketers often use A/B testing as a tactical tool to compare marketing treatments in a test stage and then deploy the better-performing treatment to the remainder of the consumer population. While these tests have traditionally been analyzed using hypothesis testing, we re-frame such tactical tests as an explicit trade-off between the opportunity cost of the test (where some customers receive a sub-optimal treatment) and the potential losses associated with deploying a sub-optimal treatment to the remainder of the population. We derive a closed-form expression for the profit-maximizing test size and show that it is substantially smaller than that typically recommended for a hypothesis test, particularly when the response is noisy or when the total population is small. The common practice of using small holdout groups can be rationalized by asymmetric priors. The proposed test design achieves nearly the same expected regret as the flexible, yet harder-to-implement multi-armed bandit. We demonstrate the benefits of the method in three different marketing contexts — website design, display advertising and catalog tests — in which we estimate priors from past data. In all three cases, the optimal sample sizes are substantially smaller than for a traditional hypothesis test, resulting in higher profit.
Bias Reduction via End-to-End Shift Learning: Application to Citizen Science
Citizen science projects are successful at gathering rich datasets for various applications. Nevertheless, the data collected by the citizen scientists are often biased, more aligned with the citizens’ preferences rather than scientific objectives. We propose the Shift Compensation Network (SCN), an end-to-end learning scheme which learns the shift from the scientific objectives to the biased data, while compensating the shift by re-weighting the training data. Applied to bird observational data from the citizen science project \textit{eBird}, we demonstrate how SCN quantifies the data distribution shift as well as outperforms supervised learning models that do not address the data bias. Compared with other competing models in the context of covariate shift, we further demonstrate the advantage of SCN in both the effectiveness and the capability of handling massive high-dimensional data.
Unsupervised representation learning using convolutional and stacked auto-encoders: a domain and cross-domain feature space analysis
A feature learning task involves training models that are capable of inferring good representations (transformations of the original space) from input data alone. When working with limited or unlabelled data, and also when multiple visual domains are considered, methods that rely on large annotated datasets, such as Convolutional Neural Networks (CNNs), cannot be employed. In this paper we investigate different auto-encoder (AE) architectures, which require no labels, and explore training strategies to learn representations from images. The models are evaluated considering both the reconstruction error of the images and the feature spaces in terms of their discriminative power. We study the role of dense and convolutional layers on the results, as well as the depth and capacity of the networks, since those are shown to affect both the dimensionality reduction and the capability of generalising for different visual domains. Classification results with AE features were as discriminative as pre-trained CNN features. Our findings can be used as guidelines for the design of unsupervised representation learning methods within and across domains.
• Sharp estimates and homogenization of the control cost of the heat equation on large domains• Null-controllability and control cost estimates for the heat equation on unbounded and large bounded domains• Online learning using multiple times weight updating• Collaboration and followership: a stochastic model for activities in bipartite social networks• On New Approaches of Maximum Weighted Target Coverage and Sensor Connectivity: Hardness and Approximation• Out-of-time-ordered correlator in the quantum bakers map and truncated unitary matrices• WaveGlow: A Flow-based Generative Network for Speech Synthesis• Quantum-inspired classical algorithms for principal component analysis and supervised clustering• Deep Net Features for Complex Emotion Recognition• Cardinalities estimation under sliding time window by sharing HyperLogLog Counter• Reservoir computing with dipole coupled nanomagnets array• Diffusive Mobile MC for Controlled-Release Drug Delivery with Absorbing Receiver• Low-Dimensional Bottleneck Features for On-Device Continuous Speech Recognition• TF-MoDISco v0.4.4.2-alpha: Technical Note• On the gaps of the spectrum of volumes of trades• Evolution of entanglement spectra under random unitary dynamics• Generating Texts with Integer Linear Programming• DEEPGONET: Multi-label Prediction of GO Annotation for Protein from Sequence Using Cascaded Convolutional and Recurrent Network• Complex Crystals from Size-disperse Spheres• A representation of joint moments of CUE characteristic polynomials in terms of Painleve functions• Aligning Very Small Parallel Corpora Using Cross-Lingual Word Embeddings and a Monogamy Objective• On the existence and approximation of a dissipating feedback• Effective Feature Representation for Clinical Text Concept Extraction• Deep Generative Model with Beta Bernoulli Process for Modeling and Learning Confounding Factors• Efficient Collection of Connected Vehicles Data with Precision Guarantees• Large Tournament Games• Tiling-based models of perimeter and area• Massive MIMO Forward Link Analysis for Cellular Networks• On finite-time and fixed-time consensus algorithms for dynamic networks switching among disconnected digraphs• Generating Photo-Realistic Training Data to Improve Face Recognition Accuracy• Face Recognition: From Traditional to Deep Learning Methods• A task in a suit and a tie: paraphrase generation with semantic augmentation• Regularized Fourier Ptychography using an Online Plug-and-Play Algorithm• Affine Jump-Diffusions: Stochastic Stability and Limit Theorems• Compressing physical properties of atomic species for improving predictive chemistry• Neural Belief Propagation Decoding of CRC-Polar Concatenated Codes• Embedding cover-free families and cryptographical applications• Measuring Issue Ownership using Word Embeddings• Continuous-Time Inverse Quadratic Optimal Control Problem• Dirichlet Variational Autoencoder for Text Modeling• Forward transition rates• A scalable algorithm for sparse and robust portfolios• Testing Halfspaces over Rotation-Invariant Distributions• The k-core as a predictor of structural collapse in mutualistic ecosystems• Scalable End-to-End Autonomous Vehicle Testing via Rare-event Simulation• Recovery Guarantees for Quadratic Tensors with Limited Observations• A Sequential Design Approach for Calibrating a Dynamic Population Growth Model• Low-Precision Random Fourier Features for Memory-Constrained Kernel Approximation• Partial Mean Processes with Generated Regressors: Continuous Treatment Effects and Nonseparable Models• Modeling Melodic Feature Dependency with Modularized Variational Auto-Encoder• Stochastic nonlinear Schroedinger equations in the mass and energy critical cases• Stochastic Control with Affine Dynamics and Extended Quadratic Costs• Ground staff shift planning under delay uncertainty at Air France• Pixel Level Data Augmentation for Semantic Image Segmentation using Generative Adversarial Networks• An efficient, globally convergent method for optimization under uncertainty using adaptive model reduction and sparse grids• Improving Robustness of Attention Models on Graphs• Designing an Effective Metric Learning Pipeline for Speaker Diarization• Reversible Adversarial Examples• Online Learning Algorithms for Statistical Arbitrage• Cogni-Net: Cognitive Feature Learning through Deep Visual Perception• Attention-aware Generalized Mean Pooling for Image Retrieval• Balanced Sparsity for Efficient DNN Inference on GPU• Multi-Label Robust Factorization Autoencoder and its Application in Predicting Drug-Drug Interactions• Tattoo Image Search at Scale: Joint Detection and Compact Representation Learning• Unsupervised image segmentation via maximum a posteriori estimation of continuous max-flow• CariGANs: Unpaired Photo-to-Caricature Translation• Neural Music Synthesis for Flexible Timbre Control• A Two-layer Decentralized Control Architecture for DER Coordination• Understanding Learning Dynamics Of Language Models with SVCCA• Social Learning with Questions• A sequential guiding network with attention for image captioning• On the Cheeger constant for distance-regular graphs• Towards learning-to-learn• Survey on Vision-based Path Prediction• Joint Fleet Sizing and Charging System Planning for Autonomous Electric Vehicles• Spelling Error Correction Using a Nested RNN Model and Pseudo Training Data• Progressive Memory Banks for Incremental Domain Adaptation• GlobalTrait: Personality Alignment of Multilingual Word Embeddings• On the End-to-End Solution to Mandarin-English Code-switching Speech Recognition• SARN: Relational Reasoning through Sequential Attention• Hankel determinants for convolution powers of Catalan numbers• Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data• Pruning Filter via Geometric Median for Deep Convolutional Neural Networks Acceleration• Hybrid Self-Attention Network for Machine Translation• Skeleton-based Activity Recognition with Local Order Preserving Match of Linear Patches• Language-Independent Representor for Neural Machine Translation• Horizon: Facebook’s Open Source Applied Reinforcement Learning Platform• Semi-Finite Length Analysis for Information Theoretic Tasks• Multiple Kernel $k$-Means Clustering by Selecting Representative Kernels• Learning to Describe Phrases with Local and Global Contexts• Precise asymptotics: robust stochastic volatility models• Flag matroids: algebra and geometry• A Cascaded Channel-Power Allocation for D2D Underlaid Cellular Networks Using Matching Theory• Learning Unsupervised Word Mapping by Maximizing Mean Discrepancy• Towards Linear Time Neural Machine Translation with Capsule Networks• Large deviation for two-time-scale stochastic Burgers equation• Critical initialisation for deep signal propagation in noisy rectifier neural networks• Robust risk aggregation with neural networks• Periodicity induced by noise and interaction in the kinetic mean-field FitzHugh-Nagumo model• Consistent estimation of high-dimensional factor models when the factor number is over-estimated• A Boolean Functions Theoretic Approach to Quantum Hypergraph States and Entanglement• A Local Block Coordinate Descent Algorithm for the Convolutional Sparse Coding Model• Convolutional Recurrent Predictor: Implicit Representation for Multi-target Filtering and Tracking• Spatial Functional Linear Model and its Estimation Method• Liquid Time-constant Recurrent Neural Networks as Universal Approximators• Taylor-based Optimized Recursive Extended Exponential Smoothed Neural Networks Forecasting Method• The almost sure asymptotic behavior of the solution to the stochastic heat equation with Lévy noise• Asymmetric Bilateral Phase Correlation for Optical Flow Estimation in the Frequency Domain• AMPS: A Real-time Mesh Cutting Algorithm for Surgical Simulations• Applications of Deep Learning to Nuclear Fusion Research• Deep Learning Based Gait Recognition Using Smartphones in the Wild• Towards Highly Accurate and Stable Face Alignment for High-Resolution Videos• Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network• Entropy versus variance for symmetric log-concave random variables and related problems• How2: A Large-scale Dataset for Multimodal Language Understanding• Hanson-Wright inequality in Banach spaces• Latent Visual Cues for Neural Machine Translation• A new model for the two-person red-and-black game• Fourier Transform on the Homogeneous Space of 3D Positions and Orientations for Exact Solutions to Linear Parabolic and (Hypo-)Elliptic PDEs• Bi-GANs-ST for Perceptual Image Super-resolution• Addressing word-order Divergence in Multilingual Neural Machine Translation for extremely Low Resource Languages• Continuous-time Intensity Estimation Using Event Cameras• Excessive Invariance Causes Adversarial Vulnerability• Truly unsupervised acoustic word embeddings using weak top-down constraints in encoder-decoder models• DialogueRNN: An Attentive RNN for Emotion Detection in Conversations• Control Aware Radio Resource Allocation in Low Latency Wireless Control Systems• Dilated DenseNets for Relational Reasoning• Multiplicative Latent Force Models• Improving the Modularity of AUV Control Systems using Behaviour Trees• Temporal Regularization in Markov Decision Process• GA Based Q-Attack on Community Detection• Global Aerodynamic Design Optimization via Primal-Dual Aggregation Method• Unsupervised Dual-Cascade Learning with Pseudo-Feedback Distillation for Query-based Extractive Summarization• An Improved Learning Framework for Covariant Local Feature Detection• Approximating observables on eigenstates of large many-body localized systems• Beyond real space super cell approximation, corrections to the real space cluster approximation• A Polyhedral Model for Enumeration and Optimization over the Set of Circuits• CariGAN: Caricature Generation through Weakly Paired Adversarial Learning• Referenceless Performance Evaluation of Audio Source Separation using Deep Neural Networks• Higher variations for free Lévy processes• Score-Matching Representative Approach for Big Data Analysis with Generalized Linear Models• A latent topic model for mining heterogenous non-randomly missing electronic health records data• Learning Signed Determinantal Point Processes through the Principal Minor Assignment Problem• The stability of finite sets in dyadic groups• Note on dynamic programming optimization for assigning pressing tanks at wineries• Optimal 1D Trajectory Design for UAV-Enabled Multiuser Wireless Power Transfer• Class-Agnostic Counting• An empirical study of the behaviour of the sample kurtosis in samples from symmetric stable distributions• Hybrid Pruning: Thinner Sparse Networks for Fast Inference on Edge Devices• Sparse Model Identification and Learning for Ultra-high-dimensional Additive Partially Linear Models• A Corpus for Reasoning About Natural Language Grounded in Photographs• Modeling Attention Flow on Graphs• Multilingual NMT with a language-independent attention bridge• Improving CNN Training using Disentanglement for Liver Lesion Classification in CT• Navigation by Imitation in a Pedestrian-Rich Environment• Linear statistics and pushed Coulomb gas at the edge of beta random matrices: four paths to large deviations• A bird’s-eye view on coherence, and a worm’s-eye view on cohesion• Learning Beam Search Policies via Imitation Learning• The Natural Auditor: How To Tell If Someone Used Your Words To Train Their Model• Conformal invariance of CLE$_κ$ on the Riemann sphere for $κ \in (4,8)$• Bessel SPDEs and renormalized local times• Minimizing Close-k Aggregate Loss Improves Classification• Linear Quadratic Mean Field Games — Part I: The Asymptotic Solvability Problem• On the Geometry of Adversarial Examples• The Effect of Diversity Combining on ISI in Massive MIMO• High Dimensional Robust Inference for Cox Regression Models• Out of the Box: Reasoning with Graph Convolution Nets for Factual Visual Question Answering• Deep Structured Prediction with Nonlinear Output Transformations
Like this:
Like Loading…
Related