A Closer Look at Deep Learning Heuristics: Learning rate restarts, Warmup and Distillation
The convergence rate and final performance of common deep learning models have significantly benefited from heuristics such as learning rate schedules, knowledge distillation, skip connections, and normalization layers. In the absence of theoretical underpinnings, controlled experiments aimed at explaining these strategies can aid our understanding of deep learning landscapes and the training dynamics. Existing approaches for empirical analysis rely on tools of linear interpolation and visualizations with dimensionality reduction, each with their limitations. Instead, we revisit such analysis of heuristics through the lens of recently proposed methods for loss surface and representation analysis, viz., mode connectivity and canonical correlation analysis (CCA), and hypothesize reasons for the success of the heuristics. In particular, we explore knowledge distillation and learning rate heuristics of (cosine) restarts and warmup using mode connectivity and CCA. Our empirical analysis suggests that: (a) the reasons often quoted for the success of cosine annealing are not evidenced in practice; (b) that the effect of learning rate warmup is to prevent the deeper layers from creating training instability; and (c) that the latent knowledge shared by the teacher is primarily disbursed to the deeper layers.
JavaScript Convolutional Neural Networks for Keyword Spotting in the Browser: An Experimental Analysis
Used for simple commands recognition on devices from smart routers to mobile phones, keyword spotting systems are everywhere. Ubiquitous as well are web applications, which have grown in popularity and complexity over the last decade with significant improvements in usability under cross-platform conditions. However, despite their obvious advantage in natural language interaction, voice-enabled web applications are still far and few between. In this work, we attempt to bridge this gap by bringing keyword spotting capabilities directly into the browser. To our knowledge, we are the first to demonstrate a fully-functional implementation of convolutional neural networks in pure JavaScript that runs in any standards-compliant browser. We also apply network slimming, a model compression technique, to explore the accuracy-efficiency tradeoffs, reporting latency measurements on a range of devices and software. Overall, our robust, cross-device implementation for keyword spotting realizes a new paradigm for serving neural network applications, and one of our slim models reduces latency by 66% with a minimal decrease in accuracy of 4% from 94% to 90%.
Multimodal matching using a Hybrid Convolutional Neural Network
In this work we propose a novel Convolutional Neural Network (CNN) architecture for the matching of pairs of image patches acquired by different sensors. Our approach utilizes two CNN sub-networks, where the first is a Siamese CNN and the second is a subnetwork consisting of dual non-weight-sharing CNNs. This allows simultaneous joint and disjoint processing of the input pair of multimodal image patches. The convergence of the training and the test accuracy is improved by introducing auxiliary losses, and a corresponding hard negative mining scheme. The proposed approach is experimentally shown to compare favorably with contemporary state-of-the-art schemes when applied to multiple datasets of multimodal images. The code implementing the proposed scheme was made publicly available.
An Online-Learning Approach to Inverse Optimization
In this paper, we demonstrate how to learn the objective function of a decision-maker while only observing the problem input data and the decision-maker’s corresponding decisions over multiple rounds. Our approach is based on online learning and works for linear objectives over arbitrary feasible sets for which we have a linear optimization oracle. As such, it generalizes previous approaches based on KKT-system decomposition and dualization. The two exact algorithms we present — based on multiplicative weights updates and online gradient descent respectively — converge at a rate of O(1/sqrt(T)) and thus allow taking decisions which are essentially as good as those of the observed decision-maker already after relatively few observations. We also discuss several useful generalizations, such as the approximate learning of non-linear objective functions and the case of suboptimal observations. Finally, we show the effectiveness and possible applications of our methods in a broad computational study.
