By Emma Grimaldi, Data Scientist and Mechanical Engineer

Natural Language Processing is for me one of the most captivating fields of data science. The fact that a machine can understand the content of a text with a certain accuracy is just fascinating, and sometimes scary.
The applications of NLP are endless. This is how a machine classifies whether an email is spam or not, if a review is positive or negative, and how a search engine recognizes what type of person you are based on the content of your query to customize the response accordingly.
But how does that work in practice? This post introduces the concepts at the base of Natural Language Processing, and focuses on the nltk package to use in Python.
Note: to run the examples below, you will need to have
nltklibrary installed. If you don’t have it, just runpip install nltkin your shell andnltk.download()in your notebook before starting.
Whatever text or sentence is fed to a machine, it will need to be simplified first, and this can be done through tokenization and lemmatization. These complicated words mean something really easy: tokenization means that we break down the text into tokens, single or grouped words depending on the case. Lemmatization means that we transform some of the words into their root word, i.e. plural words become singular, conjugated verbs become base verbs and so on. Between these manipulations, we also clean the text from all the words that don’t carry actual information, the so-called stop words.
Let’s have a look at the sentence below to understand what all this means with an example.
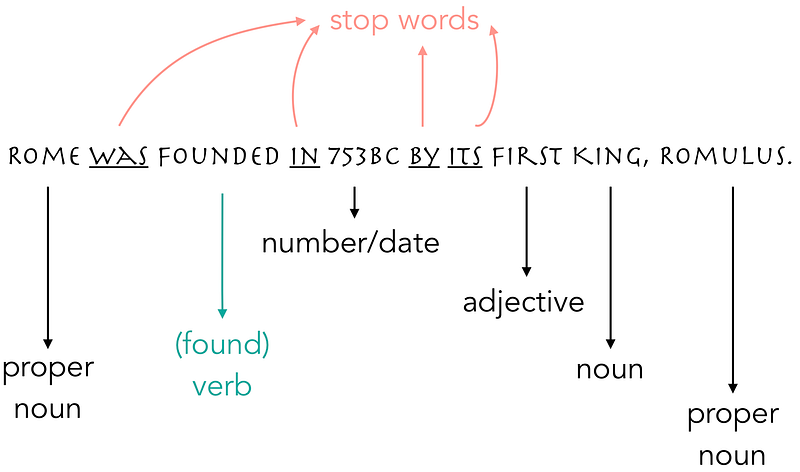 Example of tokenization and lemmatization for ngrams = 1.
Example of tokenization and lemmatization for ngrams = 1.
When tokenizing a text, it is important to choose the ngram accordingly. It is the number that specifies how many words we want in each token, and in most cases (like the example above), this number is equal to 1. But if you are running a sentiment analysis on a business review website, possibly your texts might contain statements like “not happy” or “did not like’” and you don’t want these words to cancel out each other, in order to convey the negative sentiment behind the review. In cases like that, you might want to consider to increase the ngram and see how it impacts your analysis.
There are also other things to consider when tokenizing, for example, the punctuation. Most of the times you want to get rid of any punctuation because it does not contain any information, unless there are meaningful numbers in the text. In such case, you might want to consider keeping the punctuation or the numbers included in the text will be split wherever a . or , is present.
In the code shown below I used RegexpTokenizer, a Regular Expression Tokenizer. For those who are not familiar with regex, in formal language theory it is a sequence of characters that defines a pattern, and depending on the argument that you pass in the RegexpTokenizer function, it will split the text according to that argument. In a regex expression, \w+ literally means to group all the word characters of length greater than or equal to one, discarding empty spaces (and hence tokenizing single words) and all the non-word characters, i.e. punctuation.
Tokenizing with RegexpTokenizer.
The tokens’ list resulting from this piece of code is:
Not bad for a start, we have our tokens made by single words and the punctuation is gone! Now we have to eliminate the stop words from the tokens: luckily a list of stop words is included in nltk, for many different languages. But of course, depending on the single case, you might need to customize this list of words. For example, the article the is included in such list by default but if you are analyzing a movie or music database, you might want to keep it because, in that case, it does make a difference (fun fact: The Helpand Help! are two different movies!).
Discarding the stop words from a text.
The new tokens list is:
We went from 10 to 6 words and now it’s finally time to lemmatize! So far I have tested two objects with this same purpose: WordNetLemmatizer and PorterStemmer and the latter is definitely more brutal than the former, as shown in the examples below.
Lemmatization example with WordNetLemmatizer.
The output of the last list comprehension is:
Nothing changed! This is because WordNetLemmatizer only acts on plural words and a few other things, and in this particular case no word was actually lemmatized. On the other handPorterStemmer transforms plural and derived words, conjugated verbs and makes all the terms lower case as shown below:
Lemmatization example with PorterStemmer.
The output of the list comprehension is:
In this case there are no upper case words anymore, and this is okay for us because it makes no sense to differentiate same words just because one is lower case and the other one is not, they have the same meaning! The verb founded has been changed to found and even Romulus lost the last letter of his name, probably because PorterStemmer thought it was a plural word.
These lemmatization functions are very different and depending on the case, one will be more appropriate than the other one.
There are many, many different methods to gather and organize words from a text before modeling them, and these were just a small portion of the available options. All this cleaning is necessary before feeding the text into a machine learning model to simplify it as much as possible. When you analyze a large amount of words in predictive models, after the above steps are done, you will most likely rely on sklearn methods such as CountVectorizer, TfidfVectorizer or HashingVectorizer to convert the raw text into a matrix of token counts to train your predictive model.
Bio: Emma Grimaldi is a Data Scientist and Mechanical Engineer. She combines her mechanical engineering mindset and her passion for numbers in building models to extract hidden truths from every day and mundane looking data.
Original. Reposted with permission.
Related: