Introduction
Now that we’ve seen MCHT basics, how to make MCHTest() objects self-contained, and maximized Monte Carlo (MMC) testing with MCHT, let’s now talk about bootstrap testing. Not much is different when we’re doing bootstrap testing; the main difference is that the replicates used to generate test statistics depend on the data we feed to the test, and thus are not completely independent of it. You can read more about bootstrap testing in [1].
Bootstrap Hypothesis Testing
Let 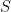
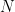

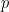

Here, 
There are many ways to generate the data used to compute 
MCHTest() supports both.
Unlike Monte Carlo tests, bootstrap tests cannot claim to be exact tests for any sample size; they’re better for larger sample sizes. That said, they often work well even in small sample sizes and thus are still a good alternative to inference based on asymptotic results. They also could serve as an alternative approach to the nuisance parameter problem, as MMC often has weak power.
Bootstrap Testing in MCHT
In MCHT, there is little difference between bootstrap testing and Monte Carlo testing. Bootstrap tests need the original dataset to generate replicates; Monte Carlo tests do not. So the difference here is that the function passed to rand_gen needs to accept a parameter x rather than n, with x representing the original dataset, like that passed to test_stat.
That’s the only difference. All else is the same.
Nonparametric Bootstrap Example
Suppose we wish to test for the location of the mean. Our nonparametric bootstrap procedure is as follows:
Generate 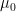

The code below implements this procedure.
Parametric Bootstrap Test
The parametric bootstrap test assumes that the observed data was generated using a specific distribution, such as the Gaussian distribution. All that’s missing, in essence, is the parameters of that distribution. The procedure thust starts by estimating all nuisance parameters of the assumed distribution using the data. Then the first step of the process mentioned above (which admittedly was specific to a test for the mean but still strongly resembles the general process) is replaced with simulating data from the assumed distribution using any parameters assumed under the null hypothesis and the estimated values of any nuisance parameters. The other two steps of the above process are unchanged.
We can use the parametric bootstrap to test for goodness of fit with the Kolmogorov-Smirnov test. Without going into much detail, suppose that 

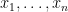


That is, we want to test whether our data was drawn from the distribution
R implements this test in ks.test() but that function does not allow for any nuisance parameters. It will only check for an exact match between distributions. This is often not what we want; we want to check whether out data was drawn from any member of the family of distributions ks.test(). Thus we will need to approach the test differently.
Since the distribution of the data is known under the null hypothesis, this is a good situation to use a bootstrap test. We’ll use maximum likelihood estimation to estimate the values of the missing parameters, as implemented by fitdistrplus (see [2]). Then we generate samples from this distribution using the estimated parameter values and use those samples to generate simulated test statistic values that follow the distribution prescribed by the null hypothesis.
Suppose we wished to test whether the data was drawn from a Weibull distribution. The result is the following test.
Conclusion
Given the choice between a MMC test and a bootstrap test, which should you prefer? If you’re concerned about speed and power, go with the bootstrap test. If you’re concerned about precision and getting an “exact” test that’s at least conservative, then go with a MMC test. I think most of the time, though, the bootstrap test will be good enough, even with small samples, but that’s mostly a hunch.
Next week we will see how we can go beyond one-sample or univariate tests to multi-sample or multivariate tests. See the next blog post.
References
-
J. G. MacKinnon, Bootstrap hypothesis testing in Handbook of computational econometrics (2009) pp. 183-213
-
M. L. Delignette-Muller and C. Dulag, fitdistrplus: an R package for fitting distributions, J. Stat. Soft., vol. 64 no. 4 (2015)
Packt Publishing published a book for me entitled Hands-On Data Analysis with NumPy and Pandas, a book based on my video course Unpacking NumPy and Pandas. This book covers the basics of setting up a Python environment for data analysis with Anaconda, using Jupyter notebooks, and using NumPy and pandas. If you are starting out using Python for data analysis or know someone who is, please consider buying my book or at least spreading the word about it. You can buy the book directly or purchase a subscription to Mapt and read it there.
If you like my blog and would like to support it, spread the word (if not get a copy yourself)!
Related