BCL: A Cross-Platform Distributed Container Library
One-sided communication is a useful paradigm for irregular parallel applications, but most one-sided programming environments, including MPI’s one-sided interface and PGAS programming languages, lack application level libraries to support these applications. We present the Berkeley Container Library, a set of generic, cross-platform, high-performance data structures for irregular applications, including queues, hash tables, Bloom filters and more. BCL is written in C++ using an internal DSL called the BCL Core that provides one-sided communication primitives such as remote get and remote put operations. The BCL Core has backends for MPI, OpenSHMEM, GASNet-EX, and UPC++, allowing BCL data structures to be used natively in programs written using any of these programming environments. Along with our internal DSL, we present the BCL ObjectContainer abstraction, which allows BCL data structures to transparently serialize complex data types while maintaining efficiency for primitive types. We also introduce the set of BCL data structures and evaluate their performance across a number of high-performance computing systems, demonstrating that BCL programs are competitive with hand-optimized code, even while hiding many of the underlying details of message aggregation, serialization, and synchronization.
Birds of a Feather Flock Together? A Study of Developers’ Flocking and Migration Behavior in GitHub and Stack Overflow
Interactions between individuals and their participation in community activities are governed by how individuals identify themselves with their peers. We want to investigate such behavior for developers while they are learning and contributing on socially collaborative environments, specifically code hosting sites and question/answer sites. In this study, we investigate the following questions about advocates, developers who can be identified as well-rounded community contributors and active learners. Do advocates flock together in a community? How do flocks of advocates migrate within a community? Do these flocks of advocates migrate beyond a single community? To understand such behavior, we collected 12,578 common advocates across a code hosting site – GitHub and a question/answering site – Stack Overflow. These advocates were involved in 1,549 projects on GitHub and were actively asking 114,569 questions and responding 408,858 answers and 1,001,125 comments on Stack Overflow. We performed an in-depth empirical analysis using social networks to find the flocks of advocates and their migratory pattern on GitHub, Stack Overflow, and across both communities. We found that 7.5% of the advocates create flocks on GitHub and 8.7% on Stack Overflow. Further, these flocks of advocates migrate on an average of 5 times on GitHub and 2 times on Stack Overflow. In particular, advocates in flocks of two migrate more frequently than larger flocks. However, this migration behavior was only common within a single community. Our findings indicate that advocates’ flocking and migration behavior differs substantially from the ones found in other social environments. This suggests a need to investigate the factors that demotivate the flocking and migration behavior of advocates and ways to enhance and integrate support for such behavior in collaborative software tools.
A framework for automated anomaly detection in high frequency water-quality data from in situ sensors
River water-quality monitoring is increasingly conducted using automated in situ sensors, enabling timelier identification of unexpected values. However, anomalies caused by technical issues confound these data, while the volume and velocity of data prevent manual detection. We present a framework for automated anomaly detection in high-frequency water-quality data from in situ sensors, using turbidity, conductivity and river level data. After identifying end-user needs and defining anomalies, we ranked their importance and selected suitable detection methods. High priority anomalies included sudden isolated spikes and level shifts, most of which were classified correctly by regression-based methods such as autoregressive integrated moving average models. However, using other water-quality variables as covariates reduced performance due to complex relationships among variables. Classification of drift and periods of anomalously low or high variability improved when we applied replaced anomalous measurements with forecasts, but this inflated false positive rates. Feature-based methods also performed well on high priority anomalies, but were also less proficient at detecting lower priority anomalies, resulting in high false negative rates. Unlike regression-based methods, all feature-based methods produced low false positive rates, but did not and require training or optimization. Rule-based methods successfully detected impossible values and missing observations. Thus, we recommend using a combination of methods to improve anomaly detection performance, whilst minimizing false detection rates. Furthermore, our framework emphasizes the importance of communication between end-users and analysts for optimal outcomes with respect to both detection performance and end-user needs. Our framework is applicable to other types of high frequency time-series data and anomaly detection applications.
DBSCAN++: Towards fast and scalable density clustering
DBSCAN is a classical density-based clustering procedure which has had tremendous practical relevance. However, it implicitly needs to compute the empirical density for each sample point, leading to a quadratic worst-case time complexity, which may be too slow on large datasets. We propose DBSCAN++, a simple modification of DBSCAN which only requires computing the densities for a subset of the points. We show empirically that, compared to traditional DBSCAN, DBSCAN++ can provide not only competitive performance but also added robustness in the bandwidth hyperparameter while taking a fraction of the runtime. We also present statistical consistency guarantees showing the trade-off between computational cost and estimation rates. Surprisingly, up to a certain point, we can enjoy the same estimation rates while lowering computational cost, showing that DBSCAN++ is a sub-quadratic algorithm that attains minimax optimal rates for level-set estimation, a quality that may be of independent interest.
SplineNets: Continuous Neural Decision Graphs
We present SplineNets, a practical and novel approach for using conditioning in convolutional neural networks (CNNs). SplineNets are continuous generalizations of neural decision graphs, and they can dramatically reduce runtime complexity and computation costs of CNNs, while maintaining or even increasing accuracy. Functions of SplineNets are both dynamic (i.e., conditioned on the input) and hierarchical (i.e., conditioned on the computational path). SplineNets employ a unified loss function with a desired level of smoothness over both the network and decision parameters, while allowing for sparse activation of a subset of nodes for individual samples. In particular, we embed infinitely many function weights (e.g. filters) on smooth, low dimensional manifolds parameterized by compact B-splines, which are indexed by a position parameter. Instead of sampling from a categorical distribution to pick a branch, samples choose a continuous position to pick a function weight. We further show that by maximizing the mutual information between spline positions and class labels, the network can be optimally utilized and specialized for classification tasks. Experiments show that our approach can significantly increase the accuracy of ResNets with negligible cost in speed, matching the precision of a 110 level ResNet with a 32 level SplineNet.
Structure Learning of Deep Neural Networks with Q-Learning
Recently, with convolutional neural networks gaining significant achievements in many challenging machine learning fields, hand-crafted neural networks no longer satisfy our requirements as designing a network will cost a lot, and automatically generating architectures has attracted increasingly more attention and focus. Some research on auto-generated networks has achieved promising results. However, they mainly aim at picking a series of single layers such as convolution or pooling layers one by one. There are many elegant and creative designs in the carefully hand-crafted neural networks, such as Inception-block in GoogLeNet, residual block in residual network and dense block in dense convolutional network. Based on reinforcement learning and taking advantages of the superiority of these networks, we propose a novel automatic process to design a multi-block neural network, whose architecture contains multiple types of blocks mentioned above, with the purpose to do structure learning of deep neural networks and explore the possibility whether different blocks can be composed together to form a well-behaved neural network. The optimal network is created by the Q-learning agent who is trained to sequentially pick different types of blocks. To verify the validity of our proposed method, we use the auto-generated multi-block neural network to conduct experiments on image benchmark datasets MNIST, SVHN and CIFAR-10 image classification task with restricted computational resources. The results demonstrate that our method is very effective, achieving comparable or better performance than hand-crafted networks and advanced auto-generated neural networks.
Machine Learning Estimation of Heterogeneous Causal Effects: Empirical Monte Carlo Evidence
We investigate the finite sample performance of causal machine learning estimators for heterogeneous causal effects at different aggregation levels. We employ an Empirical Monte Carlo Study that relies on arguably realistic data generation processes (DGPs) based on actual data. We consider 24 different DGPs, eleven different causal machine learning estimators, and three aggregation levels of the estimated effects. In the main DGPs, we allow for selection into treatment based on a rich set of observable covariates. We provide evidence that the estimators can be categorized into three groups. The first group performs consistently well across all DGPs and aggregation levels. These estimators have multiple steps to account for the selection into the treatment and the outcome process. The second group shows competitive performance only for particular DGPs. The third group is clearly outperformed by the other estimators.
An Information-Theoretic Framework for Non-linear Canonical Correlation Analysis
Canonical Correlation Analysis (CCA) is a linear representation learning method that seeks maximally correlated variables in multi-view data. Non-linear CCA extends this notion to a broader family of transformations, which are more powerful for many real-world applications. Given the joint probability, the Alternating Conditional Expectation (ACE) provides an optimal solution to the non-linear CCA problem. However, it suffers from limited performance and an increasing computational burden when only a finite number of observations is available. In this work we introduce an information-theoretic framework for the non-linear CCA problem (ITCCA), which extends the classical ACE approach. Our suggested framework seeks compressed representations of the data that allow a maximal level of correlation. This way we control the trade-off between the flexibility and the complexity of the representation. Our approach demonstrates favorable performance at a reduced computational burden, compared to non-linear alternatives, in a finite sample size regime. Further, ITCCA provides theoretical bounds and optimality conditions, as we establish fundamental connections to rate-distortion theory, the information bottleneck and remote source coding. In addition, it implies a ‘soft’ dimensionality reduction, as the compression level is measured (and governed) by the mutual information between the original noisy data and the signals that we extract.
Consistency-based anomaly detection with adaptive multiple-hypotheses predictions
In out-of-distribution classification tasks, only some classes – the normal cases – can be modeled with data, whereas the variation of all possible anomalies is too large to be described sufficiently by samples. Thus, the wide-spread discriminative approaches cannot cover such learning tasks and rather generative models, which attempt to learn the input density of the ordinary cases, are used. However, generative models suffer under a large input dimensionality (as in images) and are typically inefficient learners. Motivated by the Local-Outlier-Factor (LOF) method, in this work, we propose to allow the network to directly estimate the local density functions since, for the detection of outliers, the local neighborhood is more important than the global one. At the same time, we retain consistency in the sense that the model must not support areas of the input space that are not covered by samples. Our method allows the model to identify out-of-distribution samples reliably. For the anomaly detection task on CIFAR-10, our ConAD model results in up to 5% points improvement over previously reported results.
On Exploration, Exploitation and Learning in Adaptive Importance Sampling


Taking Human out of Learning Applications: A Survey on Automated Machine Learning
Machine learning techniques have deeply rooted in our everyday life. However, since it is knowledge- and labor-intensive to pursuit good learning performance, human experts are heavily engaged in every aspect of machine learning. In order to make machine learning techniques easier to apply and reduce the demand for experienced human experts, automatic machine learning~(AutoML) has emerged as a hot topic of both in industry and academy. In this paper, we provide a survey on existing AutoML works. First, we introduce and define the AutoML problem, with inspiration from both realms of automation and machine learning. Then, we propose a general AutoML framework that not only covers almost all existing approaches but also guides the design for new methods. Afterward, we categorize and review the existing works from two aspects, i.e., the problem setup and the employed techniques. Finally, we provide a detailed analysis of AutoML approaches and explain the reasons underneath their successful applications. We hope this survey can serve as not only an insightful guideline for AutoML beginners but also an inspiration for future researches.
Contrastive Multivariate Singular Spectrum Analysis
We introduce Contrastive Multivariate Singular Spectrum Analysis, a novel unsupervised method for dimensionality reduction and signal decomposition of time series data. By utilizing an appropriate background dataset, the method transforms a target time series dataset in a way that evinces the sub-signals that are enhanced in the target dataset, as opposed to only those that account for the greatest variance. This shifts the goal from finding signals that explain the most variance to signals that matter the most to the analyst. We demonstrate our method on an illustrative synthetic example, as well as show the utility of our method in the downstream clustering of electrocardiogram signals from the public MHEALTH dataset.
Convolutional Self-Attention Network
Self-attention network (SAN) has recently attracted increasing interest due to its fully parallelized computation and flexibility in modeling dependencies. It can be further enhanced with multi-headed attention mechanism by allowing the model to jointly attend to information from different representation subspaces at different positions (Vaswani et al., 2017). In this work, we propose a novel convolutional self-attention network (CSAN), which offers SAN the abilities to 1) capture neighboring dependencies, and 2) model the interaction between multiple attention heads. Experimental results on WMT14 English-to-German translation task demonstrate that the proposed approach outperforms both the strong Transformer baseline and other existing works on enhancing the locality of SAN. Comparing with previous work, our model does not introduce any new parameters.
Boosting for Comparison-Based Learning

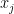
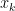
Learning to Represent Edits
We introduce the problem of learning distributed representations of edits. By combining a ‘neural editor’ with an ‘edit encoder’, our models learn to represent the salient information of an edit and can be used to apply edits to new inputs. We experiment on natural language and source code edit data. Our evaluation yields promising results that suggest that our neural network models learn to capture the structure and semantics of edits. We hope that this interesting task and data source will inspire other researchers to work further on this problem.
Matching Graphs with Community Structure: A Concentration of Measure Approach
In this paper, matching pairs of random graphs under the community structure model is considered. The problem emerges naturally in various applications such as privacy, image processing and DNA sequencing. A pair of randomly generated labeled graphs with pairwise correlated edges are considered. It is assumed that the graph edges are generated based on the community structure model. Given the labeling of the edges of the first graph, the objective is to recover the labels in the second graph. The problem is considered under two scenarios: i) with side-information where the community membership of the nodes in both graphs are known, and ii) without side-information where the community memberships are not known. A matching scheme is proposed which operates based on typicality of the adjacency matrices of the graphs. Achievability results are derived which provide theoretical guarantees for successful matching under specific assumptions on graph parameters. It is observed that for the proposed matching scheme, the conditions for successful matching do not change in the presence of side-information. Furthermore, a converse result is derived which characterizes a set of graph parameters for which matching is not possible.
Analyzing biological and artificial neural networks: challenges with opportunities for synergy?
Deep neural networks (DNNs) transform stimuli across multiple processing stages to produce representations that can be used to solve complex tasks, such as object recognition in images. However, a full understanding of how they achieve this remains elusive. The complexity of biological neural networks substantially exceeds the complexity of DNNs, making it even more challenging to understand the representations that they learn. Thus, both machine learning and computational neuroscience are faced with a shared challenge: how can we analyze their representations in order to understand how they solve complex tasks? We review how data-analysis concepts and techniques developed by computational neuroscientists can be useful for analyzing representations in DNNs, and in turn, how recently developed techniques for analysis of DNNs can be useful for understanding representations in biological neural networks. We explore opportunities for synergy between the two fields, such as the use of DNNs as in-silico model systems for neuroscience, and how this synergy can lead to new hypotheses about the operating principles of biological neural networks.
A Stochastic Penalty Model for Convex and Nonconvex Optimization with Big Constraints
The last decade witnessed a rise in the importance of supervised learning applications involving {\em big data} and {\em big models}. Big data refers to situations where the amounts of training data available and needed causes difficulties in the training phase of the pipeline. Big model refers to situations where large dimensional and over-parameterized models are needed for the application at hand. Both of these phenomena lead to a dramatic increase in research activity aimed at taming the issues via the design of new sophisticated optimization algorithms. In this paper we turn attention to the {\em big constraints} scenario and argue that elaborate machine learning systems of the future will necessarily need to account for a large number of real-world constraints, which will need to be incorporated in the training process. This line of work is largely unexplored, and provides ample opportunities for future work and applications. To handle the {\em big constraints} regime, we propose a {\em stochastic penalty} formulation which {\em reduces the problem to the well understood big data regime}. Our formulation has many interesting properties which relate it to the original problem in various ways, with mathematical guarantees. We give a number of results specialized to nonconvex loss functions, smooth convex functions, strongly convex functions and convex constraints. We show through experiments that our approach can beat competing approaches by several orders of magnitude when a medium accuracy solution is required.
MaSS: an Accelerated Stochastic Method for Over-parametrized Learning
In this paper we introduce MaSS (Momentum-added Stochastic Solver), an accelerated SGD method for optimizing over-parameterized networks. Our method is simple and efficient to implement and does not require changing parameters or computing full gradients in the course of optimization. We provide a detailed theoretical analysis for convergence and parameter selection including their dependence on the mini-batch size in the quadratic case. We also provide theoretical convergence results for a more general convex setting. We provide an experimental evaluation showing strong performance of our method in comparison to Adam and SGD for several standard architectures of deep networks including ResNet, convolutional and fully connected networks. We also show its performance for convex kernel machines.
You May Not Need Attention
In NMT, how far can we get without attention and without separate encoding and decoding? To answer that question, we introduce a recurrent neural translation model that does not use attention and does not have a separate encoder and decoder. Our eager translation model is low-latency, writing target tokens as soon as it reads the first source token, and uses constant memory during decoding. It performs on par with the standard attention-based model of Bahdanau et al. (2014), and better on long sentences.
Understand Deep Neural Networks through Input Uncertainties
Techniques for understanding the functioning of complex machine learning models are becoming increasingly popular, not only to improve the validation process, but also to extract new insights about the data via exploratory analysis. Though a large class of such tools currently exists, most assume that predictions are point estimates and use a sensitivity analysis of these estimates to interpret the model. Using lightweight probabilistic networks we show how including prediction uncertainties in the sensitivity analysis leads to: (i) more robust and generalizable models; and (ii) a new approach for model interpretation through uncertainty decomposition. In particular, we introduce a new regularization that takes both the mean and variance of a prediction into account and demonstrate that the resulting networks provide improved generalization to unseen data. Furthermore, we propose a new technique to explain prediction uncertainties through uncertainties in the input domain, thus providing new ways to validate and interpret deep learning models.
Unsupervised Dimension Selection using a Blue Noise Spectrum
Clustering-Enhanced Stochastic Gradient MCMC for Hidden Markov Models with Rare States
MCMC algorithms for hidden Markov models, which often rely on the forward-backward sampler, suffer with large sample size due to the temporal dependence inherent in the data. Recently, a number of approaches have been developed for posterior inference which make use of the mixing of the hidden Markov process to approximate the full posterior by using small chunks of the data. However, in the presence of imbalanced data resulting from rare latent states, the proposed minibatch estimates will often exclude rare state data resulting in poor inference of the associated emission parameters and inaccurate prediction or detection of rare events. Here, we propose to use a preliminary clustering to over-sample the rare clusters and reduce variance in gradient estimation within Stochastic Gradient MCMC. We demonstrate very substantial gains in predictive and inferential accuracy on real and synthetic examples.
Making root cause analysis feasible for large code bases: a solution approach for a climate model
Structured Parallel Programming Language Based on True Concurrency
Based on our previous work on algebraic laws for true concurrency, we design a skeleton of structured parallel programming language for true concurrency called SPPLTC. Different to most programming languages, SPPLTC has an explicit parallel operator as an essential operator. SPPLTC can structure a truly concurrent graph to a normal form. This means that it is possible to implement a compiler for SPPLTC.
• A comparison of encodings for cardinality constraints in a SAT solver• Modified Macdonald polynomials and integrability• Secure Communication over Interference Channel: To Jam or Not to Jam?• DeepHTTP: Semantics-Structure Model with Attention for Anomalous HTTP Traffic Detection and Pattern Mining• Estimation of Static and Dynamic Urban Populations with Mobile Network Metadata• Application of Deep Learning on Predicting Prognosis of Acute Myeloid Leukemia with Cytogenetics, Age, and Mutations• Exact Channel Synthesis• Stochastic Optimal Control of Epidemic Processes in Networks• Accelerating the Convergence Rates of Distributed Subgradient Methods with Adaptive Quantization• MPNA: A Massively-Parallel Neural Array Accelerator with Dataflow Optimization for Convolutional Neural Networks• Transport, multifractality, and the breakdown of single-parameter scaling at the localization transition in quasiperiodic systems• NPRF: A Neural Pseudo Relevance Feedback Framework for Ad-hoc Information Retrieval• Robust Stabilization of Nonlinear Systems Using Periodic Event-triggered Control• Classical and Generalized Solutions of Fractional Stochastic Differential Equations• Manifold Learning for Bifurcation Diagram Observations• Improving Distant Supervision with Maxpooled Attention and Sentence-Level Supervision• SDFN: Segmentation-based Deep Fusion Network for Thoracic Disease Classification in Chest X-ray Images• Effect of shortest path multiplicity on congestion of multiplex networks• Improved Bounds for Randomly Sampling Colorings via Linear Programming• Weighted vertex cover on graphs with maximum degree 3• Sleeping Multi-Armed Bandit Learning for Fast Uplink Grant Allocation in Machine Type Communications• R$^3$SGM: Real-time Raster-Respecting Semi-Global Matching for Power-Constrained Systems• Power Factor Correction of Inductive Loads using PLC• Number of orbits of Discrete Interval Exchanges• Rate-Efficiency and Straggler-Robustness through Partition in Distributed Two-Sided Secure Matrix Computation• New analysis of the free energy cost of interfaces in spin glasses• Mathematical modelling European temperature data: spatial differences in global warming• New complexity bounds in stochastic games• Bi-Directional Lattice Recurrent Neural Networks for Confidence Estimation• Confidence Estimation and Deletion Prediction Using Bidirectional Recurrent Neural Networks• Stress-Testing Neural Models of Natural Language Inference with Multiply-Quantified Sentences• Theory for Inverse Stochastic Resonance in Nature• Scalable Laplacian K-modes• Attentive Filtering Networks for Audio Replay Attack Detection• Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation• User Constrained Thumbnail Generation using Adaptive Convolutions• Visual Attention Network for Low Dose CT• Connecting the Dots: Identifying Network Structure via Graph Signal Processing• Symbiotic Radio: A New Communication Paradigm for Passive Internet-of-Things• Dynamic Assortment Optimization with Changing Contextual Information• Formal Verification of Neural Network Controlled Autonomous Systems• Physics Guided RNNs for Modeling Dynamical Systems: A Case Study in Simulating Lake Temperature Profiles• Lagrangian densities of hypergraph cycles• A Large-scale Study of Social Media Sources in News Articles• GraphIE: A Graph-Based Framework for Information Extraction• Provably Accelerated Randomized Gossip Algorithms• Multirobot Coordination with Counting Temporal Logics• Attention-based sequence-to-sequence model for speech recognition: development of state-of-the-art system on LibriSpeech and its application to non-native English• Towards End-to-End Code-Switching Speech Recognition• Sample size considerations for comparing dynamic treatment regimens in a sequential multiple-assignment randomized trial with a continuous longitudinal outcome• Attentive Neural Network for Named Entity Recognition in Vietnamese• Low-Rank Embedding of Kernels in Convolutional Neural Networks under Random Shuffling• Splitting with Near-Circulant Linear Systems: Applications to Total Variation CT and PET• Query Adaptive Late Fusion for Image Retrieval• Weak Label Supervision For Monaural Source Separation Using Non-negative Denoising Variational Autoencoders• End-to-End Feedback Loss in Speech Chain Framework via Straight-Through Estimator• A general system of differential equations to model first order adaptive algorithms• Enhanced Quasi-Maximum Likelihood Decoding of Short LDPC Codes based on Saturation• Real-time Automatic Word Segmentation for User-generated Text• Matching Game Based Framework for Two-Timescale Cooperative D2D Communication• A Pontryagin Maximum Principle in Wasserstein Spaces for Constrained Optimal Control Problems• Compact Generalized Non-local Network• The Effect of Learning Strategy versus Inherent Architecture Properties on the Ability of Convolutional Neural Networks to Develop Transformation Invariance• Adaptive Extreme Learning Machine for Recurrent Beta-basis Function Neural Network Training• Introducing SPAIN (SParse Audion INpainter)• Towards a more efficient use of process and product traceability data for continuous improvement of industrial performances• SIEVE: Helping Developers Sift Wheat from Chaff via Cross-Platform Analysis• The density of states of 1D random band matrices via a supersymmetric transfer operator• Borel summation of the small time expansion of SDE’s driven by Gaussian white noise• Sects• Fully-Connected vs. Sub-Connected Hybrid Precoding Architectures for mmWave MU-MIMO• A tutorial on MDL hypothesis testing for graph analysis• Markovian dynamics of exchangeable arrays• Don’t forget, there is more than forgetting: new metrics for Continual Learning• Inception-Residual Block based Neural Network for Thermal Image Denoising• Face Presentation Attack Detection in Learned Color-liked Space• How to Databasify a Blockchain: the Case of Hyperledger Fabric• Asymptotic Analysis of Regular Sequences• Molecular dynamics simulation of the capillary leveling of a glass-forming liquid• WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community• Randomized Work Stealing versus Sharing in Large-scale Systems with Non-exponential Job Sizes• Non-Empty Bins with Simple Tabulation Hashing• Multi-Layers Supply chain modelling based on Multi-Agent Approach• Infrastructure for the representation and electronic exchange of design knowledge• Nearly-tight bounds on linear regions of piecewise linear neural networks• A Decision Support Framework for Manufacturing Improvement and Relocation Prevention in Thailand: Supply Chain Perspective• A multi-agent system for managing the product lifecycle sustainability• The Many Moods of Emotion• Volterra chain and Catalan numbers• Compressive Single-pixel Fourier Transform Imaging using Structured Illumination• Design and Qualification of an Airborne, Cosmic Ray Flux Measurement System• Multi-Task Learning for Left Atrial Segmentation on GE-MRI• SURFACE: Semantically Rich Fact Validation with Explanations• Methods for Segmentation and Classification of Digital Microscopy Tissue Images• Stanley character formula for the spin characters of the symmetric groups• On Fast Leverage Score Sampling and Optimal Learning• Geographic Dependence of the Solar Radiation Spectrum at Intermediate to High Frequencies• Ionospheric activity prediction using convolutional recurrent neural networks• Influence of the seed in affine preferential attachment trees• On the Calculation of Differential Parametrizations for the Feedforward Control of an Euler-Bernoulli Beam• The Medico-Task 2018: Disease Detection in the Gastrointestinal Tract using Global Features and Deep Learning• Multilevel Planarity• On Weakly Distinguishing Graph Polynomials• SUNet: a deep learning architecture for acute stroke lesion segmentation and outcome prediction in multimodal MRI• Hamilton cycles in Cayley graphs on generalized dihedral groups• Crowdsourcing with Fairness, Diversity and Budget Constraints• A General Framework for Multivariate Functional Principal Component Analysis of Amplitude and Phase Variation• A stochastic computing architecture for iterative estimation• A Concurrent Unbounded Wait-Free Graph• Cross-lingual Transfer Learning for Multilingual Task Oriented Dialog• Convolutional Neural Network Quantization using Generalized Gamma Distribution• A Two Query Adaptive Bitprobe Scheme Storing Five Elements• MULAN: A Blind and Off-Grid Method for Multichannel Echo Retrieval• Multimodal Machine Learning for Automated ICD Coding• Stochastic Submodular Cover with Limited Adaptivity• Privacy Preserving Multi-Agent Planning with Provable Guarantees• Irreducibility of random polynomials of large degree• The UMD property for Musielak–Orlicz spaces• On the Lehmer conjecture and counting in finite fields• Winding of a Brownian particle around a point vortex• Best Nonnegative Rank-One Approximations of Tensors• Performance assessment of the deep learning technologies in grading glaucoma severity• PDE-constrained optimal control problems with uncertain parameters using SAGA• Picking Apart Story Salads• Differentiable MPC for End-to-end Planning and Control• Bounding bias due to selection• Unsupervised Identification of Disease Marker Candidates in Retinal OCT Imaging Data• On The Inductive Bias of Words in Acoustics-to-Word Models• Extracting Linguistic Resources from the Web for Concept-to-Text Generation• Multiple Measurement Vectors Problem: A Decoupling Property and its Applications• Improving Machine Reading Comprehension with General Reading Strategies• The inverse Born problem in contextual probability theories: quantum spin and continuous random variables• Model parameter estimation using coherent structure coloring
Like this:
Like Loading…
Related